When processing data using Hadoop (HDP 2.6.) cluster I try to perform write to S3 (e.g. Spark to Parquet, Spark to ORC or Spark to CSV). Knime shows that operation succeeded but I cannot see files written to the defined destination while performing “aws s3 ls” or by using “S3 File Picker” node. Instead of that there are written proper files named “block_{string_of_numbers}” to the main folder in the S3 bucket.
Additionally there is created a file structure in other not defined “noname” directory, but with right file name
What is even more strange , when using “Parquet to Spark” I can read this file from the proper target destination (defined in the “Spark to Parquet” node) but as I mentioned I cannot see this file by using “S3 File Picker” node or “aws s3 ls” command.
Summing up the name of the file and its target folder in S3 bucket are different than indication in the nodes.
I’m using Knime 3.5.3.
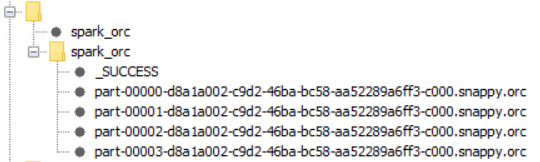
ORC and Parquet “files” are usually folders (hence “file” is a bit of misnomer). This has to do with the parallel reading and writing of DataFrame partitions that Spark does.
On top of that, S3 is not a real file system, but an object store. S3 only knows two things: buckets and objects (inside buckets). Physically, there is no such thing as “folders” inside a bucket. But if an object’s ID contains a forward slash, most S3 browsing tools (including KNIME) will display a folder hierarchy inside the bucket.
When you use “Spark to ORC” and tell it to write into S3 at “/X/Z” what is actually getting created is
A bucket called “X” (if you have the permissions and if it does not already exist)
A number of objects inside that bucket with ID “Z/part-somenumber-somerandomstring.orc”.
If you just put “/spark_orc” into the dialog of the Spark to ORC node, then it will try to create a bucket called “spark_orc” and then put objects with ID “part-somenumber-somerandomstring.orc” in there. I guess this is what happened here.
Summing up, the problem is that files that include data (“block_somenumberstring”) are written with undefined names and are not located in the defined object (“folder”)