I'm new to KNIME and I run into a strange issue with the Stanford tagger.
I want to analyse a set of text regarding the Tchernobyl disaster.
I've feed the corpus of text into Stanford tagger node (french tagger is selected), I then use the bag of words creator + Tag filter with FTP selected (French TreeBank I guess).
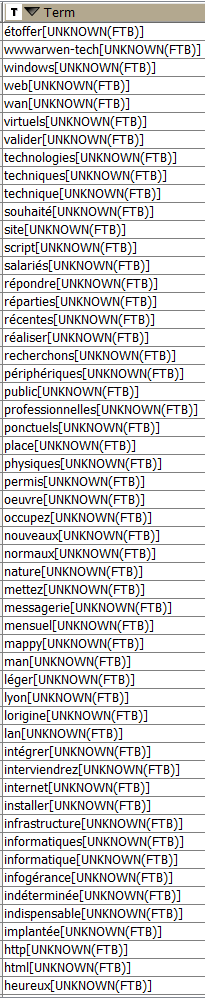
When I look at the results of the Stanford node tagging, a lot of very common name are marked as UNKNOWN. Sometimes the exact same verb will be differently tagged.
Does anyone have an idea why it happens ? What did I miss ?
Any help with french text tagging is warmly welcome !
the assigned tags, when using the French model in the Stanford tagger are French Treebank tags (FTB). Is your text proper french natural languge? The model was trained and thus works best on proper natural language.
it seems that our FTB implementation does not fit to the FTB tag set that is used by the POS model.
It should definitely not look like that. I will have a closer look.
I had a closer look. The standard FTB tag set that we’ve implemented is not used by Stanford CoreNLP. They use the modified FTB set (Crabbé et al., 2008). I created a ticket to add this particular tag set.