I have a problem with splitting texts I imported from an Excel-Sheet.
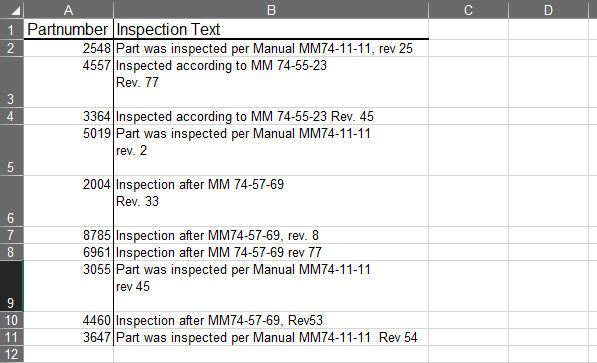
There is a column called “Inspection Text” which contains information. An Example is shown in the following picture:
There are two kinds of information noted in the “Inspection Text” column. First the maintenance manual chapter (two letters, follwoed by six numbers) and after that the corresponding revision date. The information are seperated by spaces and line breaks. Unfortunately there sometimes also dots included.
I tried to split the information using the Regex-Split node but I´m not able to wirte the correct pattern.
Can someone help me to code the correct / necessary regex to split the text in two columns?
Hi @Martin_23 , I’ve tried to solve the problem here split_string – KNIME Hub. I don’t know why, but I couldn’t manage to make the Regex Split node work (in Multiline mode) on cells with line breaks, so I had to insert a “String Manipulation” node before it.
Hope it helps
thanks for your answer. I thought about that as well but couldn’t manage to set the String Manipulator as I needed to. I’ll try your advice and “install” the Manipulator as you did. I’m optimistic that it will work out.
that looks way easier than what I was trying. I use Knife for work and first have to ask if I can download the extension which includes the Regex Extractor on the companies device.
But if they give me green lights I’ll give it a try directly.
If there are some more issues with that I would get back at you if you’re okay with that.
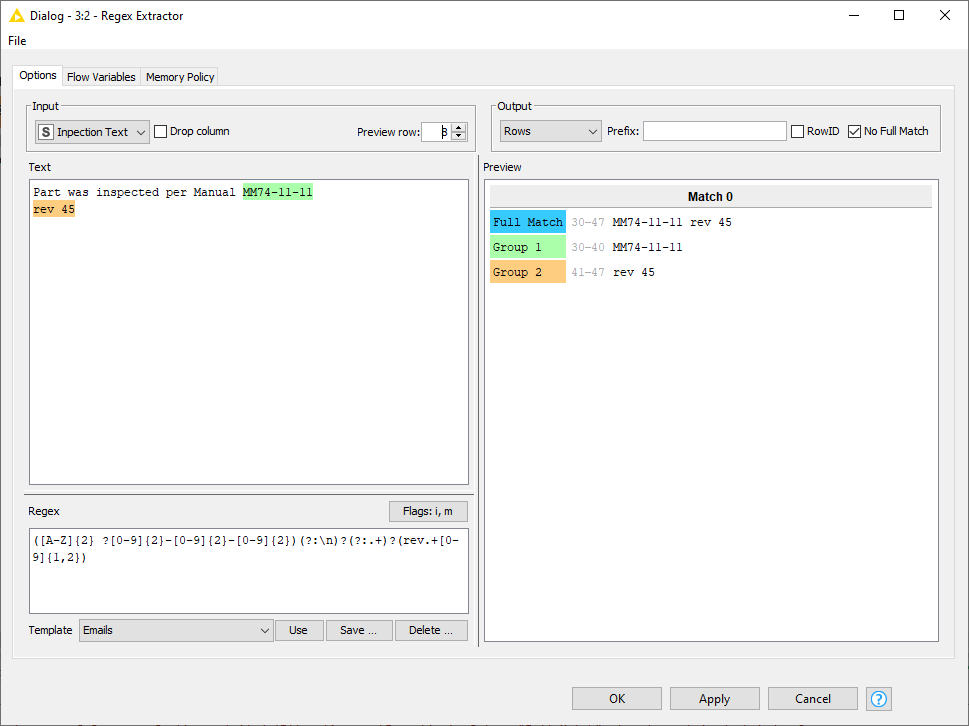
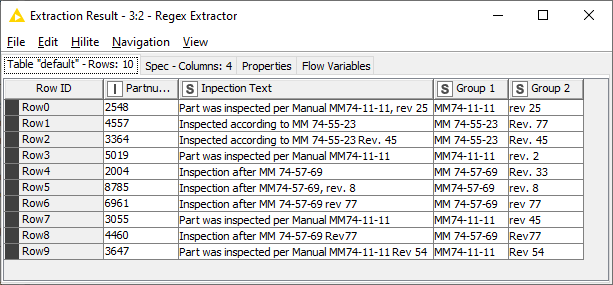
I’ve installed “Regex Extractor” and it’s much more powerful than “Regex Split”. In both nodes, however, the char “.” doesn’t match end-of-the-line char, so one has to insert it explicitly :
^MM.*(\d\d-\d\d-\d\d).*[\n\r]*rev.*?(\d+)$
Anyway, I think it’s safer to replace line breaks with blanks before the regex node - because you don’t know where exactly line breaks are - and to strip leading/trailing blanks (just in case)
Yes, I think you´re right with that. I already applied for the palladian extension so that I´ll have access to this node in the next few days.
But in the meantime I´ll continue with the string manipulation node.
Did you also use the function “replace” ? I tried it an somehow the “.” or linebreaks where not replaced. Did you use “\n” to search for linebreaks and " " to replace? Or are these wrong expressions?
The formula I suggest you use in the String Manipulation node is
regexReplace(strip($string$), “[\\n\\r]+”," ") strip($string$) removes leading/trailing blanks "[\\n\\r]+" means “sequence of at least one of the characters enclosed inside the square brackets (new line and carriage return)”. In Linux environments, “\n” matches a newline. On Windows, you need “\r\n” and on old Macs you must use “\r” (or so they say).
This way you can replace one or more line breaks with a single space