A “feature” of the String Manipulation (Multi Column) node that makes it a little more awkward to use than it should be is that it doesn’t play well with certain datatypes.
To my knowledge, “certain datatypes” means any datatype other than String, Integer or Double. If you attempt to pass it any other column it “breaks” with the following less-than-desirable and meaningless (to users) message:
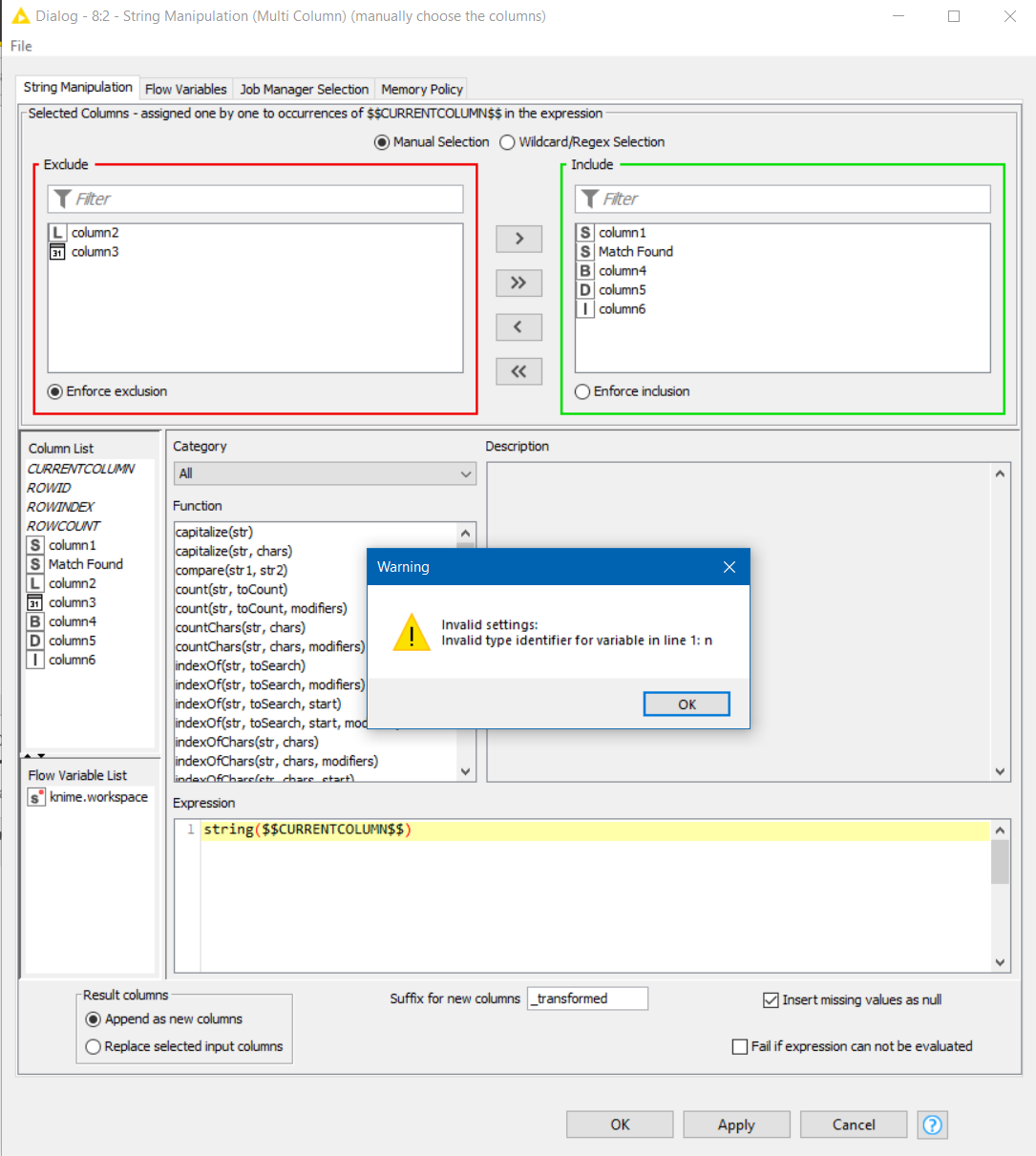
It would be great if String Manipulation (Multi Column) could play nicely with other datatypes in the same way that it’s single-column sister node “String Manipulation” does, but in the absence of this, I believe it should be modified so that it does not even see any other column types than the ones it can handle (just like the way Math Formula behaves).
