My problem is: after a DBSCAN node I get a table with the attribute "cluster" that, in my case, yield 4 values (cluster_01, cluster_02, cluster_03 and noise). Now I want to split this table in 4 tables, each of them containing ONLY one category of clusterization (i.e. table 1 of rows of the 1st cluster, table 2 of rows of the 2nd cluster and so on...). Obviously I don't know a priori how many clusters I'll get. I thought about a for cycle with a variable on the number of clusters, but I've known KNIME for 3 days and I don't even know if cycles are possible (tutorials are pretty unclear)!
Hi Luca and welcome to the KNIME Analytics Plattform :-)
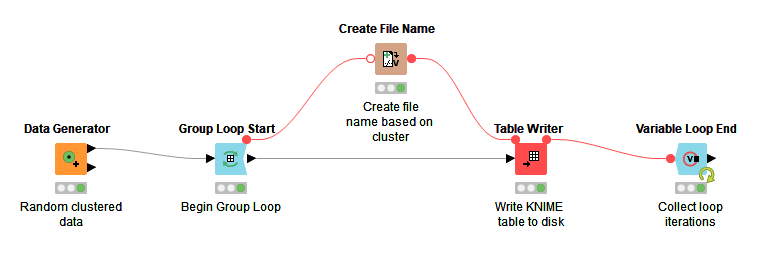
The cycles are called loops and in your case the group loop start on the cluster column would provide you with one cluster in each run. The loops are finnished with Loop Ends.
Tomorrow I'll try to have a better look at the loops nodes. Could you give me further indications on how to practically realize the work I have to, or where to find infos about loops? I looked at the examples in KNIME and the official tutorials but - ok, I admit I was in a hurry and I probably didn't look enough! ;-) - I found them little detailed and sometimes confuse.
Please can someone share a worked example of how to do this? I have exactly the same query as Luca and I’ve read through the guides but I still don’t understand how to do it… what nodes do I put in between the start and end loop?
Try out the attached workflow. It writes separate files to disk for each cluster identified in the dataset. It uses flow variables to set the file name to write to, so if you’re not familiar with those, let me know and I can point you to some videos.