I’m hoping that you will find a way to change the source of your problem, but I thought this might be useful as an exercise anyway, especially if it turns out you are unable to change the source…
The attached workflow provides two potential ways of handling this. In both cases they strip the double quotes off the ends of each record. In the first part, it demonstrates reading the file, correcting it, writing it out again whereupon it can be read in by a CSV Reader in its now-corrected format. The thing to note here is that the CSV Writer is told not to write the column headers (because the first row of data already contains them!) so they’ll already be there. This process is repeatable… if on reading in, it is processing a file without double-quotes at the beginning and end of the record, it won’t be a problem, but it should be noted that a file containing well-formed CSV but with double-quotes on the first and/or last columns will get broken by this process! So beware!
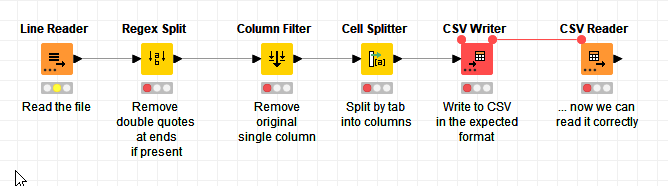
This in effect is a flow allowing you to “correct” the file, which might be useful as a more generic process should you encounter this issue again.
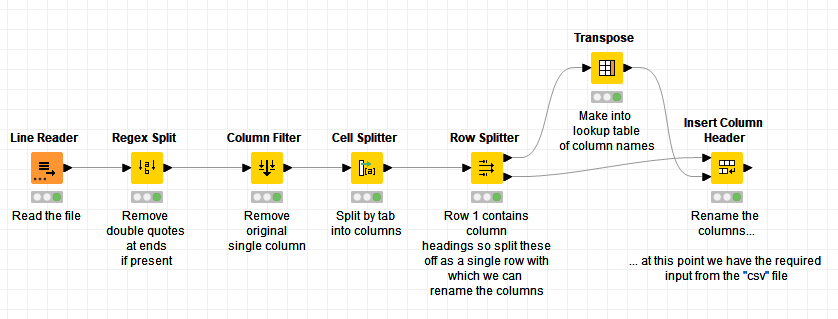
In the second part, it demonstrates how (instead of overwriting the original file) it can simply do the necessary data correction, and then fix the column names on the table. This is the better and safer option if you don’t need the file fixed!
IReading CSV that is incorrectly formatted - two options.knwf (1.2 MB)