However, I’m going to go out on a limb and suggest that this is unlikely to happen any time soon, so I thought I’d add a demo workflow on the hub to demonstrate ways that this can be handled…
- There is the “manual” method, which works as a “one-off” but isn’t so great for future-proofed-robustness. Here you simply open the node and ensure that only S, I, D columns are selected:
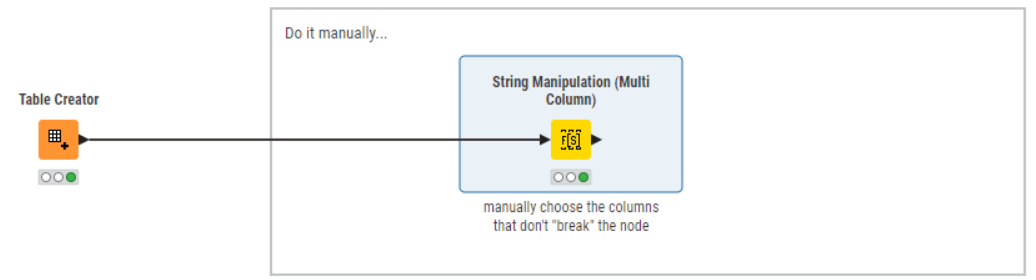
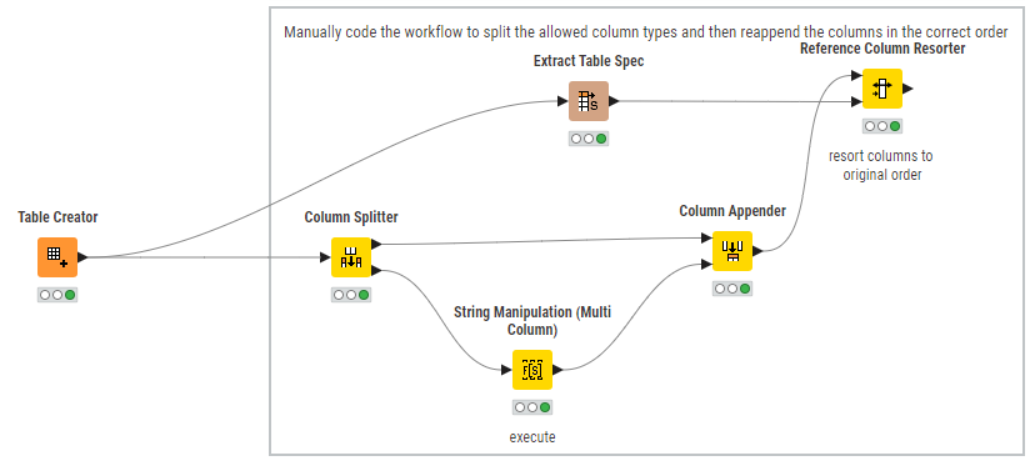
- There is the column splitter method:
This performs a column filter/split based on type which means the only columns that make it to the node are S, I and D, but does mean you need to remember the following “workflow pattern” (or something like it) for splitting and reassembling columns in the original sequence
- There is a “component” method
This does exactly what option 2 does, but using components so you don’t have to remember the above pattern, or one like it.
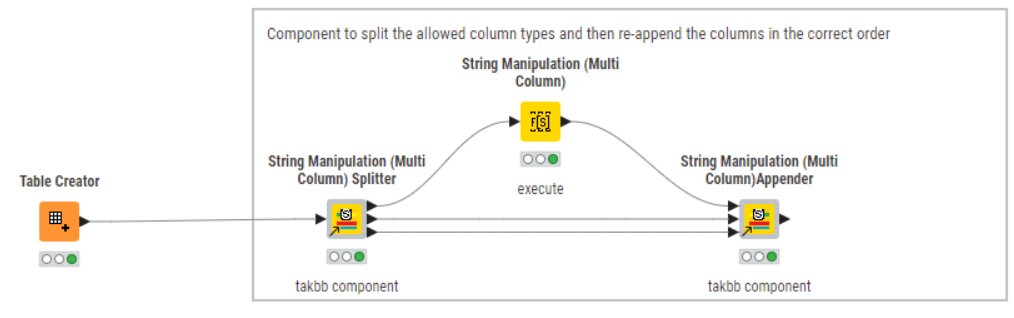
There is no configuration required. Just join them up as per the above screenshot…
I have uploaded an example workflow to the hub.
If you wish to try the components used in option 3, they are available here. I hope you find them useful: