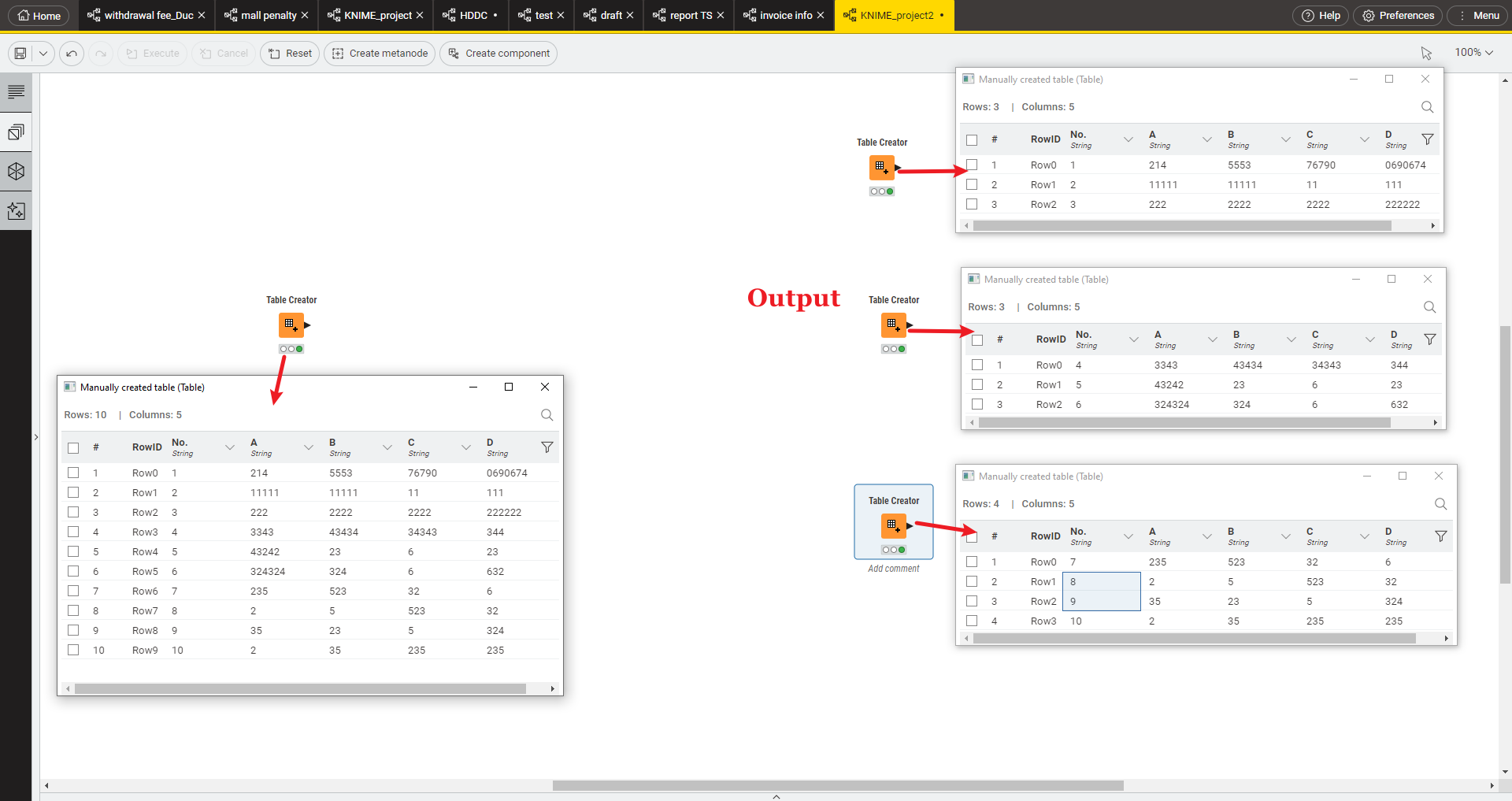
I have a table like this. My problem is, to split this table into many small parts. The rule to split, based on the number I want.
For example, I want to split it into 6 parts. Then, I will based on the total row in the table, and split it into 6 parts equally (if it is odd numbers, it’s ok for unequal tables). My real data also have column No., maybe someone can utilize it.
Hi @Nguyen_Huynh_Du , how are you intending to use the different tables afterwards? If you are wanting to just write them out to different files then it can be done in a loop, and we could show how to do that.
If you are wanting n different table viewers, though, where n is a dynamic number determined at run time, then this becomes problematic since each viewer is a different “branch” (presumably with some kind of calculated row filter/splitter with variables defining the splits) and you cannot generate branches dynamically “on the fly”.
Is there any upper limit to the number of different tables you might have (e.g. at most 3 tables, 10 tables, something reasonably manageable?)?
Hi @Nguyen_Huynh_Du , I’m not sure what you’ll do with the split tables once they’re split, but take a look at the following workflow
It uses some components. In the example, it takes a table of 200 rows, and quickly splits it into 40 individual outputs.
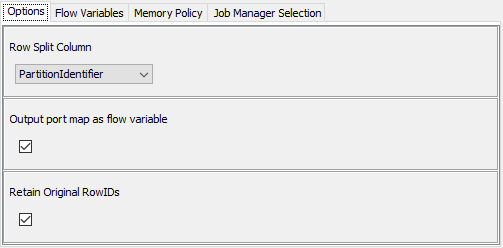
The first is a component for marking rows on a table with sequential “partition numbers”, based either on “rows per partition” (variable number of partitions with fixed number of rows) or “number of partitions” (fixed number of partitions, with variable number of rows):
You can also specify if the row allocation to each partition is “chunk” (e.g. first 10 rows go to first partition) or “rotation” (e.g. first row to partition 1, second row to partition 2… etc)
Once the rows have been marked with partition numbers, you can then use another component:
This returns the first 10 partitions found on separate output ports, and the remainder on the 11th port. You can chain these row splitters to easily output a large number of partitions on separate data ports.
An alternative to the Partition Row Splitter is this component, which allows you to provide specific regex patterns for each port, should you have other partitioning requirements:
As mentioned before though, whether any of this is of use depends on what you are ultimately trying to do.
You may for example want to use the Create Partition Column to generate the “chunks” of rows, based on your “n tables” requirement, and then use a Group Loop to output each of the partitioned sets of rows to individual output files, for onward processing.
Usually, I want to divide it into 6 parts. And, do you have any example for using the regex multi row splitter node?
And, when I used regex multi row splitter and Partition Row Splitter, I encountered this problem. Can you help me on this please?
Contains one node with execution failure (MISSING NoOp (Table) #66)
MISSING NoOp (Table) #66: Node can’t be executed - Node “NoOp (Table)” not available from extension “NodePit Power Nodes” (provided by “Philipp Katz, Daniel Esser; nodepit.com”; plugin “com.nodepit.noop.plugin” is not installed)
Hi @Nguyen_Huynh_Du , the “Noop” node is in the Nodepit powernodes and are available from Nodepit, and the installation instructions are here should you wish to install them:
However, I have updated the components in the sample workflow so that they no longer use the Noop nodes,. I still recommend the powernodes, but they shouldn’t be necessary now to get these components working.
It’s probably best to redownload the demo workflow:
This should then have the latest versions of the components, or you can manually trigger an update of the components.
Once working, the workflow gives examples of both these “splitter” components, but if you have any queries on how to make them work, let me know.
For background on the origins of the “Regex Multi Row Splitter” component, see this thread: