Hello, maybe it’s a easy question. I’ve already search in the forum but I still cannot solve the problem. I want to split the cell, but I have difficulty to do that. Here is my data (example):
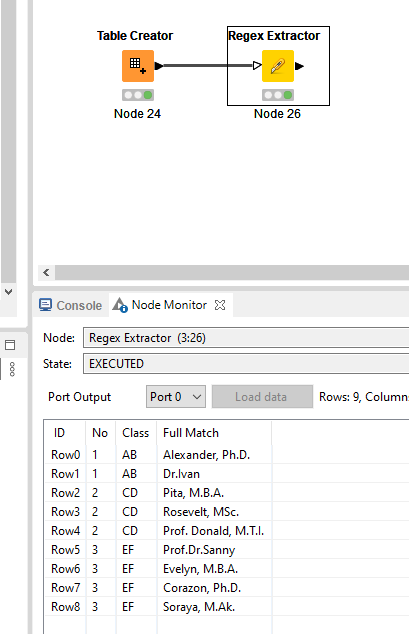
The names are written in many different ways which makes consistent cell splitting difficult. One way to approach it is through regex extraction by using the Regex Extractor node (Regex Extractor — NodePit ).
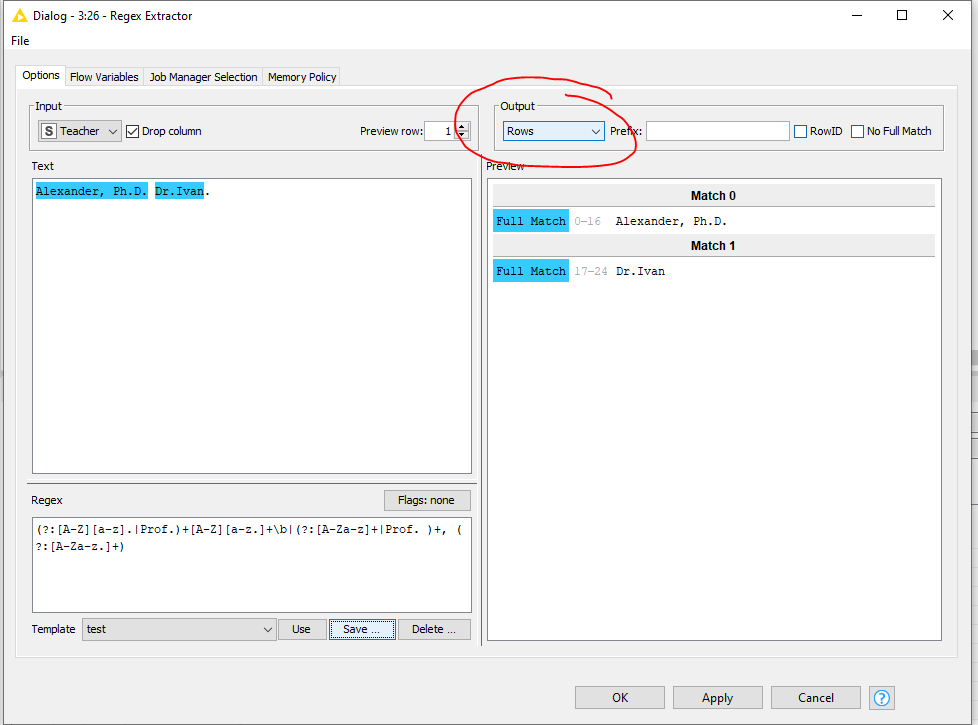
With this given small dataset, the following Regex generates the desired output: (?:[A-Z][a-z].|Prof.)+[A-Z][a-z.]+\b|(?:[A-Za-z]+|Prof. )+, (?:[A-Za-z.]+)
My question is, what did you choose ‘Prof’ instead of other title?
And what if the name have more than one ‘word’, for example Alexander Jovanka, Ph.D. My mistake that in my previous example, the name only one single name.
The ones that start with Prof were the only ones not captured by the main “rule” so I added that as a standalone OR statement. Hence also my comment about expanding the rule so it capture all cases. You can just keep stacking rules until you have captured all known nomenclatures.
