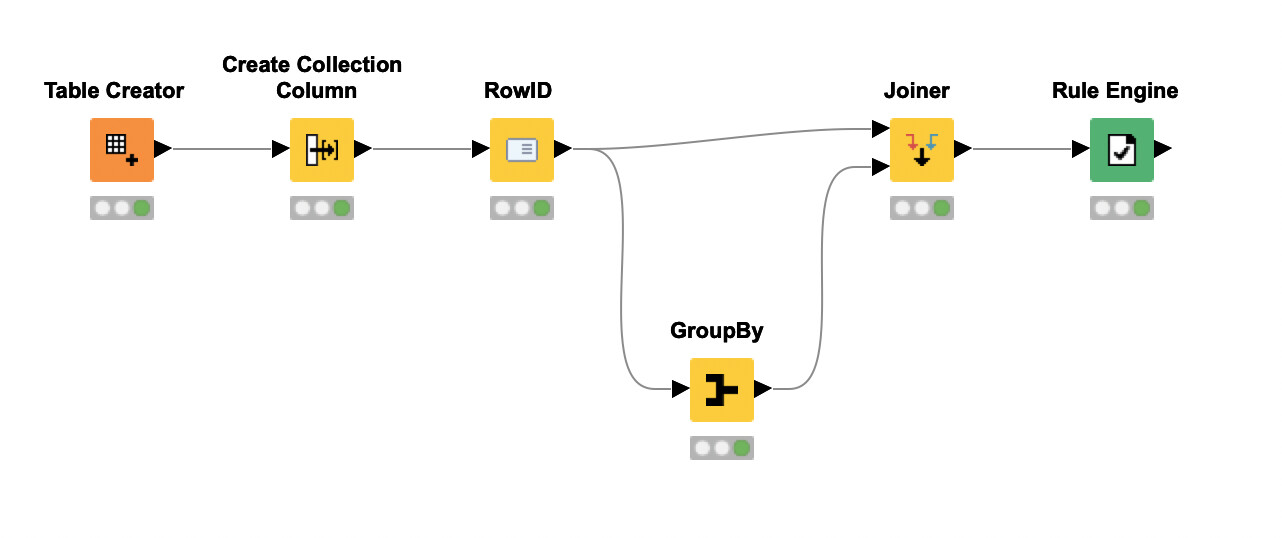
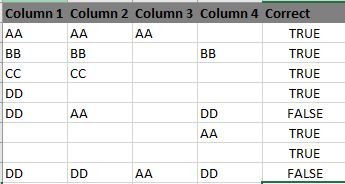
I want to check if a string is the same but ignore missing values. An example is the following: Unbenannt|345x184
I cannot use the rule engine node, as this will not ignore the missing columns.
I could build a unique concatenate of each line and count the number of unique strings. But don´t know how to do this. Any ideas?
Hi @Alkaline , input data and workflow usually helps to look into the challenge
Off of my head, you can split your data into rows with missing values, call this set D1, and rows with values, call this set D2, and apply the rule engine that you intend to do on D2, and concatenate the results with D1
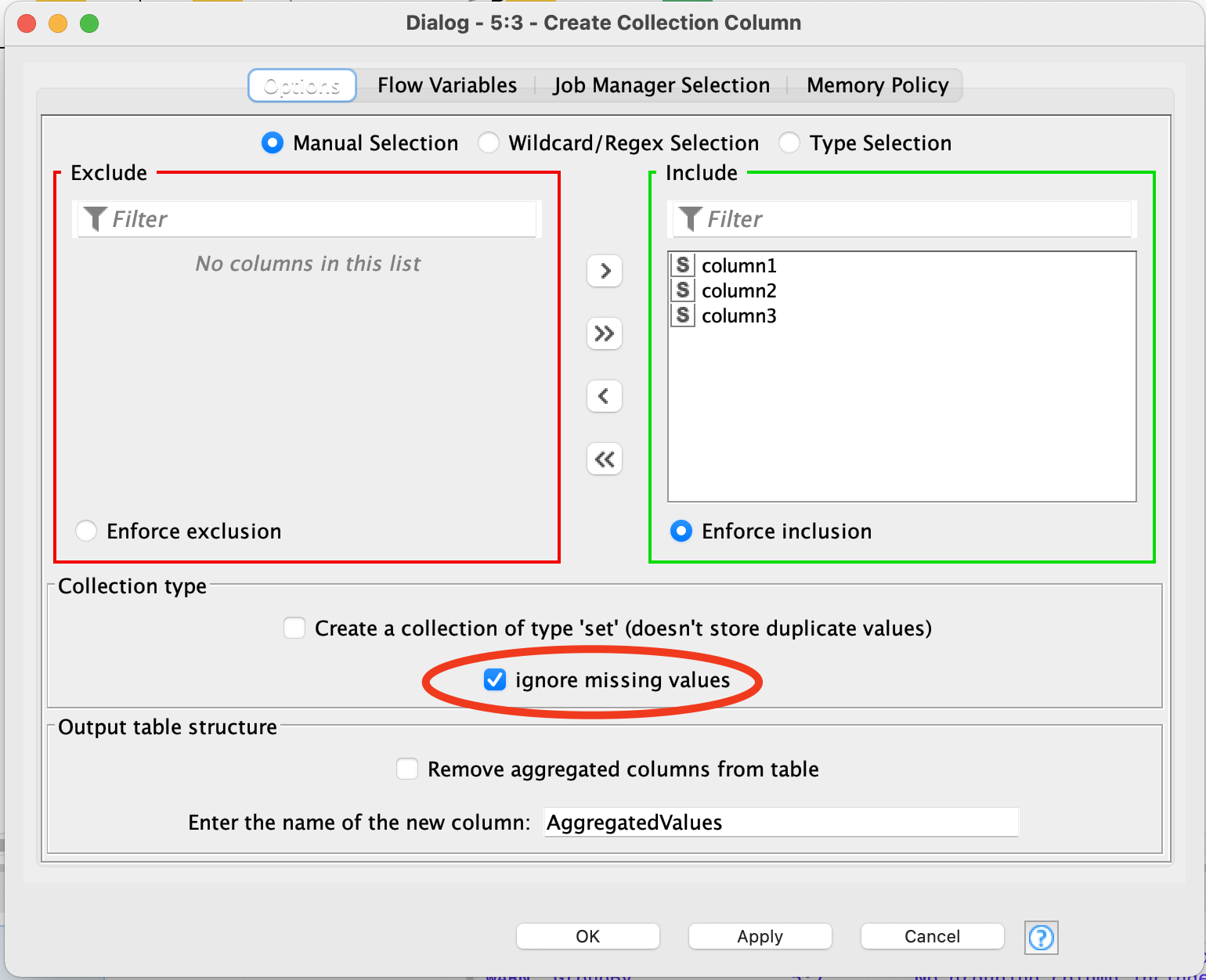
thank you! This is exactly the solution I was looking for. I did not know the create collection column node!!!
