Hi @anjeesanjeet
To be honest, I have to echo @aworker here. The dataset and the structure of the text is all over the place meaning building a solid ruleset is extremely hard.
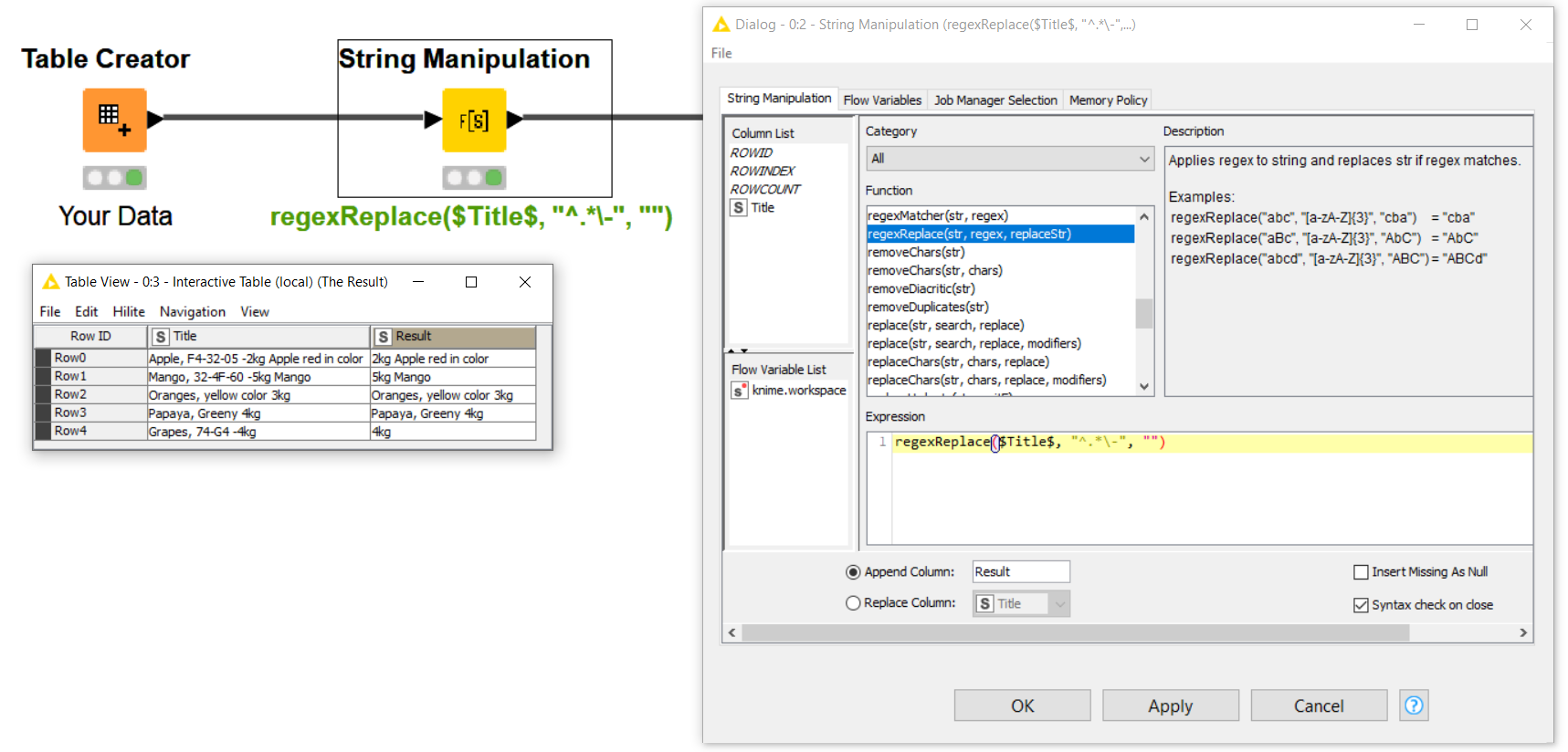
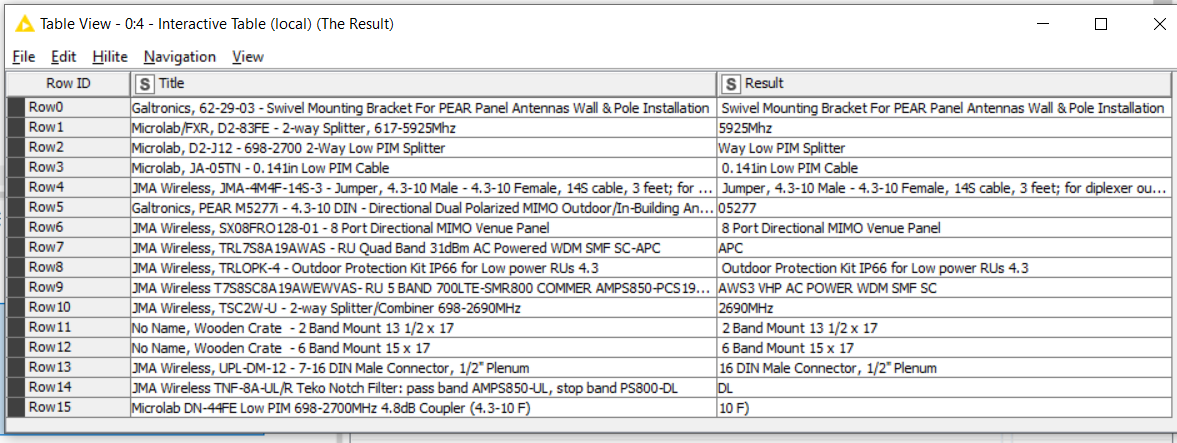
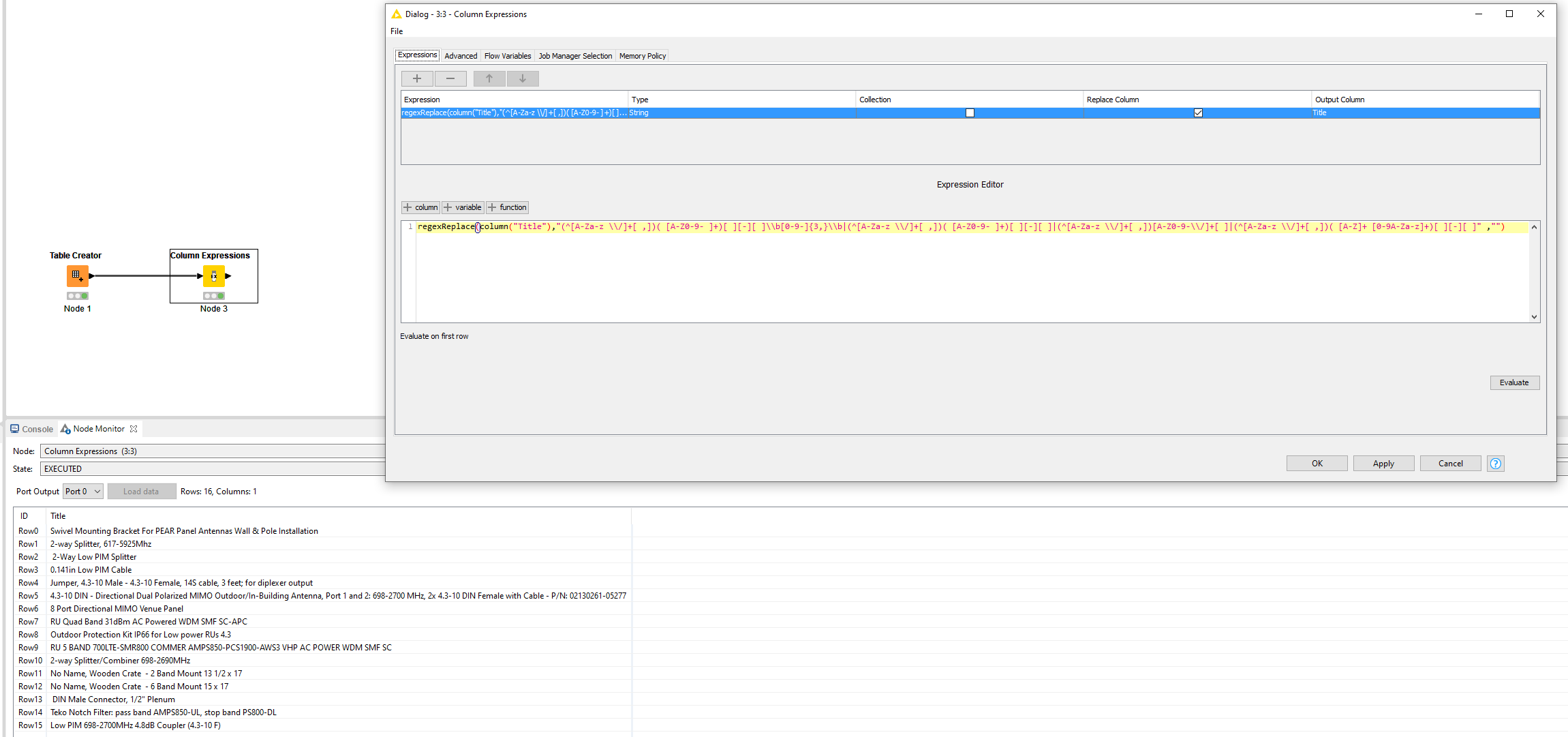
I did manage to get the expected output while using a Regexreplace function with: (^[A-Za-z \/]+[ ,])( [A-Z0-9- ]+)[ ][-][ ]\b[0-9-]{3,}\b|(^[A-Za-z \/]+[ ,])( [A-Z0-9- ]+)[ ][-][ ]|(^[A-Za-z \/]+[ ,])[A-Z0-9-\/]+[ ]|(^[A-Za-z \/]+[ ,])( [A-Z]+ [0-9A-Za-z]+)[ ][-][ ]
