When a category column values are at or above a threshold, say .667, then I want to split away all columns related to this test column.
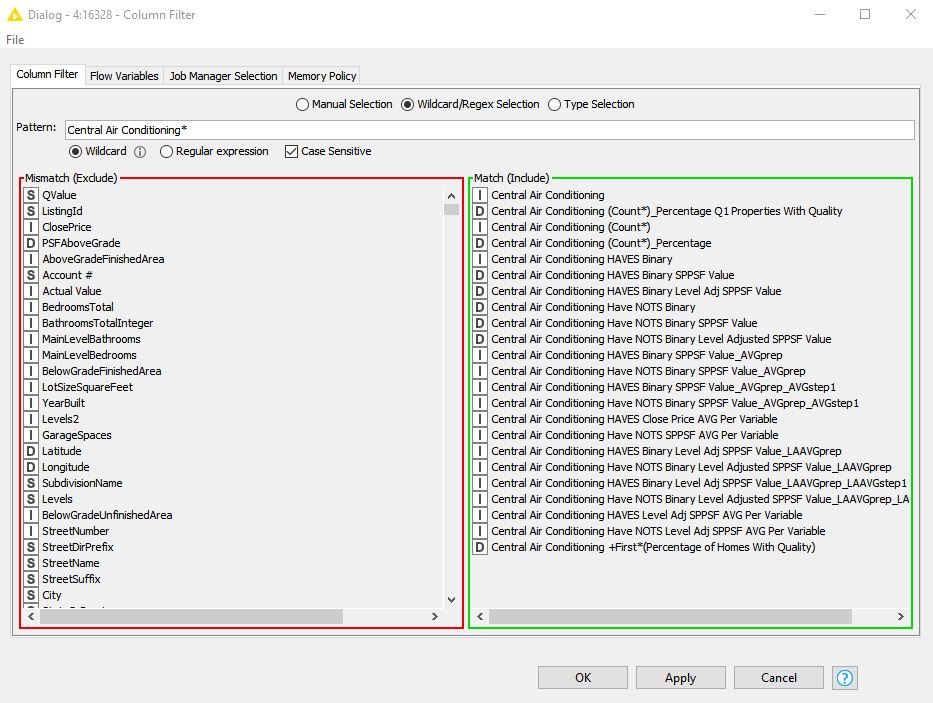
For example, when the category column “Central Air Conditioning +First*(Percentage of Homes With Quality)” is at or above .667 I want to split this column and all its related columns to a new table (see below)
Where this gets really complicated is there will be multiple category columns hitting the threshold and with each new group of data tested the category columns and the thresholds change. So manually setting up the Column Splitter Node will never work in the long run.
If you have some guidance on automatically identifying each category column reaching the threshold then splitting it and all of it’s related columns to a new table I would appreciate your suggestions. Attached is just one of the many data sets I need to perform this on. Thanks
Is every column with “+First*(Percentage of Homes With Quality)” in the header going to be a category column? If not, how are we to identify category columns?
Is every column with “+First*(Percentage of Homes With Quality)” in the header going to be a category column? If not, how are we to identify category columns?
This is the column I use to measure against the threshold. If you look at the very last line in the graphic above you see “Central Air Conditioning +First*(Percentage of Homes With Quality)”. So the threshold column has the key term “Central Air Conditioning” and the suffix “+First*(Percentage of Homes with Quality)”. So we test this column for threshold and if it is at that or above we want to move all related columns (example in graphic above) starting with “Central Air Conditioning” plus whatever suffix may have gotten attached during many processes. All threshold test columns will have a “main term” plus the suffix "+First*(Percentage of Homes With Quality). However, the main terms available and the numeric value will be different for every different data set.
How are the thresholds for each being chosen? I have arbitrarily chosen => 0.67 at this point.
What do you want to do with the new tables? The new tables are used for additional KNIME processing immediately after the step we are working on.
