I am contacting you because I am experiencing an error when using Pyspark using the “Create Local Big Data Environment” node in my personal PC environment.
After creating a Spark context with the “Create Local Big Data Environment” node, connecting to the Pyspark Script and configuring the Spark Session again, the following error occurs.
“C:\Users.eclipse\903338280_win32_win32_x86_64\plugins\org.knime.bigdata.spark.local_4.7.0.v202211082334\libs\pyspark.zip\pyspark\sql\context.py:125: FutureWarning: Deprecated in 3.0.0. Use SparkSession.builder.getOrCreate() instead.”
I see that SparkSession is deprecated, but I know that SparkSession is a higher version than Spark context. Also, I need to configure Session inside the script to use spark-related code, so it is essential to proceed, but I configure context with “Create Local Big Data Environment”, so I get a double configuration error?
Or is there a problem with the configuration of Create Local Big Data Environment in Local?
What steps should I take to resolve the above error? Your help will be greatly appreciated.
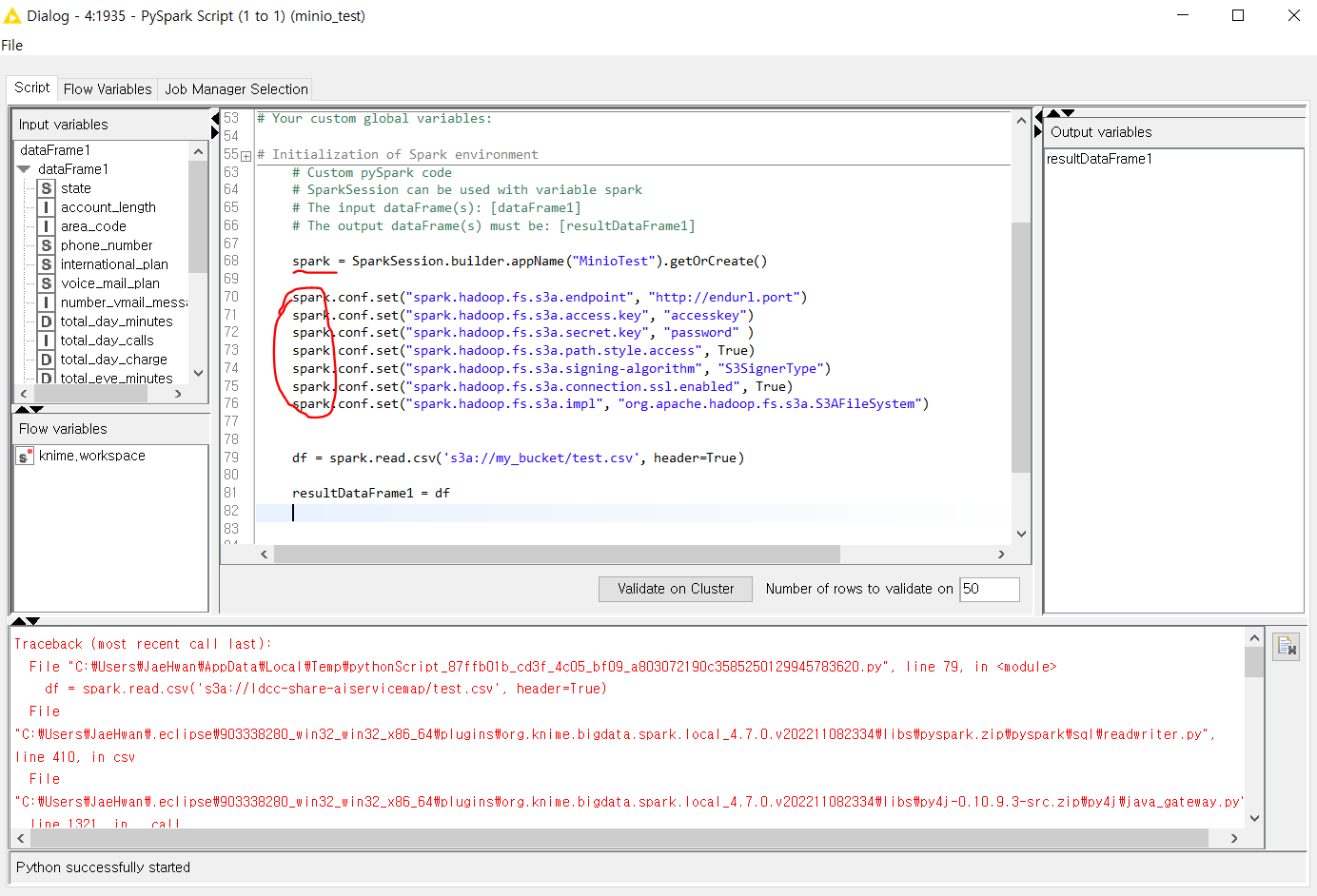
I am currently working on integrating with minIO within a Pyspark Script node.
The above error “Deprecated in 3.0.0. Use SparkSession.builder.getOrCreate() instead” was fixed by modifying the “org.knime.bigdata.spark.local_4.7.0.v” folder inside KNIME, but I got the following error.
Traceback (most recent call last):
File “C:\Users\JaeHwan\AppData\Local\Temp\pythonScript_87ffb01b_cd3f_4c05_bf09_a803072190c3585250129945783620.py”, line 79, in
df = spark.read.csv(‘s3a://my_bucket/test.csv’, header=True)
File “C:\Users\JaeHwan.eclipse\903338280_win32_win32_x86_64\plugins\org.knime.bigdata.spark.local_4.7.0.v202211082334\libs\pyspark.zip\pyspark\sql\readwriter.py”, line 410, in csv
File “C:\Users\JaeHwan.eclipse\903338280_win32_win32_x86_64\plugins\org.knime.bigdata.spark.local_4.7.0.v202211082334\libs\py4j-0.10.9.3-src.zip\py4j\java_gateway.py”, line 1321, in call
File “C:\Users\JaeHwan.eclipse\903338280_win32_win32_x86_64\plugins\org.knime.bigdata.spark.local_4.7.0.v202211082334\libs\pyspark.zip\pyspark\sql\utils.py”, line 111, in deco
File “C:\Users\JaeHwan.eclipse\903338280_win32_win32_x86_64\plugins\org.knime.bigdata.spark.local_4.7.0.v202211082334\libs\py4j-0.10.9.3-src.zip\py4j\protocol.py”, line 326, in get_return_value
py4j.protocol.Py4JJavaError: An error occurred while calling o56.csv.
: java.lang.NoSuchMethodError: com.amazonaws.services.s3.transfer.TransferManager.(Lcom/amazonaws/services/s3/AmazonS3;Ljava/util/concurrent/ThreadPoolExecutor;)V
Crucially, when I run the same code through the Pyspark module in the Jupyter notebook, it successfully connects to minIO, but when I import it into the Pyspark Script in KNIME, I still get the error.
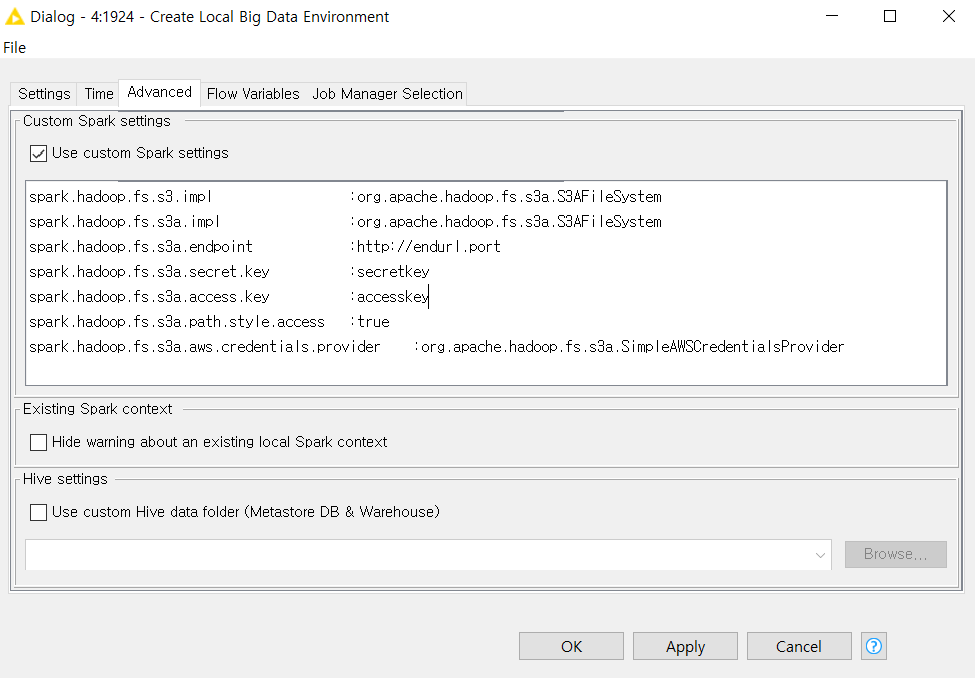
In addition, you said that you can specify the Spark configuration in the Advanced tab of the Create Local Big Data Environment Node dialog box, but I set it as shown below.
