Hi everyone! I was given a large file that is actually several different reports. Each section has a “header” portion marked by some delimiters (see below). I would like to be able to partition out each of these sub-reports using some rules (there is actually another sub-report within the main sub-report so I would actually need to do this twice for each section. Can someone assist me in the cleanest way to accomplish this?
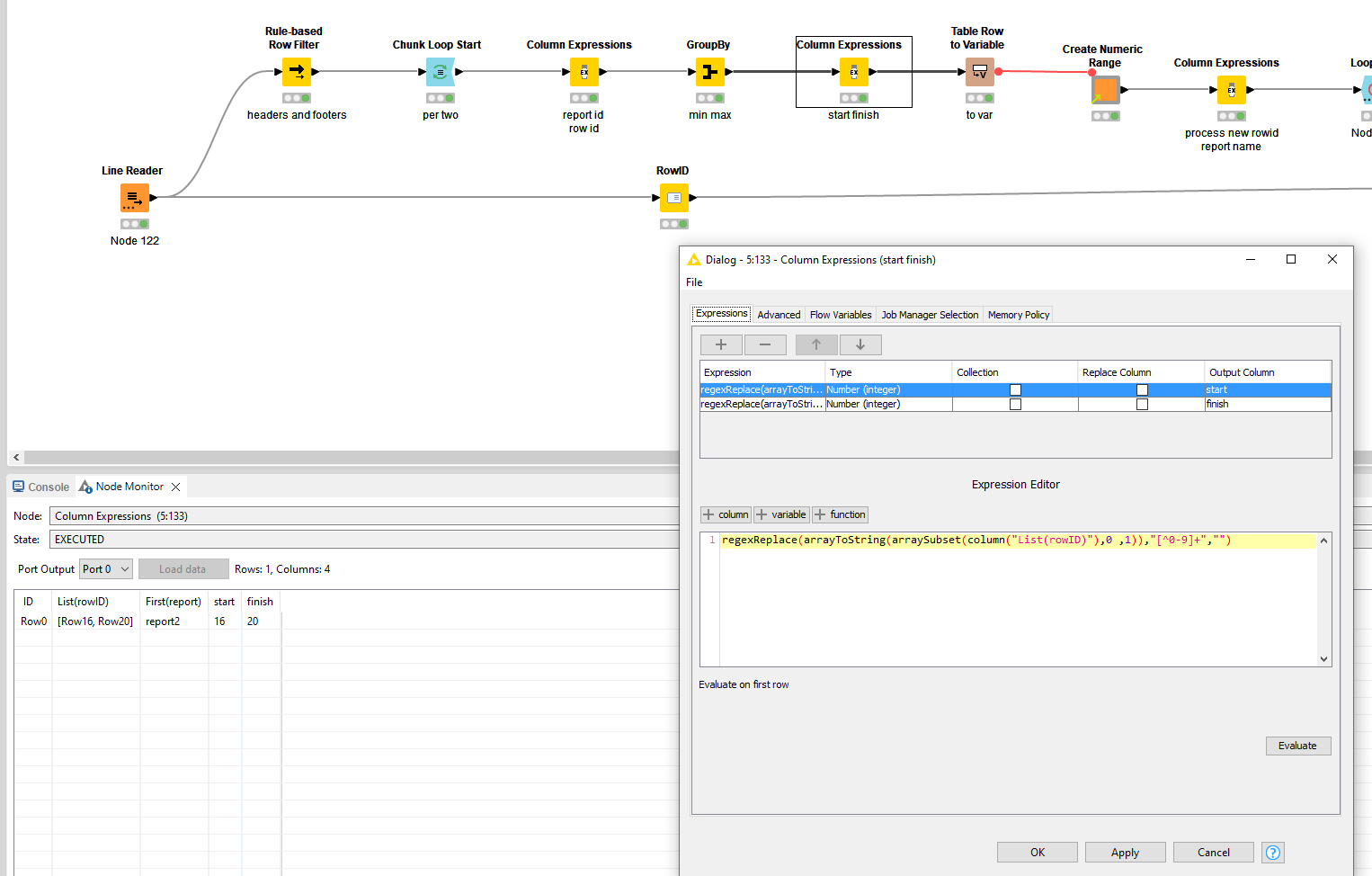
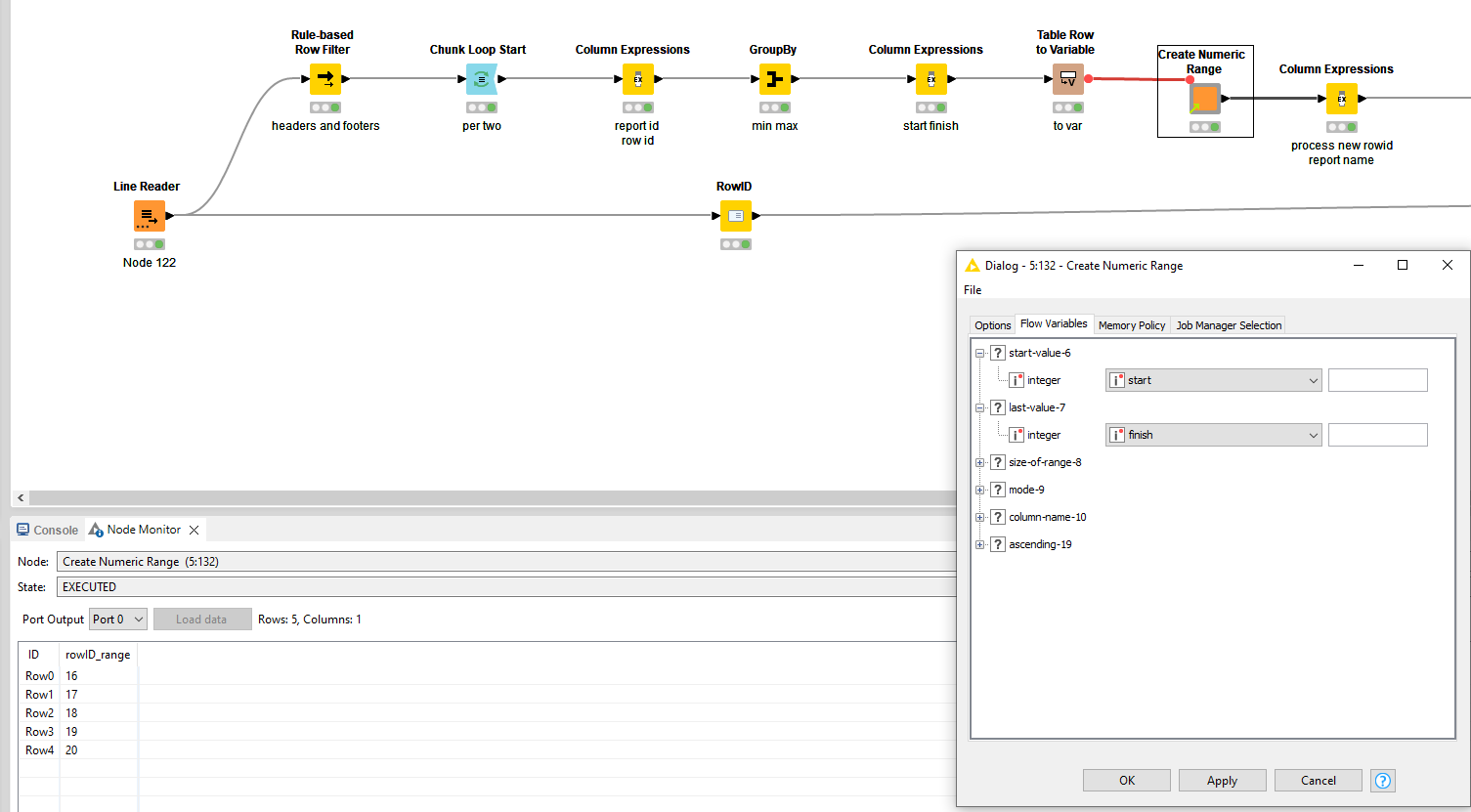
Convert this to integers by using regexReplace(arrayToString(arraySubset(column("List(rowID)"),0 ,1)),"[^0-9]+","") and regexReplace(arrayToString(arraySubset(column("List(rowID)"),1 ,2)),"[^0-9]+","") in a Column Expression.