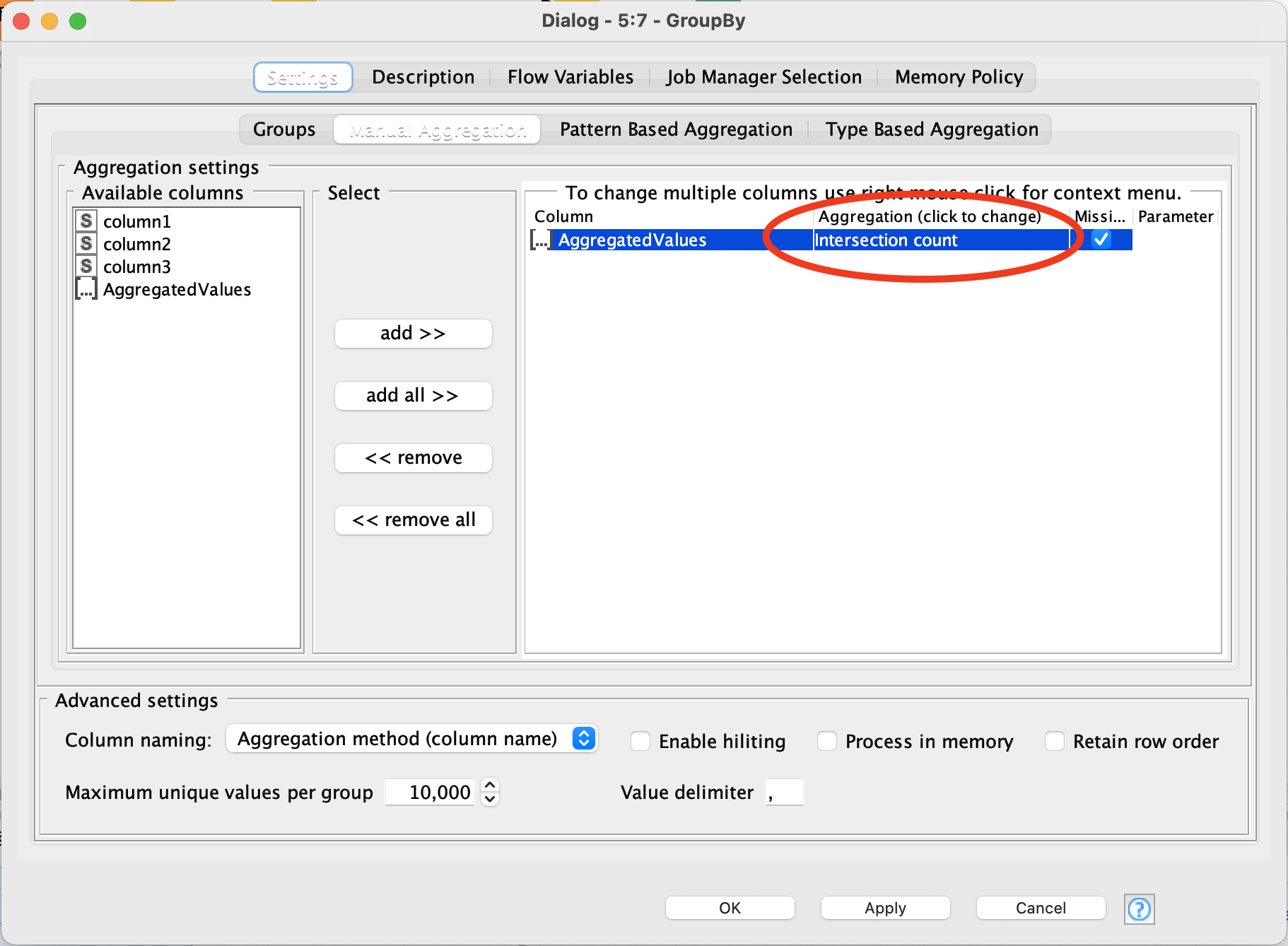
Solving this with filters would be challenching, as there are different possibilities with/without data, so the Collection column node is great. I can here also group by “Intersection” and use the “Split collection column” node, to recieve the unique string.
if I got it right your outcome depends on number of unique values across multiple columns. If that count is 1 or less than outcome is true otherwise outcome is false. With Column Aggregator node you can get that count



{kind=link}