I’m attempting to split a cell with US mailing addresses into 3 columns: City, Street, State, Zip. Every single item in the string is separated by a space.
All states are 2 letter abbreviations (NJ, CA, ND), and all zips are 5 digits (10001, etc.). They always represent the final 8 digits of the text (state, space, zip).
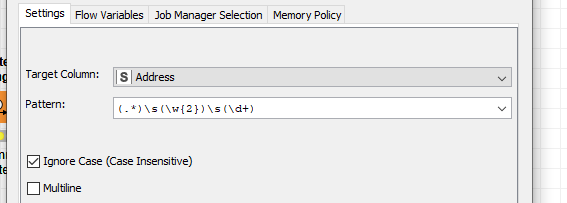
I’m able to split the first cell of the address with the space (between number and street) using the cell splitter, but the variability in the second group (which ranges from 12 characters to 31) causes issues on the State/Zip extraction.
I put this together based on your assumptions of the Zip and State being standard. Basically it splits those off and then treats the rest as the address. It’s very rudimentary… I’m sure there is someone who can chime in with a clever Regular expression which will do what you need in one node. I searched and tried some but couldn’t get it.
Thanks. I tried to view the file, but I’m getting some errors and it loads blank. The error message =
parse_address-2.knwf 4 loaded with errors
parse_address-2.knwf 4
Column Auto Type Cast 4:401
Loading model settings failed: Config for key “column-filter” not found.
State has changed from CONFIGURED to IDLE
State has changed from CONFIGURED to IDLE
Sorry about that. I put it together in another workflow I was working in and then copy pasted into new workflow. I think if you change your view to 50% you will be able to see it. Then you can ctl A to select all and you can move it to the upper left corner of the workbench.
Ipanzin…Thank you for the workflow. I had considered the reversal but was stuck on the management of the city names (from 1 to 4 names). Your flow addressed that. I had “solved” the issue thanks to j_ochoada, but the reversal eliminates 2/3rds of the nodes and is definitely much faster. Cheers!