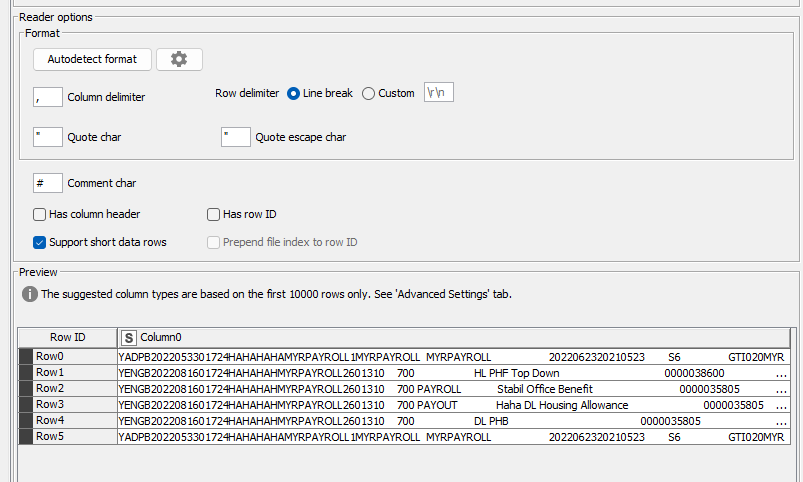
Hi @mmngeoh , it’s better to share a workflow than a file, in this case, because we don’t know which node you used to open the file with, and from there, how did the output table appear in Knime - is it a multiline single cell? Is it exactly like the Excel screenshot you showed? Without a workflow, it’s not possible to assist you further.
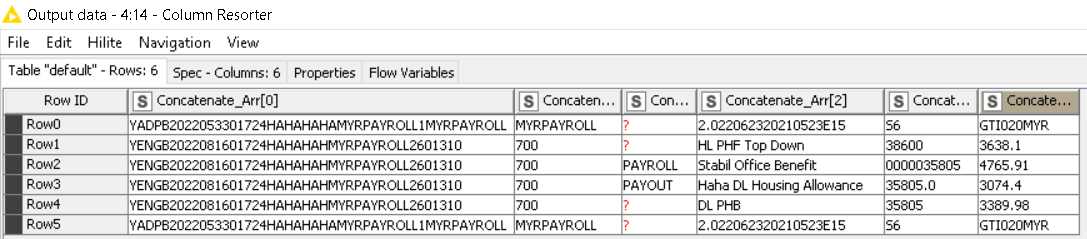
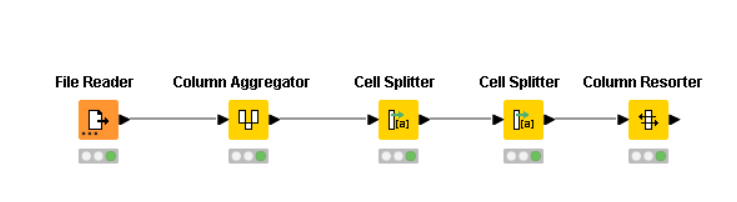
@mmngeoh , I managed to restructure your table to something workable. But please note that this relies upon the fact that most of the columns are separated by at least 2 spaces. I use that info for my delimiter decision during file reading. If your new .dat files in the future doesn’t fit this rule, my method won’t work on them.
I deliberately leave out the row filtering task to you, since it’s a basic task. You just need to identify which is the first row and which is the last in order to filter them. It can be done in many ways, all of which are simple enough for you to proceed on your own