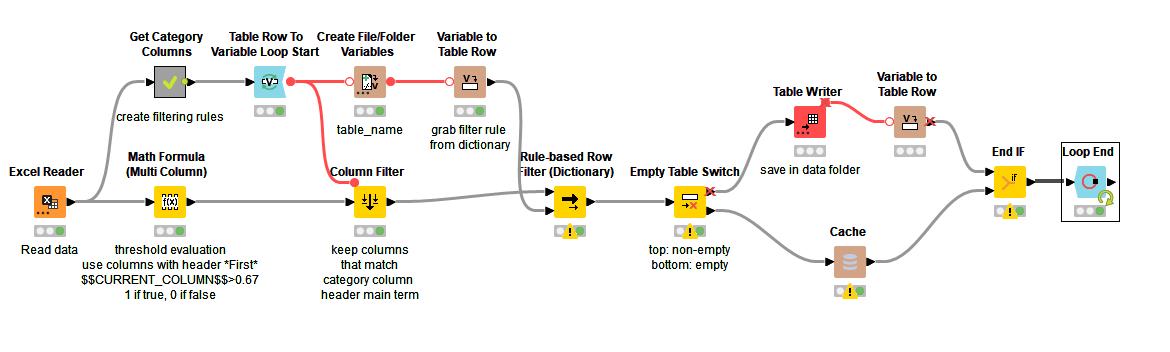
Here’s a workflow that examines all the columns that have “First” in the header (the category columns) and compares the values therein to a threshold value.
Then for each category column,
keeps only the columns whose headers match the main term from the category column
saves the data where the category column is above the threshold, with every category being saved as a separate table
removes data where the category column is below the threshold
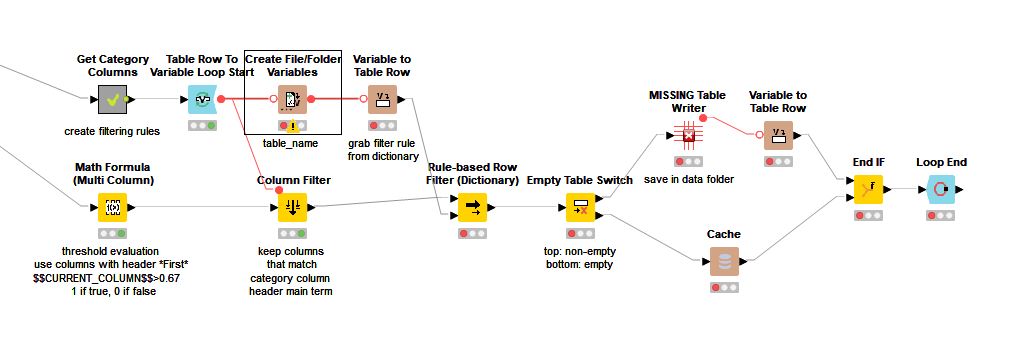
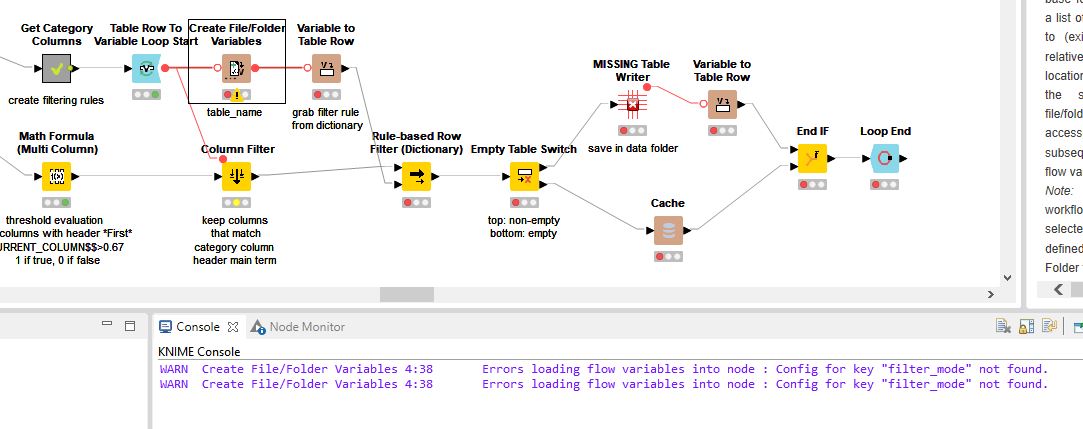