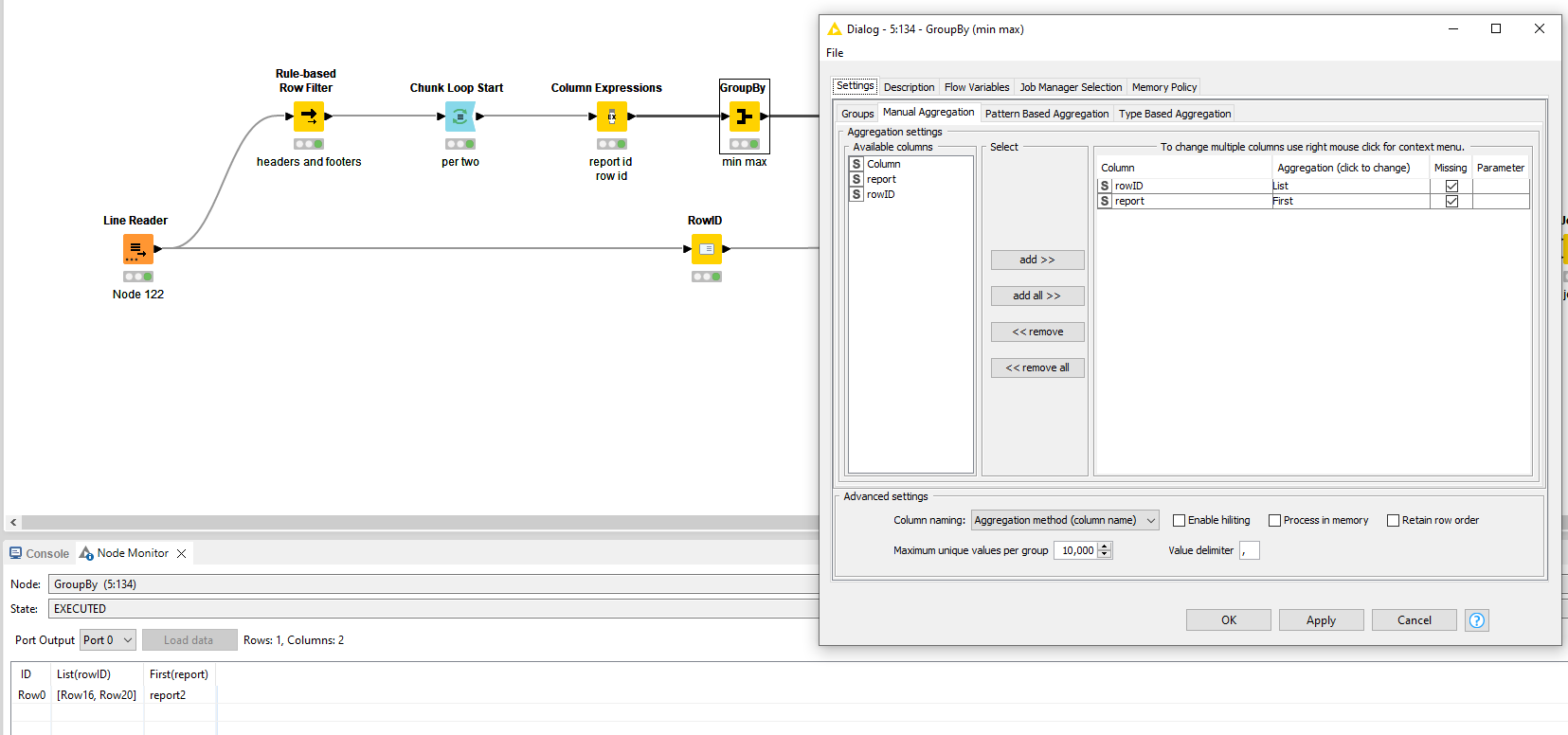
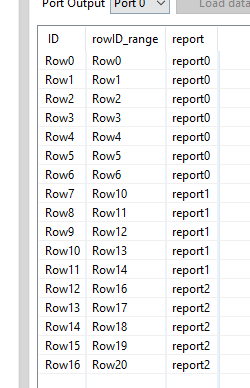
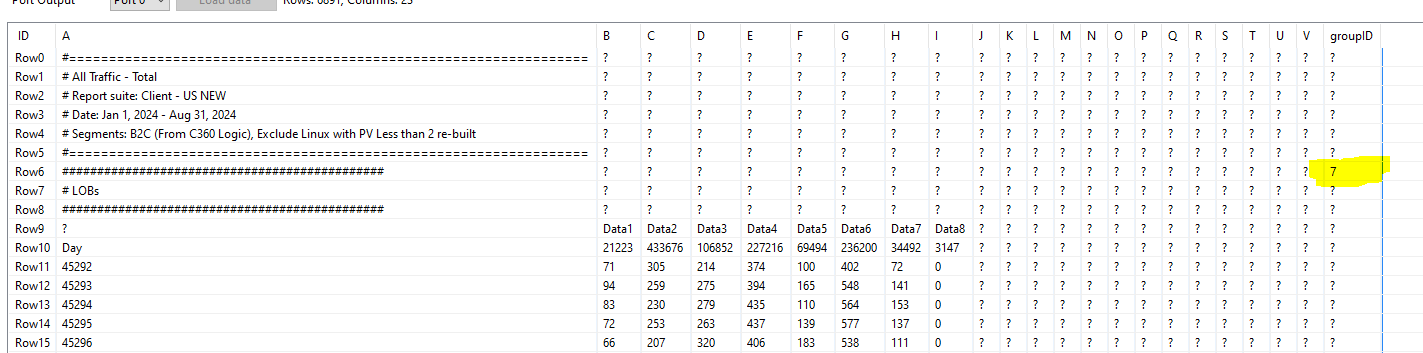
Re-instate the original values and you end up with an overview of which report is covered by which rowid’s.
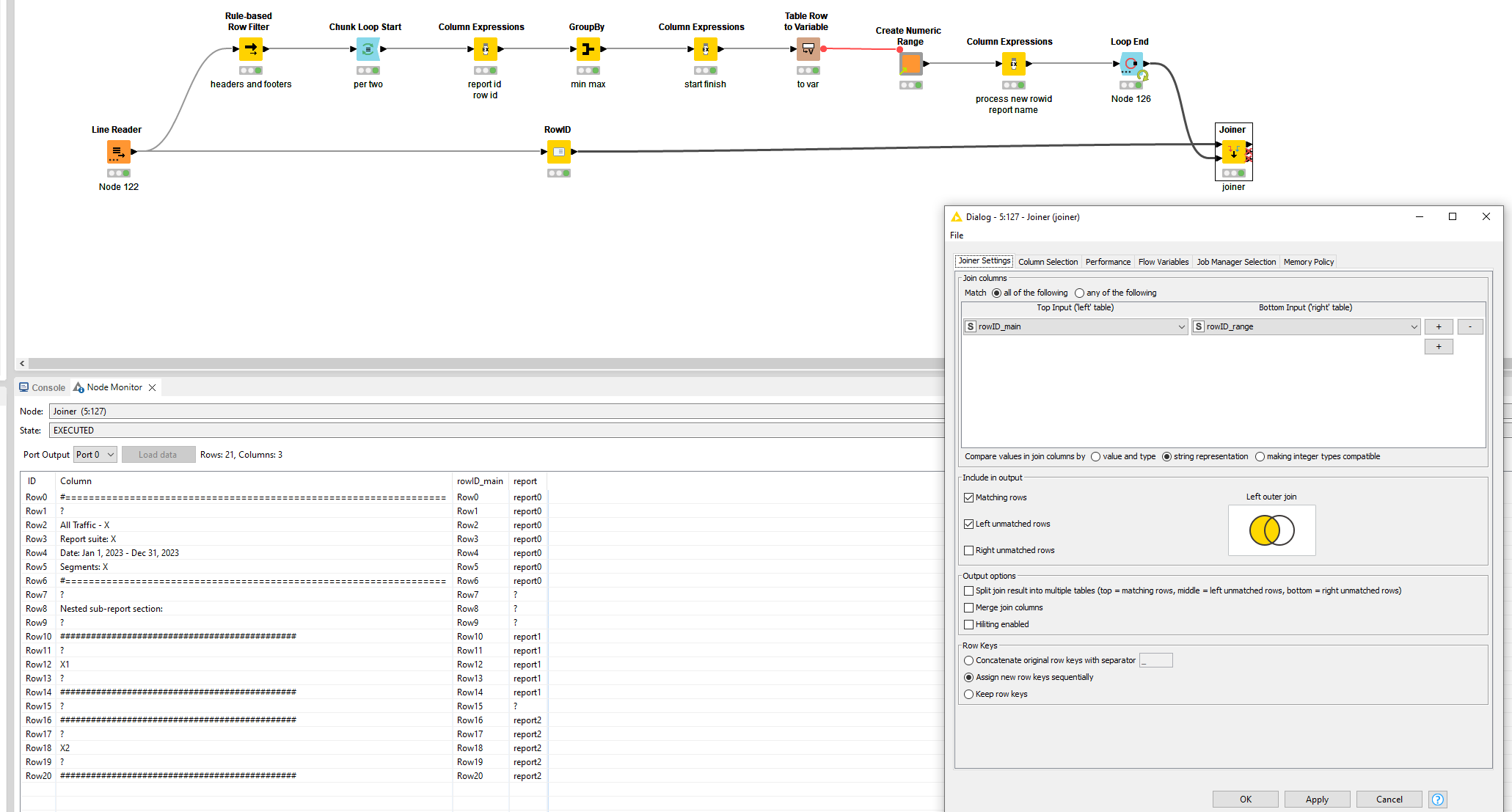
Do a left outer join to the main branch again and it’s now ready fur further processing. If you want to take out the noise of the non-relevant rows, do an inner join.
Wow, thank you! This is really clever This will most likely work with some minor adjustments. I am attaching