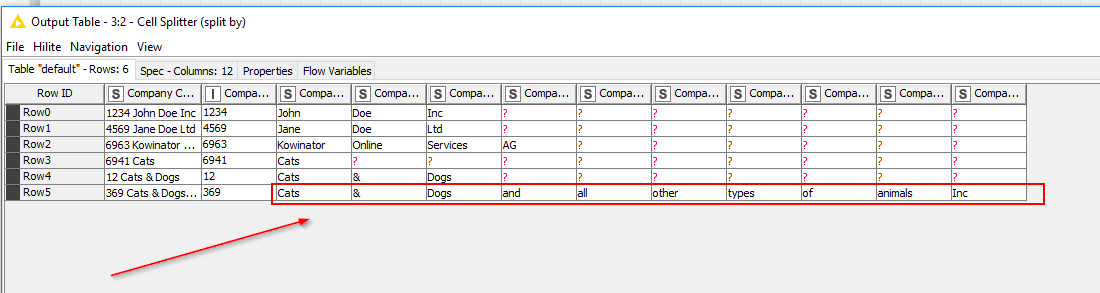
Is there a way only to split by the first “space” character (the most left one so to say)?
I have a table (see screenshot, attached workflow), in which the first “item” is always the company number and everything that follows is the company name.
why not use the String Manipulation node:
substr($Company Code$, 0,indexOf($Company Code$," " ) )
-> this takes the substring from “company code” beginning at index zero till the first occurence of the space character
and for the second column, just change it to
substr($Company Code$, indexOf($Company Code$," " )+1 )
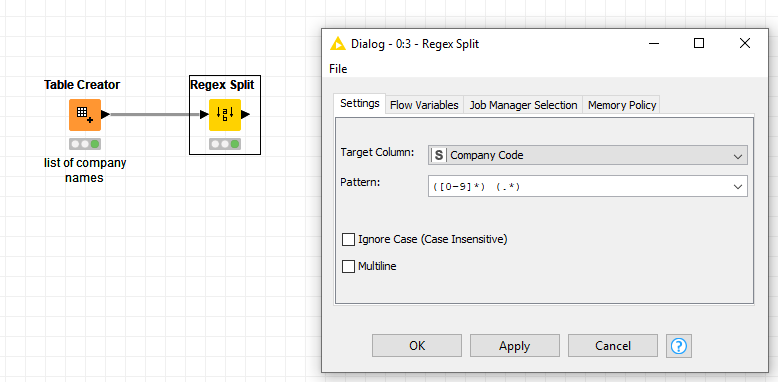
Considering cases where the first part of the string is not only digits, I suggest this regex in the solution by @lisovyi although it is already alright and works fine in your examples. (.*?) (.*)
I’m sharing this in case any other user has the same issue but the first part of the string is not only digits.
Thank you everyone, every single solution works. Wow that’s amazing!
Now I am left with one problem, which one do I mark as the solution to this question (to close the thread)
Phil
ps: I chose first response…
pps: for anyone who needs an exmaple workflow, here it is incl all 4 solutions: split-by-space-problem-solved.knwf (13.1 KB)