Hi, I have a case where we need to use lots of try/catch and if/endif also case switch/end statements on our spark jobs. However, AFAIK, Knime does not have special try/catch and if/endif nodes for spark.
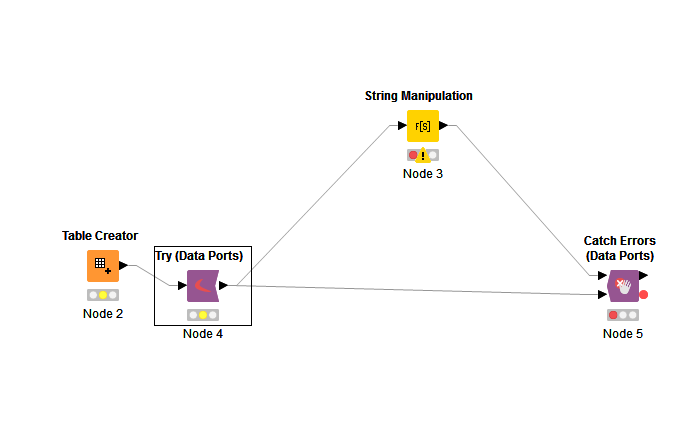
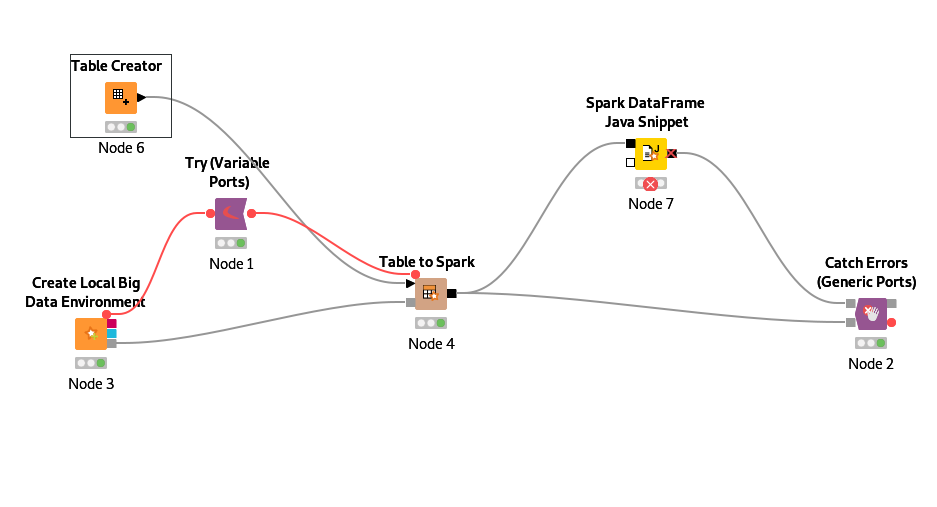
I am using variables try/catch but also very limited because we cannot use the catch on the spark data ports.
The same goes with case switch variable where I can control a flow by putting the case selection as input variable, but in the end I cannot concatenate them together as spark concatenate even if it says has “optional in”, still needs the previous node to get done.
Can I find any good example for these case switch, if and try/catch in spark?
2. And additionally, I need a workflow that even if the job fails it will destroy the spark context. I have tried some to no avail (with sample workflow attached)
Okay, I managed to get number 2 with try/catch…
Still, need the number one, especially case switch start and case switch end in spark with spark data.
(See attached… I need the same logic in spark). However taking the spark to table is not feasible as our dataset is very large
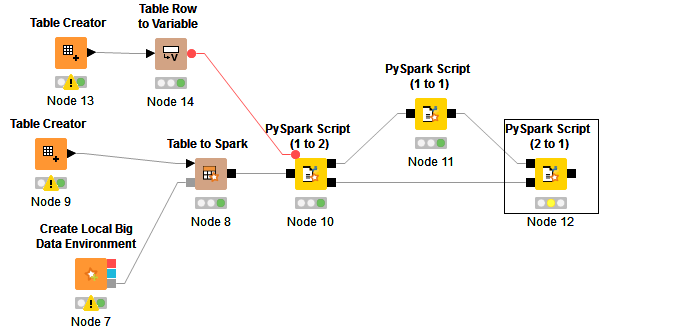
I use pyspark 1 to 2 and pyspark 2 to 1 but passing a flow variable which act as a flag
basically in pyspark 1 to 2, I just copy both of them:
resultDataFrame1 = dataFrame1
resultDataFrame2 = dataFrame1
in my first stream… I put an if statement using 1 to 1 pyspark script.
if flow_variables[‘v_eronica’] == 1:
resultDataFrame1 = dataFrame1.do_something
else:
resultDataFrame1 = dataFrame1
so, if we need to do something, the flag will be 1 and pass to the codes. Else, do nothing.
Finally from the top stream and bottom stream, just use pyspark 2 to 1 nodes.
with codes as follows:
It is not a clean way to do it. So basically I need to find the “flag” first by validating the data.
However this one is more a case-switch scenario rather than try-catch…
I still need the try catch… Like try to do functions in spark, if it fails do nothing/something else. This way we need to run first rather than getting a flow variable.
Hey @Mizunashi92
I am not sure if I understand your use case correctly.
I seems to me, that you have a simple If/Else here, that you could handle with a 1 to 1 PySpark node.
I do not see the need of several nodes here.
You said you are already using the variable Try/Catch nodes with Spark, what is the issue you are having with it?
best regards Mareike
PS: There is no such thing as “too many questions in the forum”.