a sample data set so you can actually see what I’m dealing with. You will see that the delimiter strings indicate just the start of each new sub data set so chunking the report between delimiters is actually just going to pull out the header information (which I do need in order to grab some info about what the subsequent data contains – the chunking might actually help with that) – apologies for not being super clear on that. So the actual report with the true raw data does live below each header section.
Just FYI, I was having some problems with the second Column Expression node. Not sure but it may have just been a syntactical thing if you were using a placeholder or something.
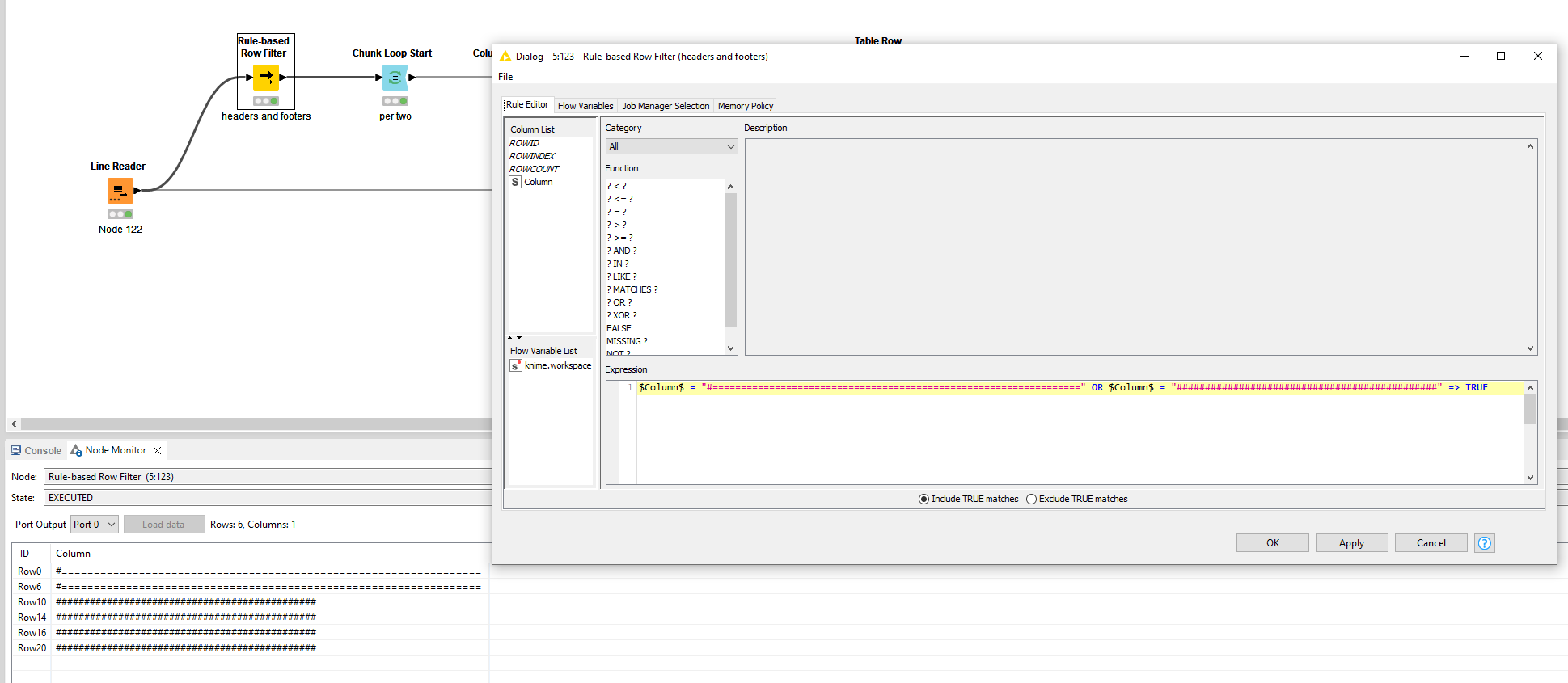
Delimiter key:
Indicates start of each new unique report
#=================================================================
All Traffic - Total ← need this info to hard code into a new column
To be completely honest, the formatting makes it a bit difficult to understand your post because a hash is converted into bold chars. It’s easier to just put it in a code block