See results:
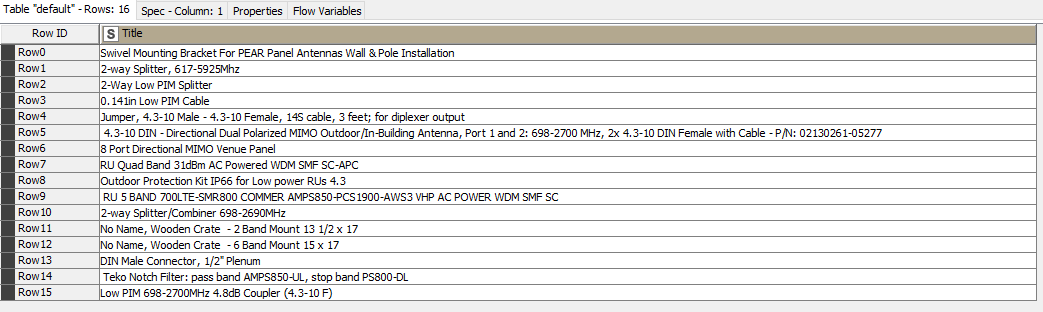
But again, the expected output is extremely subject to inconsistencies. To illustrate:
In row 2, 698-2700 should be omitted.
In row 5, 4.3-10 should be kept.
In row 13, 7-16 should be omitted.
The only way of capturing this is by saying that a substring of digits with a dash should be considered but excluded whenever it contains a period. I have to hardcode it’s length of 3 chars or longer by using:
\b[0-9-]{3,}\b
When omitting this, the Regex will also start to match sequences that it shouldn’t:
This is one example, but in a larger dataset with this kind of information, it’s quite likely that there will be other cases where the presence of a period should be omitted. As such, you would have keep stacking rule upon rule which is not very convenient.
Maybe a better Regexer than I am has a more efficient approach.
Mentioned Regex in KNIME:
parts data with regexreplace.knwf (15.2 KB)
To play around with this Regex: regex101: build, test, and debug regex
Hope this still helps in some way!