Hi @carlos_amaya,
I see that I may have overcomplicated the requirement, and the solution may be more simple but since I had worked on this already, I will post it anyway!
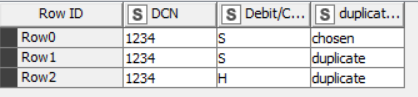
If my understanding is correct, you are saying that:
- a “duplicate S” row is no longer considered a duplicate if there is a valid H row that reverses it, and
- an H row is considered valid if it exactly reverses ONE S row
- a duplicate S row that is not reversed is still considered invalid
- an H row that has no corresponding S row is considered invalid
At the end you want to flag all S rows that are duplicates but not reversed, as well as all H rows that are incorrect reversals.
The solution presumably needs to take into account that there could be multiple H and S rows for any given DCN and that it must take into account the idea that a single H row can only be considered a reversal for one of the S rows. This adds some additional complication with ensuring that we count reversal only once.
Extending your example data set to cover a number of issues, I looked at the following:
| DCN |
Reference |
DETAIL-FIELD-A |
DETAIL-FIELD-B |
Debit/Credit |
comment |
| 10349347 |
513477894 |
312 |
GAL |
S |
valid |
| 10349347 |
11816177 |
312 |
GAL |
S |
valid because revered |
| 10349347 |
413343494 |
-312 |
GAL |
H |
valid reversal |
| 123 |
27953295688 |
200 |
ABC |
S |
valid |
| 123 |
45093121452 |
200 |
ABC |
S |
valid because reversed |
| 123 |
33481082957 |
200 |
ABC |
H |
invalid reversal |
| 456 |
67057236481 |
30 |
XYZ |
S |
valid |
| 457 |
57581440870 |
-30 |
XYZ |
H |
invalid reversal (wrong DCN!) |
| 123 |
432646278 |
200 |
ABC |
S |
invalid because duplicated and not reversed |
| 123 |
54543643 |
-200 |
ABC |
H |
valid reversal |
I have added a comment to the right showing what I believe should be the outcome. Where there are reversals, it is arbitrary which is actually considered the valid remaining S row, as there is no stated rule for that.
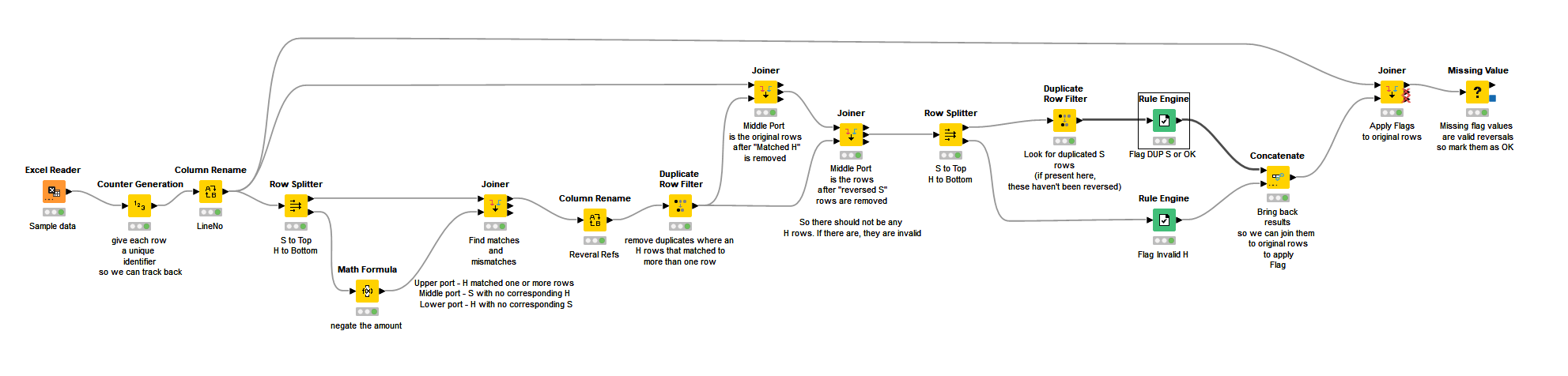
I think that the attached workflow will achieve this, and perhaps can be adapted to your data. The numeric data in this workflow are integers. If your real data is non-integer you will need to adjust it accordingly; in particular the math formula node that negates the result is specifically configured to return an integer and would need to be modified or else the joins will fail.
Validating rows for duplicates and reversals.knwf (52.6 KB)
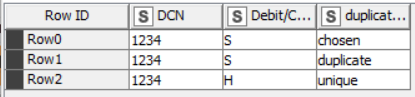
The end result is this:
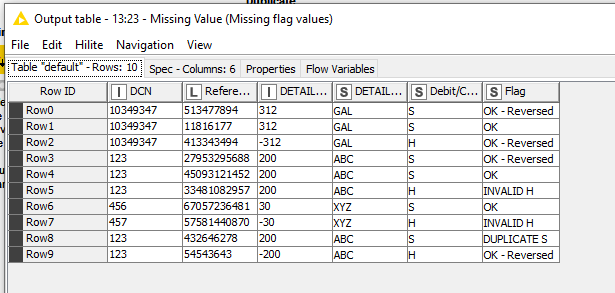
My Flag column is currently better described as a “Comment” column, but you can adapt this to simply return OK/FAIL or whatever you require. I left it like this as it helps with testing.
You will note that the choice of lines that are considered reversed differs to my “test” table listed earlier, because it arbitrarily matches the S and H lines on a first-match basis, but the net result should be the same.
If it is possible for a single H to reverse more than one S, or a combination of H lines reverse a combination of S lines, then the solution would unfortunately become a great deal more complex. (I have done something like that before but I had to use some java to simplify the process, and it took me over a week to write! I hope therefore that this “simplified” solution helps.