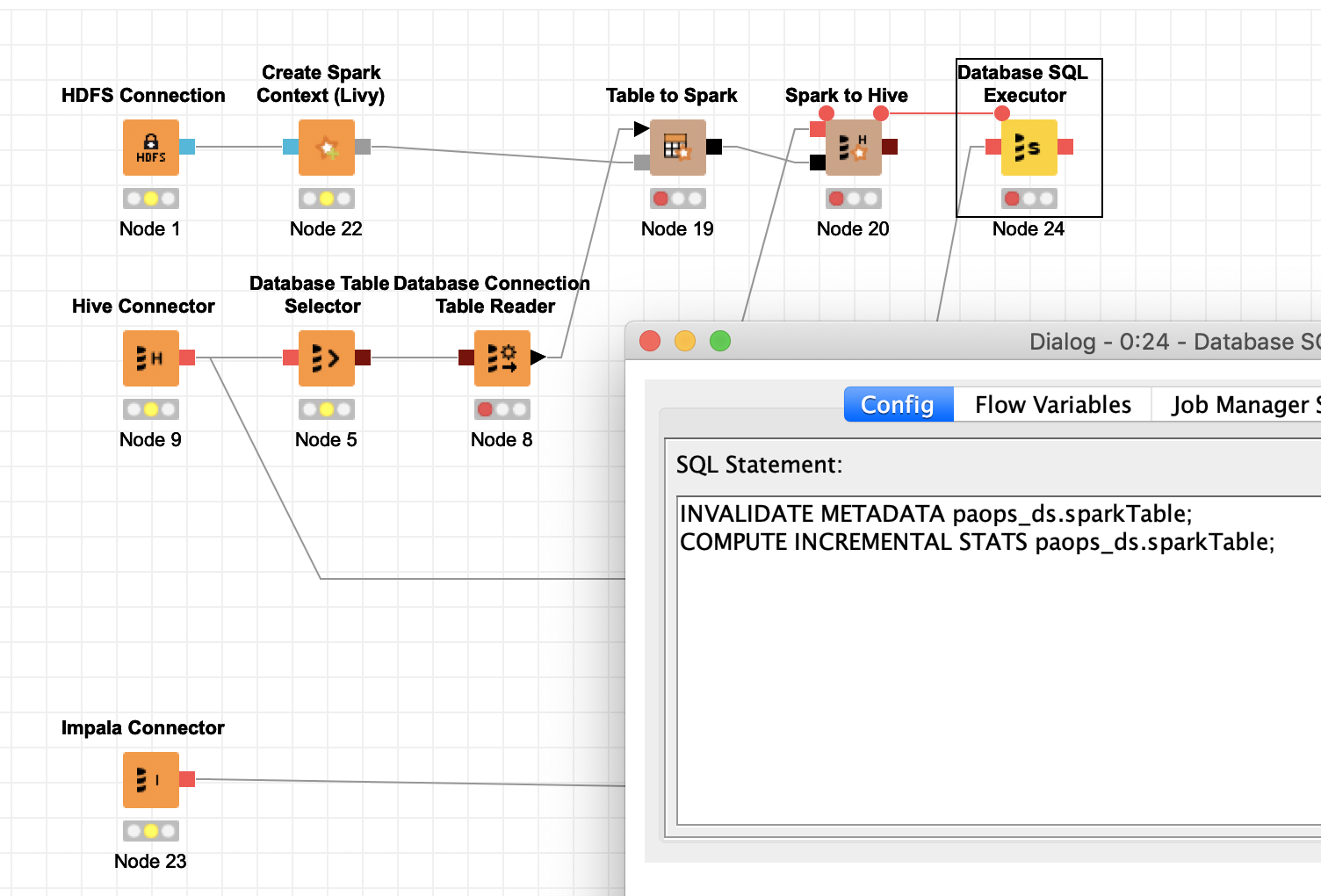
I changed your example workflow to show what I mean. With the Impala statistics there is a better chance your new Hive table will be known around the Big Data system.
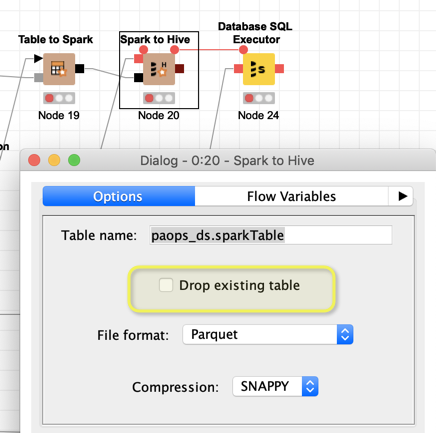
An additional note. In your example you do not drop an existing table. That might be your intention but you should just double check if appending the data to an existing table is what you want.
I have experienced some strange behaviour between KNIME and Cloudera was it comes to creating and using tables. Sometimes the Cloudera system does not seem to recognise or accept what KNIME was doing. So some explicit statements might help.
testhive_12.knwf (23.3 KB)