Hi, I’m using Cloudera CDH 5.15.1 with spark version 2.3 and Knime 4.7.2 (cdh is kerberized)
I have a workflow like this:
Connect to Hive and HDFS
Create Spark Context
Put the hive table to spark
Do Transformation
Use Spark to Hive (using the same hive connector as previous one).
The workflow succeed. However, the new hive table is nowhere to be found.
If I use [database].[table_name], I’ll get Database not found error
Could there be anything that I should do rather than Spark to Hive to make it work?
I used to work with MapR last year with older version of Knime, All I need to do was spark to hive and it works like a charm.
So, is this the cloudera thing or the newer version of Knime is a bit different?
Or, I should do something with my clusters?
Thanks!
I have experienced that there are problems sometimes with tables created by Hive. Impala offers the possibility to make the table known to the system. Yes I know it sounds strange but why don’t you give it a try
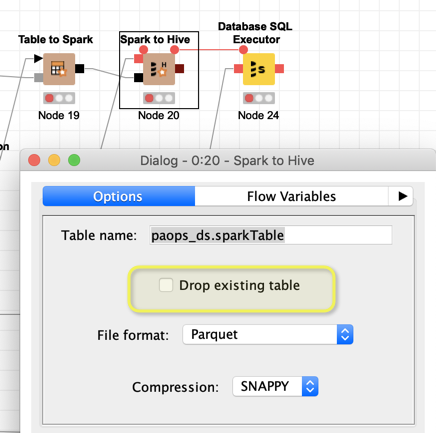
the Spark to Hive node is the right one for what you are trying to do. One peculiarity of Spark to Hive is that if you do not specify the database to write to, it will create the table in the default database. Hence the notation you used (paops_ds.sparkTable) is correct, because it specifies the database.
Could you make sure of the following:
The database paops_ds exists
Your user has the necessary permissions in paops_ds (create/select table, show tables, etc)
The column names in your table conform to the limitations of the parquet format (only A-Za-z0-9 and _ are allowed, no spaces).
Is the table created if you choose a different format than parquet?
Either one of the above problems usually results in an error, but you never know.
How did you try to find the new table? In KNIME you can look at the output port of the Spark to Hive node and try to preview the created table. Does that show the data? If yes, then the table was definitely created. If you used Hue to search for the table, then Hue sometimes needs some time to pick up on new tables (there is also a refresh button in Hue if I remember.
If none of the above helps, it could be useful to look at the YARN logs of your Spark context. Maybe something useful is in there.
Oh and one more thing (unrelated to your problem):
I noticed you are using Database Connection Table Reader -> Table to Spark to get the table into Spark. This does not work for large tables, because downloads all the data into KNIME and then uploads it again. There is a “Hive to Spark” node for that purpose.
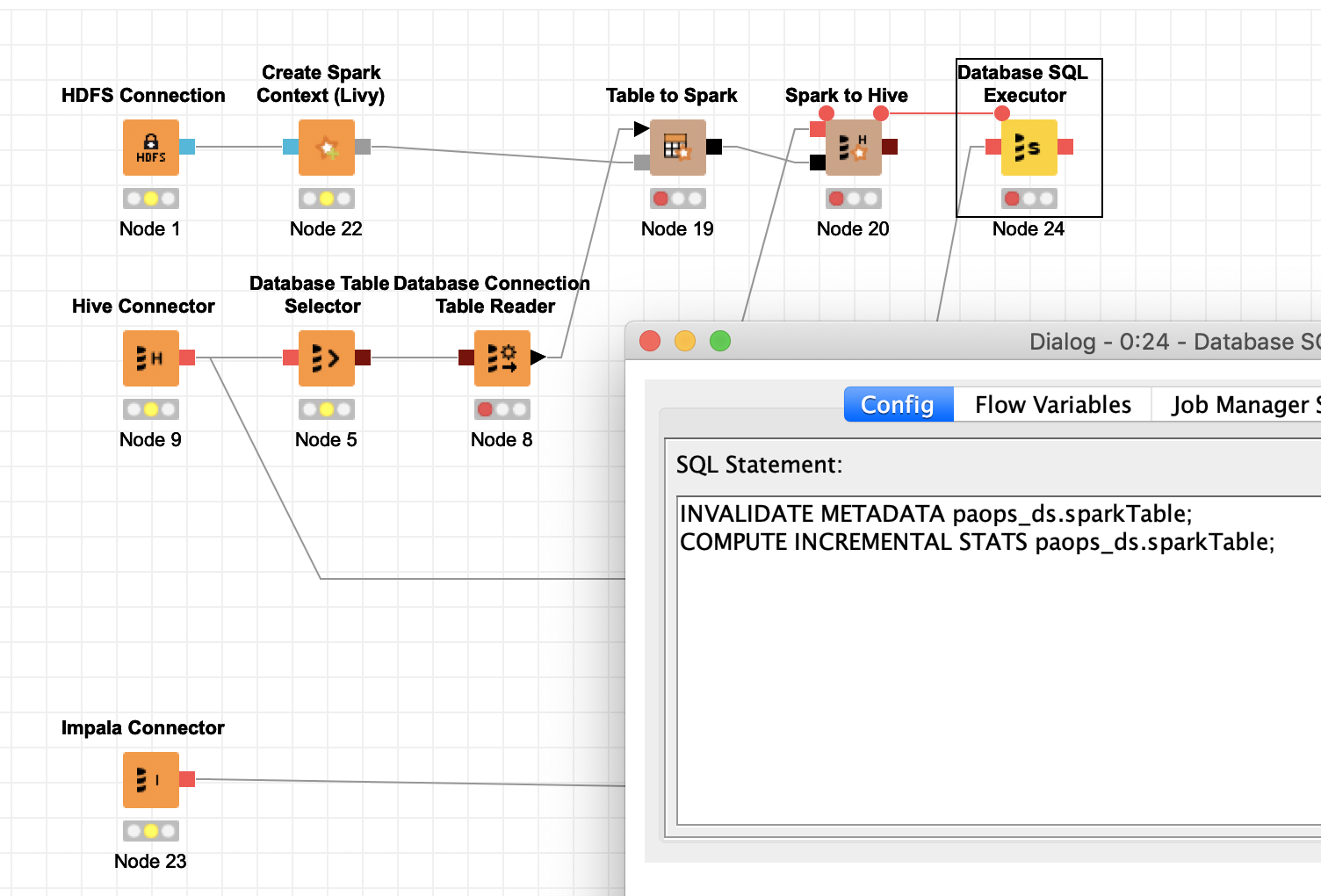
I changed your example workflow to show what I mean. With the Impala statistics there is a better chance your new Hive table will be known around the Big Data system.
An additional note. In your example you do not drop an existing table. That might be your intention but you should just double check if appending the data to an existing table is what you want.
I have experienced some strange behaviour between KNIME and Cloudera was it comes to creating and using tables. Sometimes the Cloudera system does not seem to recognise or accept what KNIME was doing. So some explicit statements might help.
Your user has the necessary permissions in paops_ds (create/select table, show tables, etc) - yes I have
*** The** column names in your table conform to the limitations of the parquet format (only A-Za-z0-9 and _ are allowed, no spaces). - just make a very simple name
Is the table created if you choose a different format than parquet? - Tried them but to no avail
So basically, if I see the output port of the spark to hive, I cannot find any result. But pretty much the light indicator turned green. (There is a table with contents coming in from the previous hive to spark nodes and additional processes)
 Forgive my ignorance.
Forgive my ignorance.