Hello everyone,
I’m trying to split a table, which contains driving data of a race track, but I cannot reach my goal yet. The table contains 4 columns: timestamp, latitude, longitude, velocity. And then, there are multiple thousands of rows for each timestamp.
From lat and long I already was able to set up the finish line of the track.
For instance, I know that the data contains 4 rounds. These 4 rounds shall be splitted into separate tables, one table per round.
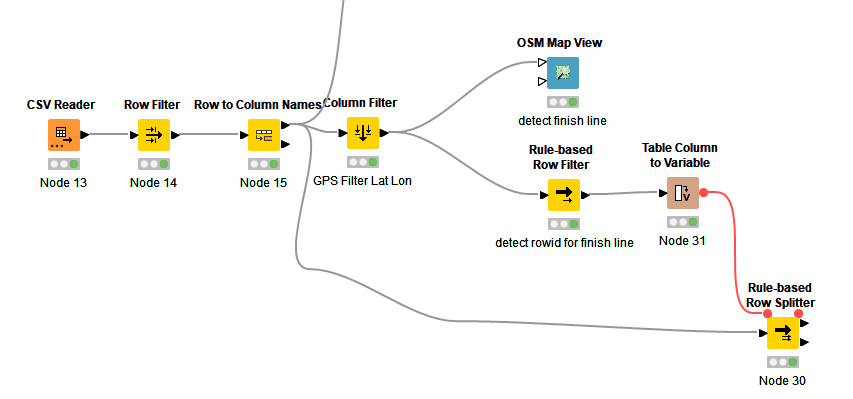
With rule-based row filter node I filtered out exactly the 4 rows where the driver passes the finish line. Basically, the result of the filter is a simple table with those aforementioned 4 columns and now only 4 rows.
But now I dont know how to use this information to split the original table into 4 separate tables.
I’ve tried everything I’ve found here in the forums like Row Splitter, Table Splitter, Reference Row Splitter and so on, but I seem to be to stupid to make proper use of them.
Do you have an idea? Any help is highly appreciated
I’ve just started to work with knime and downloaded it today (v5.2.3) , so please be kind if the question is too stupid.
@timkrych Welcome to the KNIME Community. Could you upload your workflow including data? That will make it much easier for potential helpers to assist you.
Hi rfeigel,
thank you for your help. Attached you can find the workflow and the raw data.
Best regards,
Tim KNIME_project3.knwf (15.4 KB) track_test.csv (1.7 MB)
I’m looking at your data and am pretty confused. How did you establish the location of the start/finish line? What do mean by “rounds”? Are these laps around the track? I grouped your data by lat/lon and there are no repetitions which is confusing if this is a closed circuit. There should be repetitions if the car passed the same point on the track multiple times.
Hello,
sorry for bad English. Yes, I meant “laps” around the track. From visualizing the driven route via the OSM Map View, I zoomed into the position of the Start Finish Line and manually wrote down the values. Thus, I get the range of lat/lon where the finish line shall be. After that, by using the filter, it turns out that 4 rows contain the specific information. This was proof to me, that the car passes the finish line 4 times.
I think, there are no exact repetitions by the resolution of the monitoring. With 10Hz and depending on the lap time the exact position of the finish line may not be monitored.
These are sample data from a transponder. Please let us assume, that the finish line is within the mentioned range, since I don’t know better.
What would be your advice to split the table now at those 4 row IDs?
Could you please describe your business case? Don’t tell me what you’re trying to do in KNIME, just describe what you’re trying to accomplish. Also i don’t understand your time data. If these are times at various points around the track for four laps shouldn’t the first pass of the start/finish line be 0?
If you were successful in separating out one of the tables using the rule based row filter, and I noticed the splitter version missing from your attempted nodes list… Have you tried stringing together a series of Rule Based Row Splitters? That is typically how it is done. As the splits continue in a series the logic typically gets easier.
Hello, thank you iCFO and special thanks to rfeigel! This is, what I did not realize before! I even adjusted a little bit your workflow by generating a flow variable to split the tables.
Now I will try to improve this by generating a loop for not manually writing down the variable for the rule based splitter. But for this I still have to make some research here in the forum.