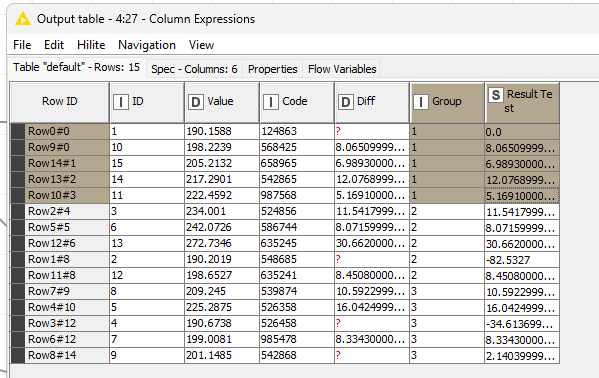
I need to create subsets of a table depending on values in a column. The table is shown below. The column of interest is the “value” one. I need subset tables of 5 raws with values increasing by at least 5. For example, a subset table would be: ID 1,10,15,14,5. Because ID 10 (198) is >5 higher than ID 1 (190), ID 15 (205) is >5 higher than ID 10 (198), etc…
Another subset would also be 2, 12, 8, 11, 3.
Thanks for your reply !
In other terms the subset 1 would be:
1,10,15,14,5, because 190<198<205<217<225, with a difference of at least 5 between increasing values.
Thanks for the additional details. What is difficult to comprehend is the logic behind 1,10,15,14,5, which relates to the ID I suppose, and the other sub-set 2, 12, 8, 11, 3.
Could it be that you want to accomplish the following:
Take the first row
Identify the next row whos value difference to the first selected is >5
Skip / reprocess the rows which do not match in the next iteration
Thanks for your feedback.
This relates to the ID indeed.
The points 1. and 2. you mention are right, then I need it to do it again until it has found 5 values that increase each time by at least 5. The first subset would then be ID 1–>5–>10–>14–>15. Sorry, I used the numeric order in my previous explanation. Then it would make a first subset table of these 5 raws.
Next, iterate with the remainder table (without the 5 rows of the firt extracted) and create new subsets. The second subset would ID 2–>3–>8–>11–>12
Thanks again for your interest and support !
Hello, @AWood can you explain why you want 1->5->10 etc and not 1->3->5-> etc
ID 3 is higher than ID 1 by 5. Did you suppose that the values have to be in increasing order ?
Best,
Joel
Edit : ok, I just understand this “a difference of at least 5 between increasing values”. My question is out of the subject !!!
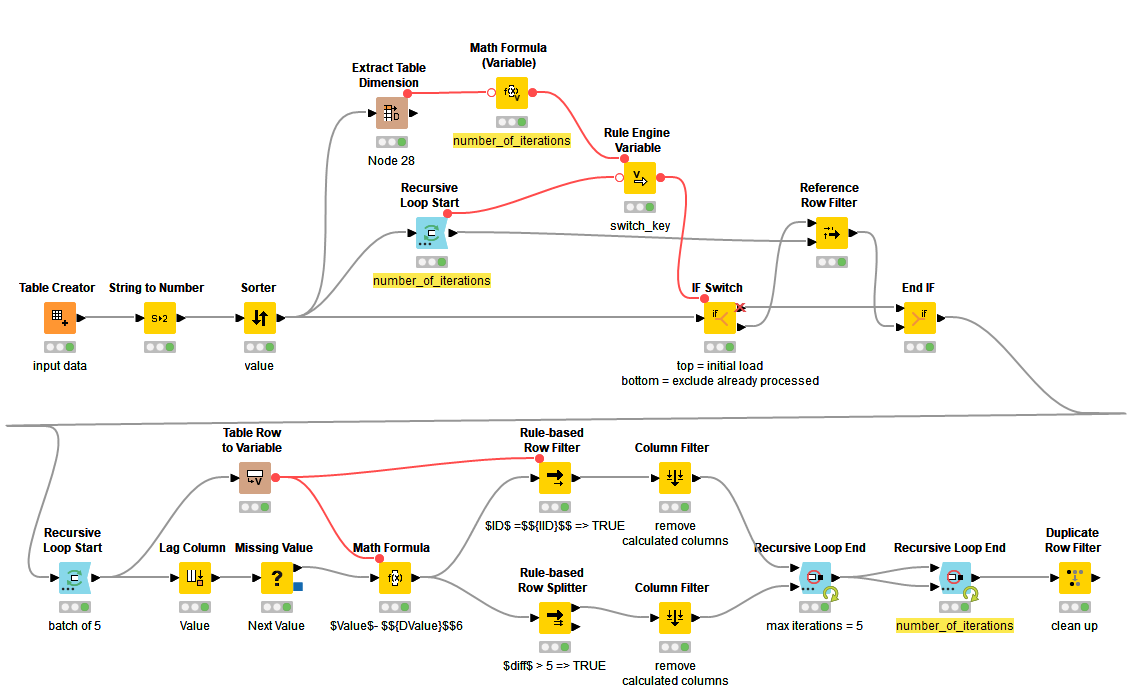
See if this wf split tables depending on value differences.knwf (108.9 KB) works for you. Maybe it is a little bit complex with a nested Recursive Loop. But see for yourself step by step. The “step loop execution” option in the End Loop node can be helpfull here to understand what is is happening.
Intriguingly, it does not come to the same conclusion as you since the next closest ID after ID 14 with a value of 217,2901 is ID 11 with a value of 222,4592 but not ID 5. Furthermore, ID 5 is getting removed / skipped.
What I haven’t fully comprehended is the result around ID 2 and 4. Mostly because it’s late and I don’t want to take all the fun out for you as well learning something new
Dear Community, dear Mike, dear Hank,
Thank you very much ! This was yesterday my second day on Knime, I was still looking for the best channels to learn aboutit and BOOM: two of you come with different solutions. I need some time to test it and learn the different nodes to get inspired for future wf. I’ll get back to you asap and hope to start being an expert to find my turn to help the community as you do so well !
Thank again and see you later !