As mentioned by mlauber71 above, there are KNIME nodes to connect and read CSV from S3. The interesting connecter might be the Generic S3 Connector that might be able to connect to MinIO.
You can use the PySpark Script Source node, it already provides the spark session as spark.
The Hadoop version, shipped with the Local Big Data Environment, is slightly outdated and not recommended to read things from S3. You might switch to a real Spark cluster, or use S3/CSV nodes from KNIME.
I understand that “Create Local Big Data Environment” is required to use Pyspark locally on KNIME.
I can’t seem to connect an Amazon-only node to it and use it in connection with the Pyspark Script node.
In the end, can I understand that the Create Spark Context (Livy) node, which is applied when using Pyspark on KNIME Server, can also be used on Local to use Spark Session by utilizing the same?
You said that it is not recommended to connect with S3 because the Hadoop version provided by ‘Create Local Big Data Environment’ is not the latest version, so I understand that there is no way to connect with S3 through ‘Create Local Big Data Environment’ at this time?
Also, you mentioned that we can use .spark for the Python script source node. If we want to make additional settings for this spark, is it possible to customize it in the Advanced tab of ‘Create a local big data environment’?
I have never tried to connect to such a local spark environment with knime nodes (in order to get the grey and black connectors). Not sure if that would be possible @sascha.wolke .
I used the pyspark code inside the Python Script, but when I run that Workflow on the Server, does it use Python resources instead of Spark resources?
Also, if I use “Orc to Spark” or “Spark to Orc”, the PySpark Script only outputs a Table type to connect, but I can’t outputs a Port like Pickeld Object as a Table Port in Pyspark Scirpt like I can in Python Script, right?
You can use the PySpark Script Source, not Python. The Create Local Big Data Environment node creates the session, and you should add all required settings there.
There is no way to connect to S3 using PySpark code and the Local Big Data Environment node, but you can use the usual KNIME nodes. (Generic S3 Connector → CSV Reader → Table to Spark)
Note that the Local Big Data Environment node is only about playing around with Spark, it is not recommended in production. You should use the Create Spark Context (Livy) instead and connect to a real Spark cluster in production.
On a real cluster, you can use the CSV to Spark node or PySpark code to read from S3/MinIO.
There are some “Big Data Extensions(Spark)” related enhancements in KNIME 4.7.7 Version, so I updated from 4.7.1 which I am using.
I was hoping that the version of the internal jars files of “Create Local Big Data Environment” would be updated so that the processes that were not running with the old version would change.
However, the result was the same as failure. Is there any chance that the internal files of the “Create Local Big Data Environment” node will be updated?
The error is that when I run the code to integrate with minio in the Pyspark Script associated with the “Create Local Big Data Environment” node, I get the Script error message “Deprecated in 3.0.0. Use SparkSession.builder.getOrCreate() instead”.
This didn’t happen in my local Jupyter environment, so when I compared the jar file used in my local Spark configuration with the jar file for the KNIME plugins, there was a big difference in version.
So I’m thinking it’s a version issue with this jar file.
KNIME contains already a S3 connector, and this is the way you should read files from S3/MinIO in KNIME. The Local Big Data Environment does not support S3.
Pyspark module in the Jupyter notebook
How do you run your Jupyter notebooks, do you have a working Spark cluster? If so, please use the Create Spark Context (Livy) or Create Databricks Environment nodes instead of the Local Big Data node! I guess this might solve all the mentioned problems, and you should be able to read from S3 in a Spark cluster setup.
If you don’t have a cluster, please consider using the normal Python nodes and the S3 connectors to read the data. You should never use the Local Big Data environment in production.