There are several event names + dates that I need to split.
I have created a reference table and joined the data but that is quite time consuming for large quantities of data. Is there an alternative solution? Can you help, please?
Hello @svijay
Assuming that your text start with ‘event’ separated with comma - space, and ‘date’ format afterwards starting always from day; You can test with the following code in a ‘Regex Split’ node:
Trying to deliver a clean separator its good to add OR alternatives, aiming to remove the comma in one step when there is a case:
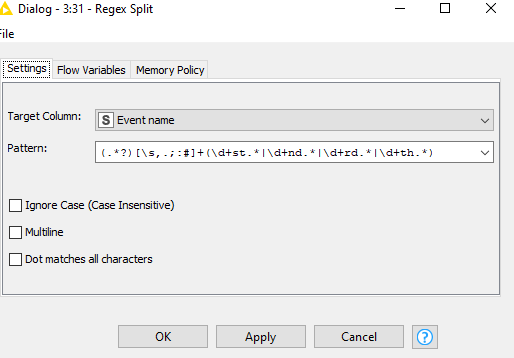
(.*?)[\s,.;]+(\d+st.*|\d+nd.*|\d+rd.*|\d+th.*)
with this code will split any of those characters included in square brackets. If you find more special characters in the separator that you want to exclude, just add them into the code.
Hello @svijay
No, it won’t affect. So you can drop your ‘colon (:)’ within the square brackets.
It does only affect the symbols together to the last separator group space/es (\s+) plus special characters in any sequential order, and as many as keep in the + (see example):
Hi @svijay
Based on the picture in your description you are selecting $Event name$ column, that is the already split sample. You would need to select an ‘splitable’ column. Otherwise you should provide a testing sample in a file or a shared workflow.
Maybe your text have some unicode hidden characters, that are not included in the regex. By providing few cells of the text column, we could inspect those problems…
Hi, so I have figured out went wrong. The above formula works very well for the example I shared with you. However, that example was using dummy data. The actual data is sensitive so I cannot easily share.
The actual data consists of multiple event names so I’m now wondering if the (\d+st.|\d+nd.|\d+rd.|\d+th.) is ok to use if the event names are different? As I think the code might not be applicable to different event names. Thank you so much for all your help!