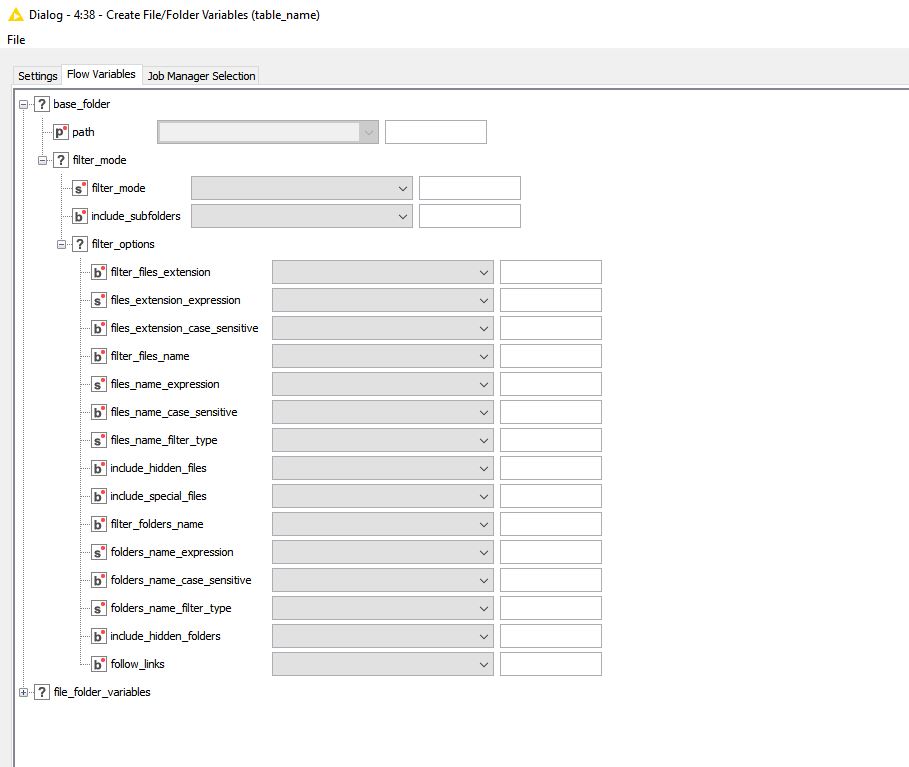
@elsamuel I am good to the point where the workflow hits the Create File Folder Variables. Here the flow fails. I am using the exact same data you had, except now in my live full-scale workflow. Did something get reset during the import? Please see below, thanks
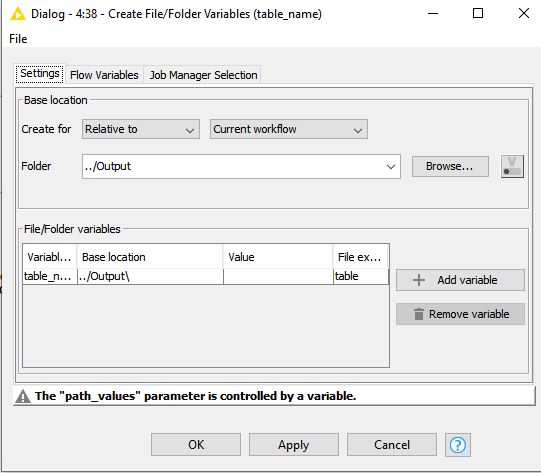
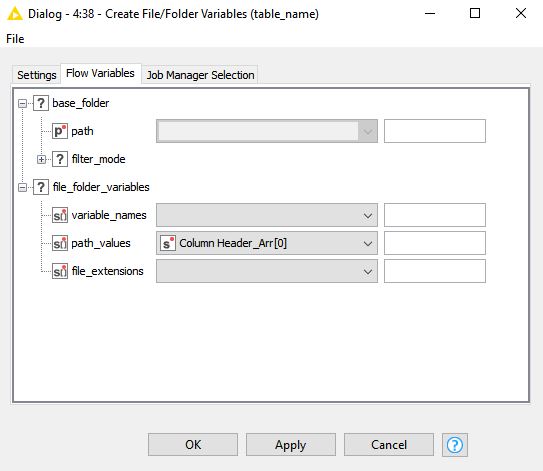
Go to the Flow Variables tab of the configuration for the Create File/Folder Variables node. Under base_folder, click the plus next to filter_mode. What shows up?
