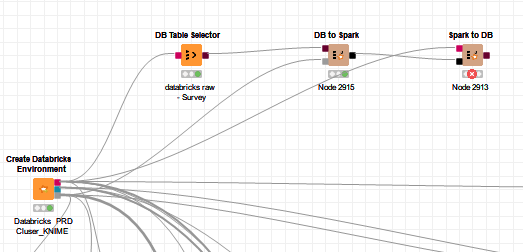
I’m using the Spark nodes with a Databricks cluster, and I’m having trouble executing the Spark to DB node. As per the attached screenshot, this can be demonstrated with a four node workflow:
Create Databricks Environment → DB Table Selector → DB to Spark → Spark to DB
The first three nodes run okay, but the final node gives the following error:
ERROR Spark to DB 0:31:2913 Execute failed: Failed to load JDBC data: [Simba][SparkJDBCDriver](500051) ERROR processing query/statement. Error Code: 0, SQL state: Error running query: org.apache.spark.sql.catalyst.parser.ParseException:
no viable alternative at input '("Id"'(line 1, pos 50)
== SQL ==
CREATE TABLE `default`.`spark_test_survey_table` ("Id" INTEGER , "SurveyName" TEXT , "CreatedBy" TEXT , "CreatedDate" TEXT , "IsCheckboxSurvey" BIT(1) , "IsActive" BIT(1) , "AllowQA" BIT(1) , "PreviousSurveyId" INTEGER )
--------------------------------------------------^^^
, Query: CREATE TABLE `default`.`spark_test_survey_table` ("Id" INTEGER , "SurveyName" TEXT , "CreatedBy" TEXT , "CreatedDate" TEXT , "IsCheckboxSurvey" BIT(1) , "IsActive" BIT(1) , "AllowQA" BIT(1) , "PreviousSurveyId" INTEGER ).
It looks to me like the problem may be that the SQL output from the node is quoting the column names, eg “Id”, when, apparently, Databricks expects column names to be unquoted.
I’m wondering if this is the problem and if so whether there may be any workaround?
not sure what you try to accomplish, but this is not the way the Databricks ENV ports should be used. The DB to Spark and Spark to DB nodes using a JDBC connection in Spark to transfer the Data between the DB and Spark (and this not very efficient). The Databricks ENV node exposes a DB and a Spark port. The DB port can be used with the Database nodes in KNIME to send SQL queries to Spark and execute them in the Spark cluster. The Spark nodes can be used to execute stuff using the Spark API on the cluster. The DB to Spark and Spark to DB nodes should be used to read/write data from/to an external DB that is not Spark.
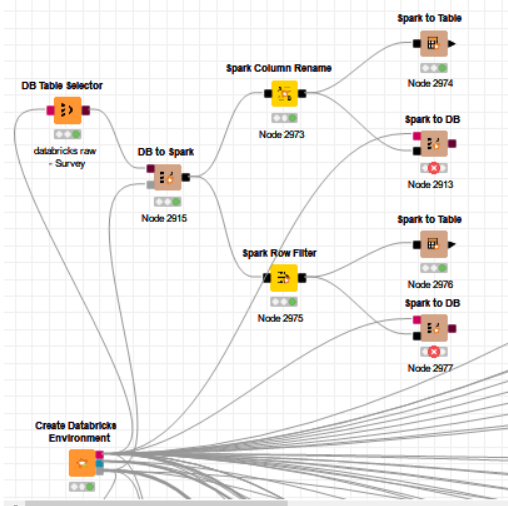
Thanks Sascha. That’s indeed the way I’ve been using them, and have no issues using the DB port to execute queries on the spark. As per the following screenshot, I’ve also succeeded in using the Spark API (eg row filtering, column renaming) - the problem comes when I want to transfer the data executed via the API back to the DB.
I highly suggest to use the Spark Node or the DB nodes and don’t mix/connect them. Is there any specific node missing? There is a DB Column Rename and DB Row Filter node too.
You can use the Spark DataFrame Java Snippet (Sink) node and create a virtual table from your data frame using dataFrame.write().saveAsTable("mytable") as code. After that, the DB table selector should be able to read the table.
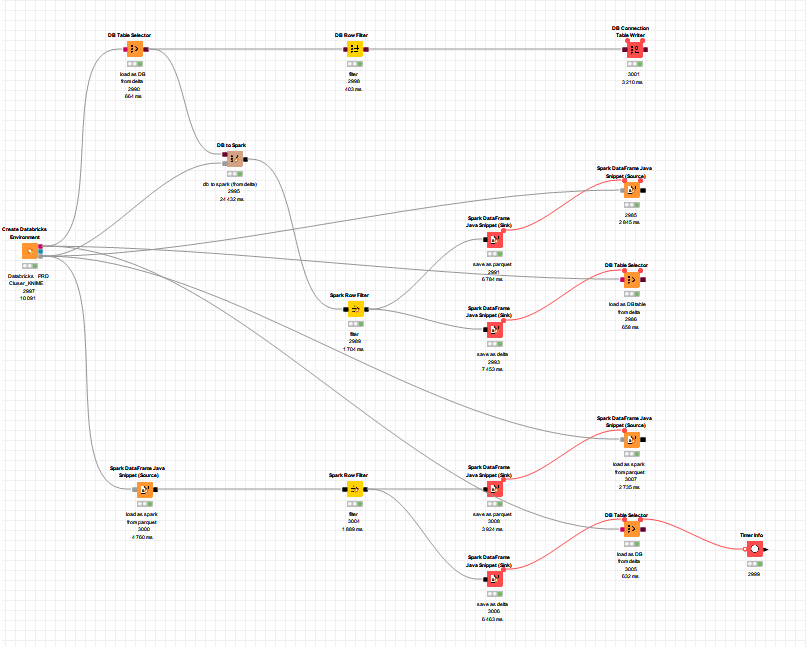
This has worked and I’ve now been able to achieve what I wanted. For the record, this was initially just to benchmark the performance of moving data around with the API vs the DB nodes, of using plain parquet vs parquet with delta, and of processing data within the API vs the DB nodes (though currently the amount of data is trivial so its probably not a fair comparison).
another thing you might like to test are the Hive to Spark and Spark to Hive nodes that let you store and read data from delta too. That’s another way to exchange the data between the DB and Spark nodes.
Can’t read the things on your screenshot on this resolution, but feel free to ask if you have further questions.
Great, thanks Sascha. I’ve gone ahead and tried out the Hive nodes and they’re working well too. It’s helpful to know there are several options to choose from.