Hi @onp1ldy,
I think the culprit is the sampling rate: the underlying model is trained with 16 kHz sampling rate - see the node description of the CMUSPhinx4 SR node - and most recording softwares use a higher sampling rate. You can check the sampling rate with the “Audio Data Extractor” node:
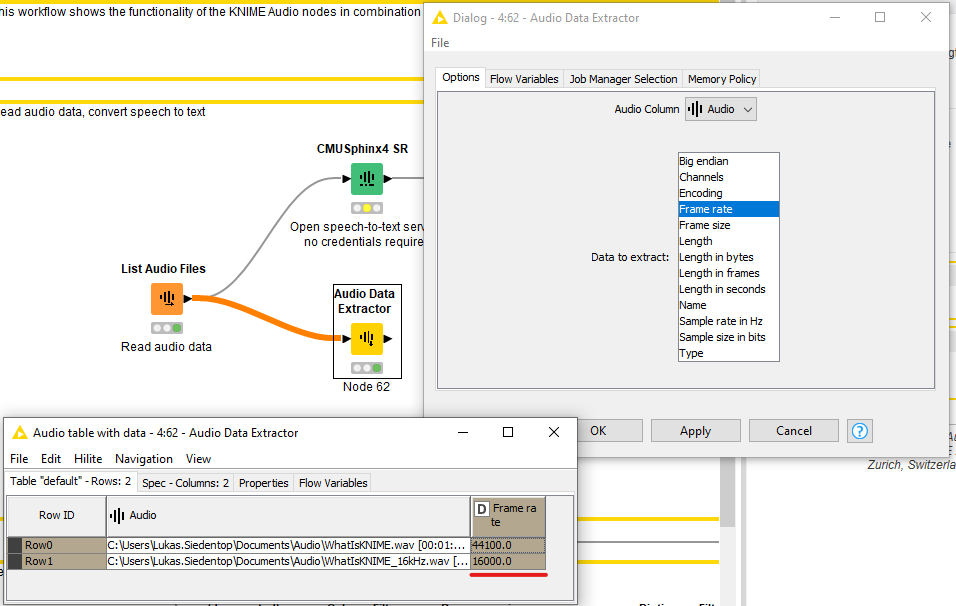
44.1kHz in my case. In order to transcribe this, you’d need to downsample your audio file to 16kHz.
Maybe your recording tool already allows to set the sample rate? Otherwise I’d suggest ffmpeg (in my case: ffmpeg -i .\WhatIsKNIME.wav -ar 16000 .\WhatIsKNIME_16kHz.wav from the command line) or the like to do the downsampling. See also the FAQ of CMUSphinx
(I tried reading the first paragraph of Wikipedia on KNIME and with the 16 kHz sampling rate results are indeed not any more useful. Lets see what your results are, hopefully this is only an issue from my side. I’ll keep you posted if I have more insights)
Best Regards,
Lukas