I’m using 4.4.1 and I don’t have that option.
This post suggests that it’s probably a version issue.
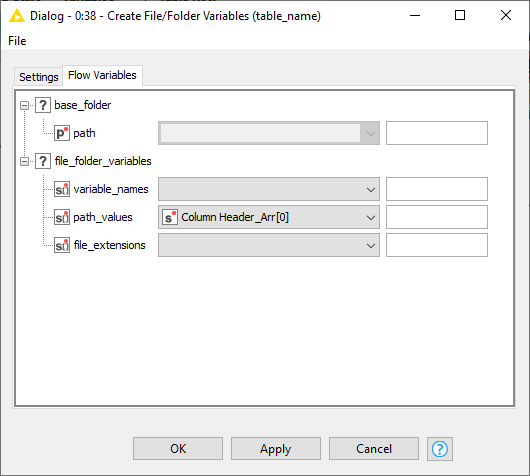
@elsamuel Below is my flow variables tab. I am using version 4.3.4. I intend to upgrade to 4.4 once I get a new computer. Right now I have this massive workflow in this version and anticipate all kinds of things breaking if I try to upgrade. thanks
@Daniel_Weikert , yes, I understand, but with thousands of nodes in my workflow based on the prior version I am not in a position to attempt converting everything over to 4.4 right now. thanks
What happens if you remove the variable from the path values field? Does the node run?
What happens if you re-add the variable to the path values field after that?
Worst case scenario, you could create a variable called filter_mode with the value FOLDER, and apply it in the filter_mode field of that Create File/Folder Variables node.
I’m not sure why the filter_mode is in the flow variables (and it’s probably why it’s no longer there in 4.4).
As you know, any flow variables simply allows you to configure something dynamically, meaning that these configurations exist as settings where you can set them as static values.
However, I don’t see the filter options from the Settings tab from @smithcreed 's screenshot - and it does not make sense to have them. This type of filter would be if you were reading from a folder, while here you are trying to create a variable.
Upgrading to 4.4 would certainly fix this.
If you can’t upgrade, I see only 2 options:
Create this variable manually (String to Path (Variable) node)
or
Create some dummy variables and assign to the filter_mode
@elsamuel , so I played with changing the base location from relative to, to local file system; it didn’t help much. But then I reset it to relative to as you had it. Now it processed…
Now the rule-based row filter (dictionary) creates an empty table. WARN Rule-based Row Filter (Dictionary) 4:57 Node created an empty data table.
The missing table writer node also displays the error WARN MISSING Table Writer 4:31 Node can’t be executed - Node “Table Writer” not available from extension “KNIME Base nodes” (provided by “KNIME AG, Zurich, Switzerland”; plugin “org.knime.base” is installed)
Now the rule-based row filter (dictionary) creates an empty table. WARN Rule-based Row Filter (Dictionary) 4:57 Node created an empty data table.
This is not a problem. The first set of columns failed the threshold test. You can confirm this for yourself.
Just run the entire loop.
The missing table writer node also displays the error WARN MISSING Table Writer 4:31 Node can’t be executed - Node “Table Writer” not available from extension “KNIME Base nodes” (provided by “KNIME AG, Zurich, Switzerland”; plugin “org.knime.base” is installed)
Replace the workflow’s Table Writer node with the Table Writer node you have installed.
You’re going to need to convert the folder path variable to string, since that old node can’t handle path variables.