Hi there,
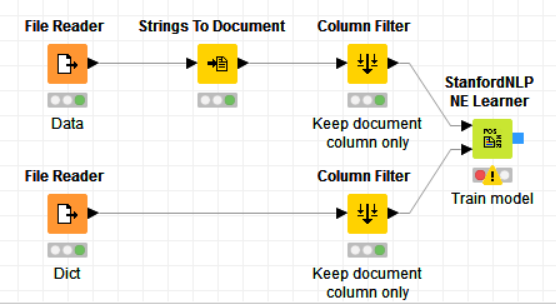
I am lost in the input format of the document and dictionary of StanfordNLP NE Learner.
What am trying to do is to train my own NE learner and then use the tagger to performance prediction.
I have read some related posts from here:
and try the example: 08_Other_Analytics_Types/01_Text_Processing/14_NER_Tagger_Model_Training
In the example, the input dictionary contains bunch of person’s names and the Learner regards all the names appear in the document as Person. However, this might work for people’s name but if every word in the dictionary are regarded as the same tag, there might be a problem since Just because there might be ambiguous names.
For example, “White House” can be referred as “The US government” or “a exact location” depending on the context.
Appreciate any help with this problem. Thanks in advance.
the StanfordNLP NE Learner can only learn models that tag entities with one tag, e.g. firstname, localtion, etc. For multiple tags, multiple models need to be trained.
The input of the learner node is 1. the corpus of documents containing also the NEs to learn 2. a dictionary of all NEs. These NEs will be tagged in the corpus and then the tagged corpus will be used for training the model.
To use the model the StanfordNLP NE Tagger node can be used.