It’s also not fully clear to me yet what constitutes a new report but if I understand it correctly, this should be considered the starting point of a new report:
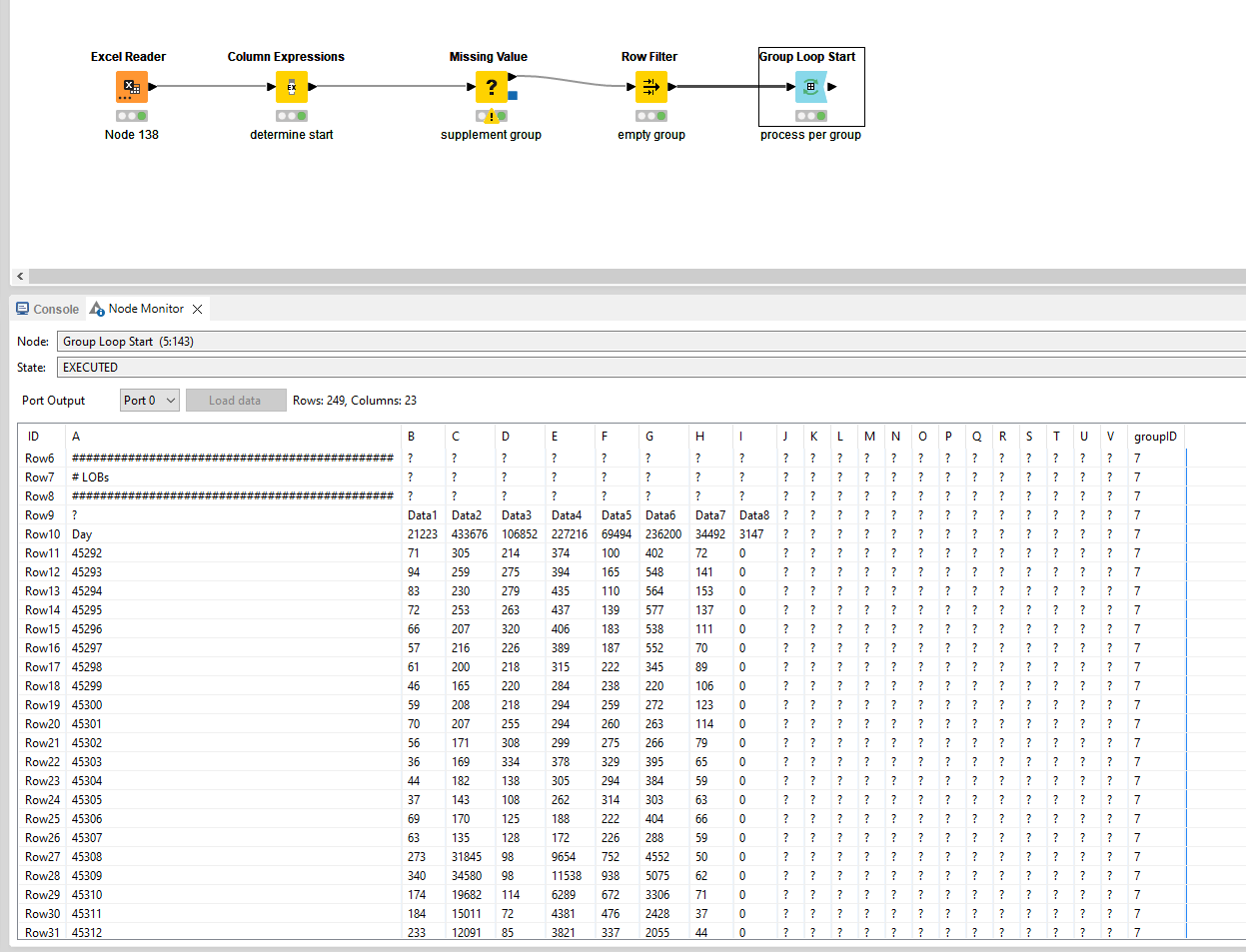
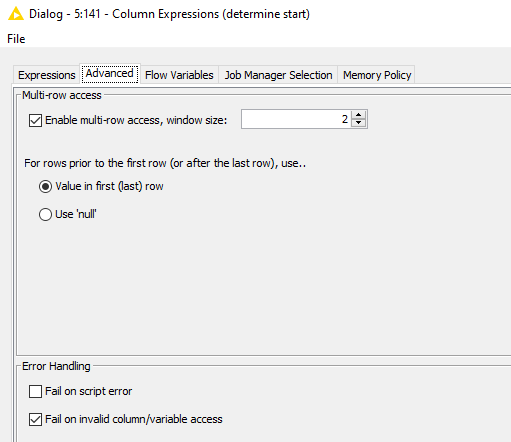
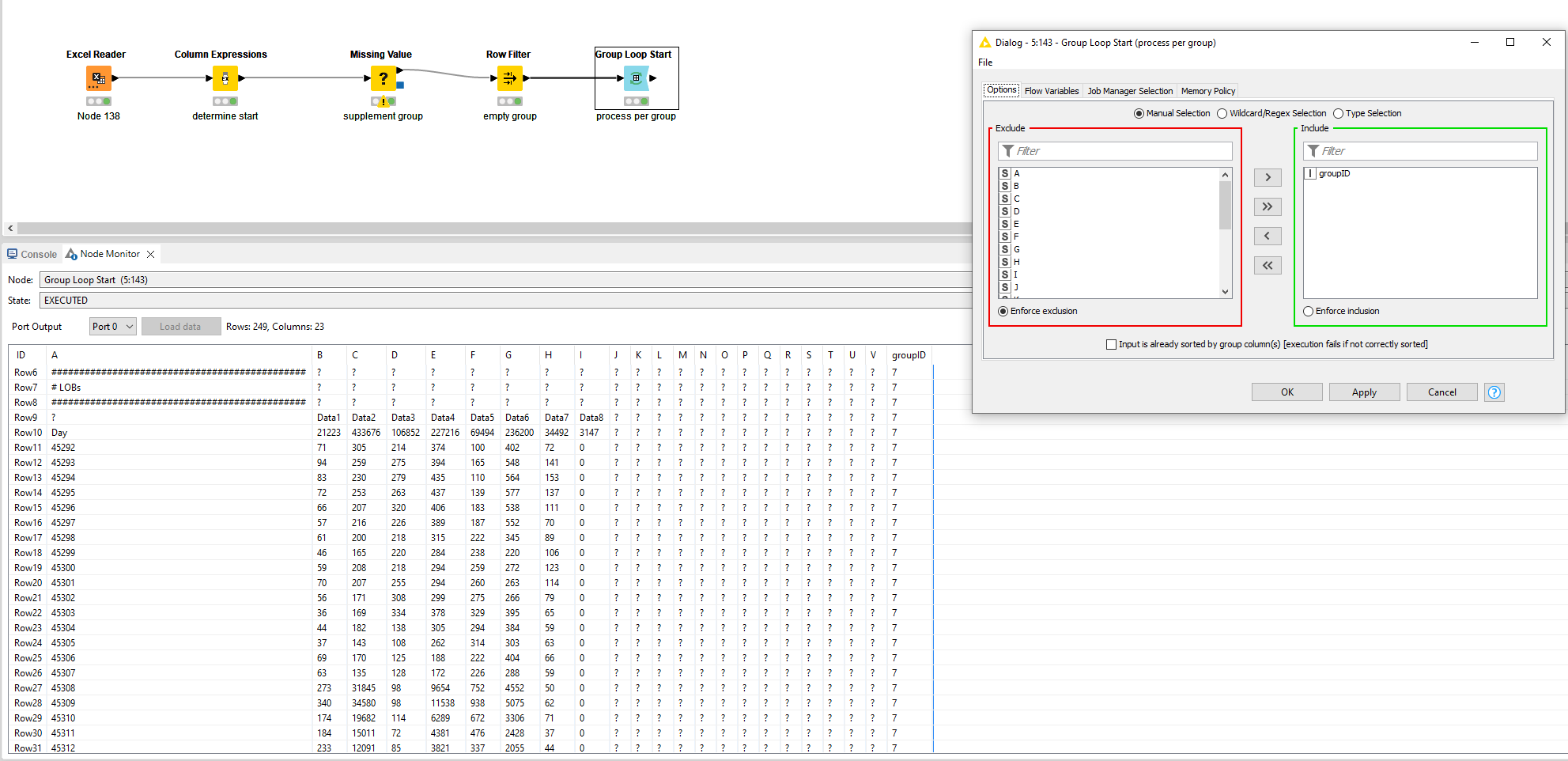
Many thanks for this guidance! The groupID/fill down steps make a lot of sense to me (I’ve done a similar sort of thing with a modulo index). As far as the Group Loop step, that’s where I get a bit lost. If you can help explain a little more what that node is doing exactly and what the next logical step would be, I would be ever grateful. Also, if you have some tips/advice on learning the regEx stuff, I would love to dive into that a bit more, too!
What the next logical step would be is fully dependant on your usecase, hence me only mentioning it as a loose end. What the group loop does is basically consider all rows based on a value that they have in common.
In your situation I assumed that you want to process each report individually. For example: if you want to manipulate the data and write it to an Excel again, you would need to repeat this process several times since you have multiple reports. Instead of having X amount of Excel Writer nodes, you just need one if you make this part of the loop. You can work with flow variables to dynamically create the correct path, filename, etc.
There are several examples on the Community Hub of such a scenario.
Regex is mainly learning by doing. Use chatGPT, video tutorials and several website has public libraries with patterns to use, like regex101: Community Pattern Library