Hi all,
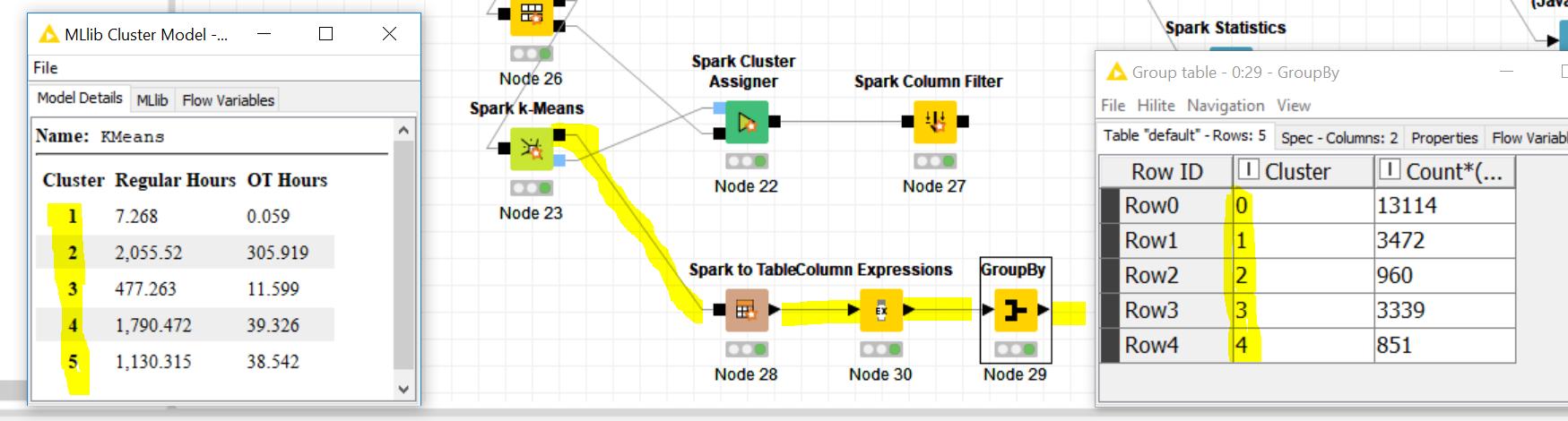
I was creating a k-Means model using the Spark k-Means node. I notice that the cluster numbering is off between the model and the labels applied to the input.
Any idea how to make these numbers consistent?
Aditya
Hi all,
I was creating a k-Means model using the Spark k-Means node. I notice that the cluster numbering is off between the model and the labels applied to the input.
Any idea how to make these numbers consistent?
Aditya
Hi @adityatw17,
the clusters are just named by their index, which starts at 1 in the model view and at 0 in the data view. As a quick workaround you can add plus one to the clusters in data view and they’ll fit to the cluster names in the model view. But still, you’re right saying this is confusing and should be consistent. I’ll report this as a bug an keep you posted as soon as there is a fix available. Thanks for your feedback!
Cheers,
Marten
Excellent. Thank you so much, Marten!
Aditya
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.