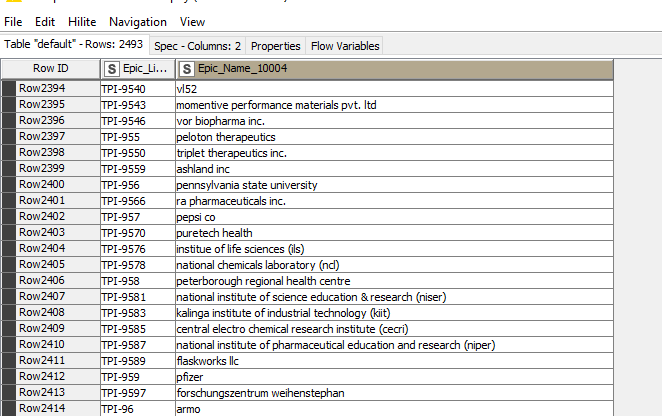
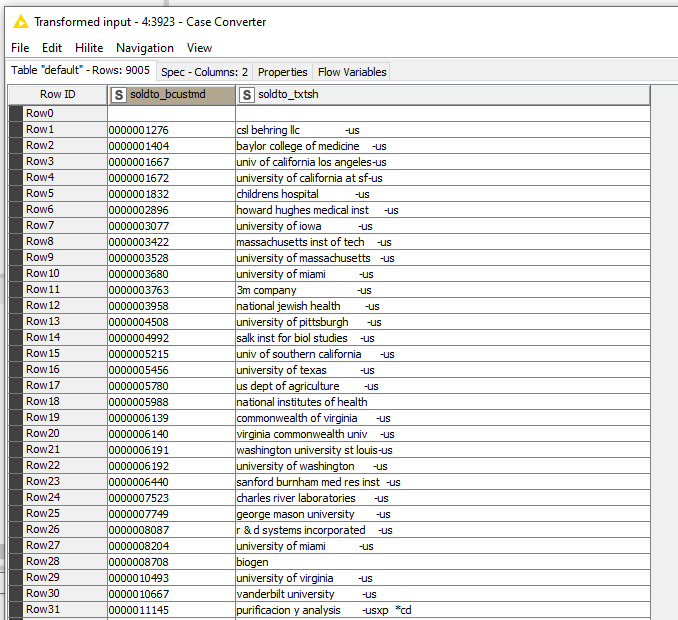
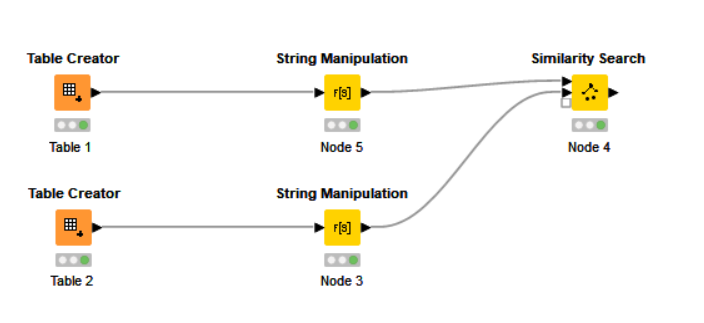
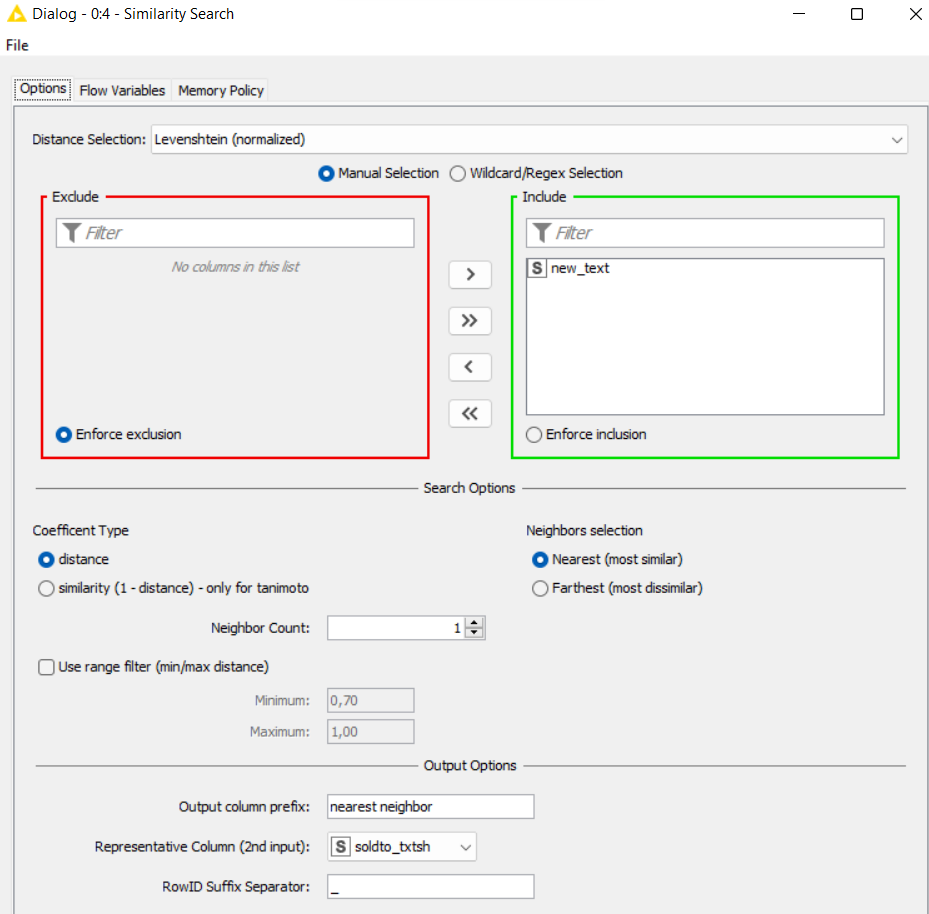
I am wanting to try and pull the closest matches from Table 2 to Table 1. There will likely be multiple for each which is absolutely fine!
I was thinking I need to have each word in the cell enclosed in “” so that I can do string similarity but I am not sure if that is the best route or not either.
A - remove groups of chars from both columns in order to maximize (potential) similarity. Give the resulting columns the same name. For example, in Table 1 you could remove chars between parentheses and “inc.”, “co”, “llc”,… using the String Manipulation node