Hi everyone!
I work with lots of data during my PhD and want to create a workflow to separate one huge .csv file into multiple small ones by column pairs of two.
My KNIME version is KNIME 4.7.4 on a Windows 10 Education.
Input Data:
- My measuring instrument exports a .csv file containing 2 columns (1 x-variable, 1 y-variable).
- When I program it to measure time series (e.g. 288 spectra consisting of an x and y column each), it saves them in columns next to each other in the format: X1Y1X2Y2X3Y3… and so on.
Desired Output: I want to split the data in the time series .csv file into separate files for each iteration, so one .csv file with column X1Y1, the next with X2Y2, and so on.
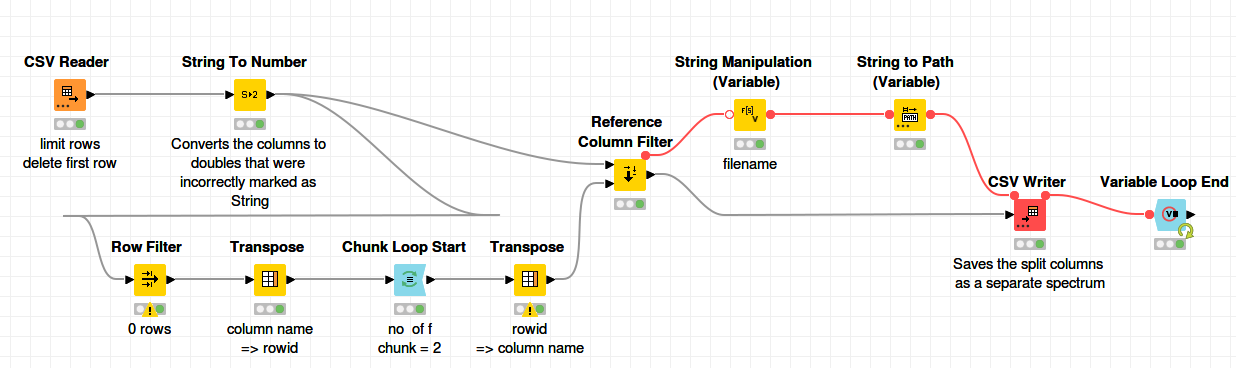
I have gotten pretty far, I think, but the workflow outputs the same first two columns (X1Y1) in 288 nicely numbered .csv files instead of giving me 288 different individual files containing one spectrum each of the 288 different spectra saved in the original table. I have included my TestData and workflow here:
My best guess is that the top table outputted by the split table node in the loop (the remaining columns X2Y2X3Y3…) is not handed back to the beginning of the loop, so it always starts with the original table and splits X1Y1 off to be written in a new file with a new name 288 times…
Can someone confirm my suspicion and maybe help me solve the problem?
Ideas I have tried but not succeeded in implementing:
- Would a recursive loop help instead of a counting loop? With which end condition?
- Can I use a counting loop and somehow tell the loop or split column node to always use the next two columns for splitting off and writing to a file? With a variable referencing the current iteration, maybe? Example: “*3)” for the fourth spectrum (X3Y3). I tried using the current iteration variable instead of 3, but it didn’t accept the variable/didn’t choose any columns.
I feel like I am missing some very obvious solution to this problem. I know there is a Chunking Loop, but as far as I understand it only works for rows, not columns?
I appreciate your input. Thanks in advance!
Andra