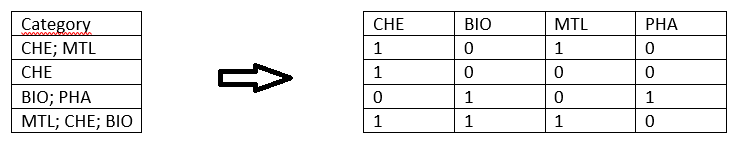
I have several columns imported from an Excel file with a header text. The columns contain varying numbers (lots of missing values with missing separators) of text snippets that are differing in order. An excerpt of a real example is the three letter acronyms above, but there are more complex cases with more than 20 multi-word expressions. The divider is either "; " or ", ". I would like to transform my data into multiple rows, each corresponding to one category (1 and 0 might also be TRUE or FALSE).
Any suggestions on what combination nodes I might try using to implement this?
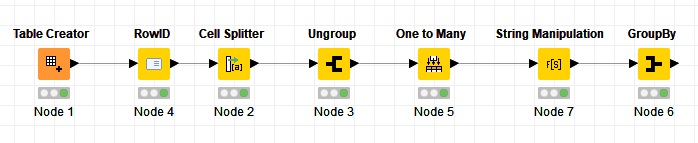
you can use a Cell Splitter node to convert the content of each cell to a collection and then use the Ungroup node and then, “One to Many” does what you want (transforms each value to column). And the GroupBy node aggregates the rows based on some ID. This ID may already exist in your dataset or you can generate it.
I have suggested 2 methods to do that: First generating new Row IDs by using a RowID node just at the beginning of the process or by editing the original Row IDs using a String Manipulation node before the GroupBy node. cell to header.knwf (27.8 KB)
Dear Armin,
Thanks for the quick help. This is really a great solution to my problem. I could never have come up with this, but your workflow is great for improving my thinking in such things.
Best,
Leo
Nice one
Just a question from my side. It seems to me that using Category column as a group (ID) column in GroupBy node is enough or I’m missing something?
Br,
Ivan
I considered that maybe this category column is not the main column and duplicate values of this column may exist in the real dataset. For example there might be a product column and this category column determines the category or categories of the products (so, several products with the same categories may exist). In that case the product column itself can be used as the grouping column (instead of these ID columns that I suggested).
And if there is no columns except the category, and if it was derived from another dataset, by creating these IDs we maintain the original order and later we can join the tables easily (even if the category column doesn’t exist in the first table anymore).
So I thought it would be safer to choose or create an appropriate column other than the category column itself to use as the grouping column.