That does not matter for the regex. Your latest output is a bit confusing though. You changed Alexander, Ph.D. to Alexander Jovanka, Ph.D. but the desired output stays Alexander, Ph.D.. is that correct?
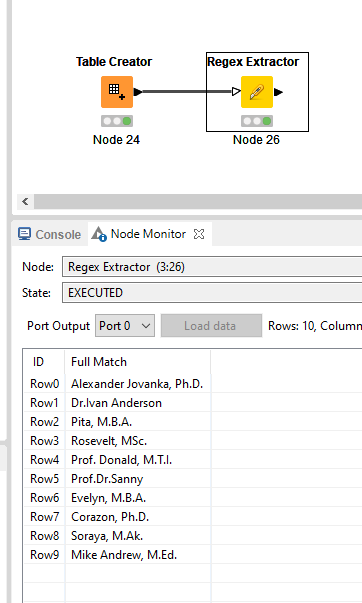
If you want to capture all names in full, which I tihnk your objective is, you can use: (?:[A-Za-z]+|Prof. |[A-Z][a-z]+ [A-Za-z]+)+, (?:[A-Za-z.]+)|(?:[A-Z][a-z]+[.][A-z]+[ |.][A-Z][a-z]+)
If there any dictionary or library where I can learn about Regex Syntax? Sorry if I’m asking too much question. I am newbie with this thing. Anyway, thank you for your kind reply. It’s really help me.
Hello @chococierry
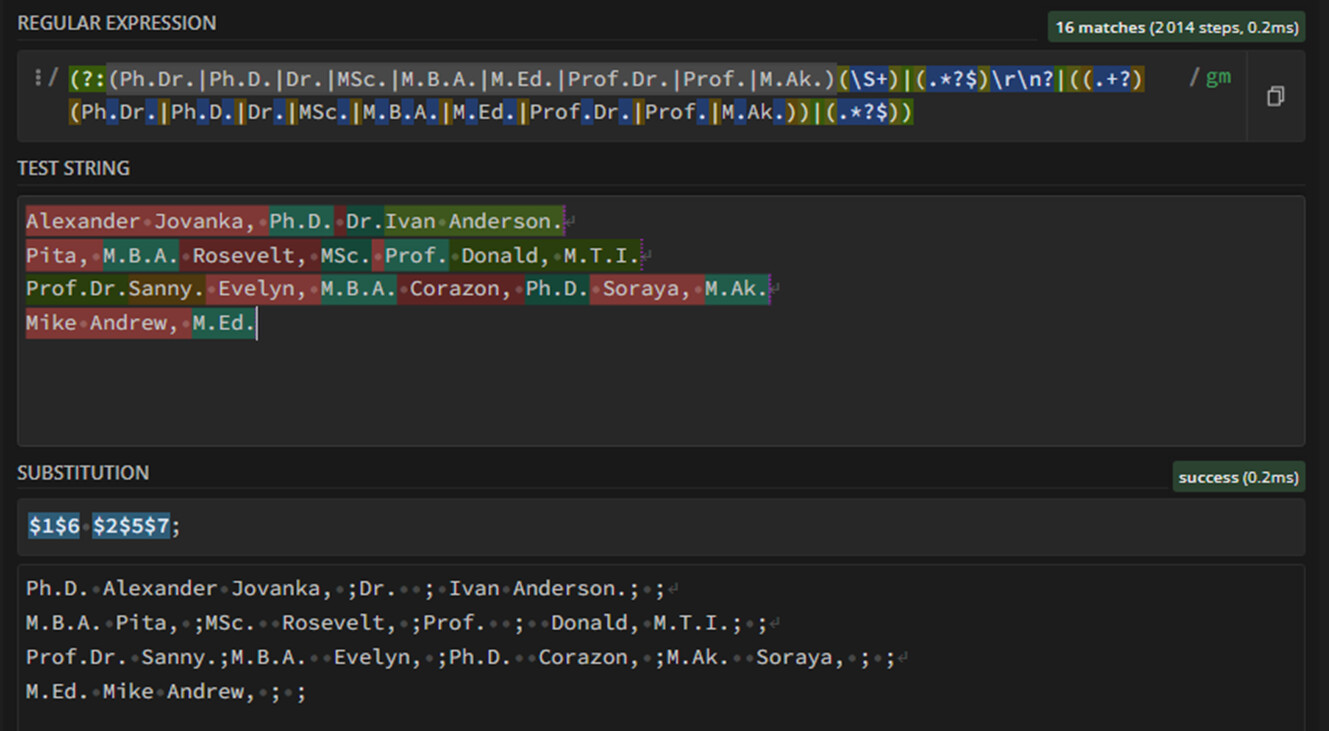
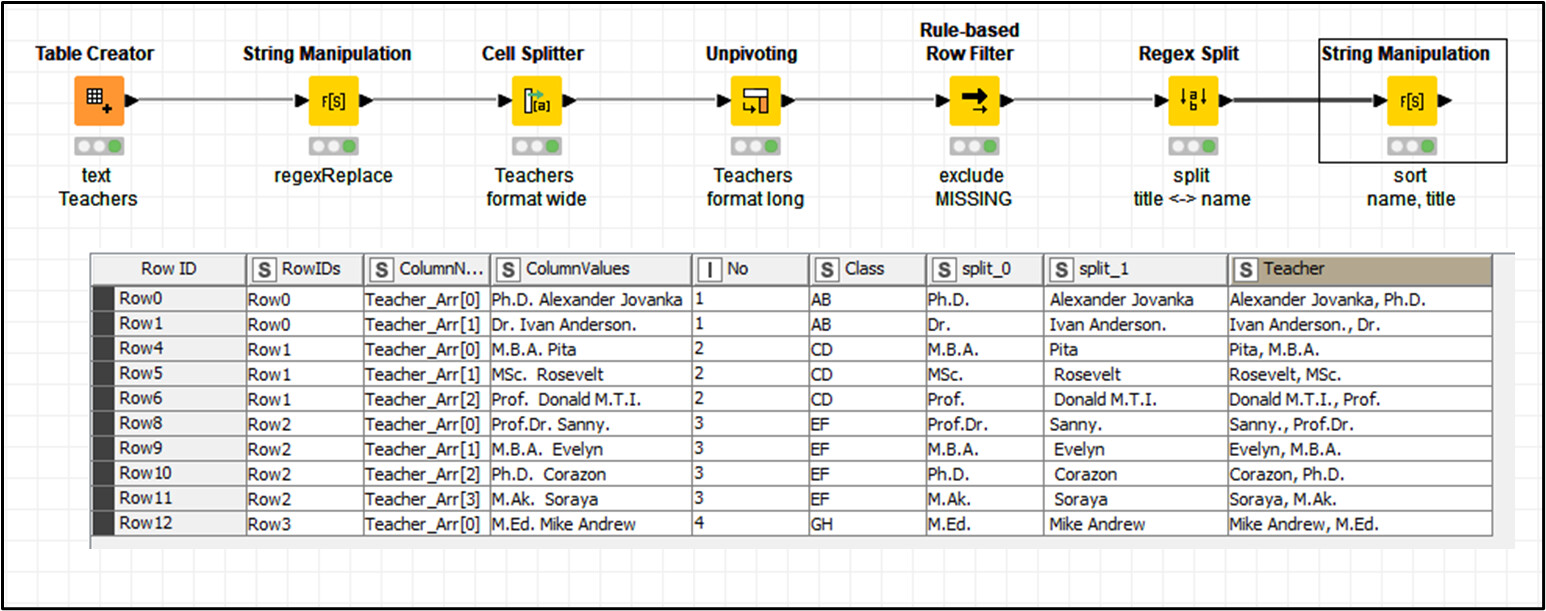
The current @ArjenEX proposed solution, requires some more regex, aiming to tie back the Teacher’s list back to number and class columns. Mi final solution isn’t either simple, i had to delete previous post because it didn’t cover all occurrences in the expected output.
As the source text is not ordered (name-title order, punctuations…), it implies some literally in regex coding. Some more causalities can happen in your real data.
Alternatively you can test the following code in a ‘String Manipulation’ node:
After this regex manipulation, you’ll have to split it (Cell Splitter, ‘;’), and unpivot resulting arrays. Because of the workflow complexity, I’m uploading it, so you can inspect and edit it.