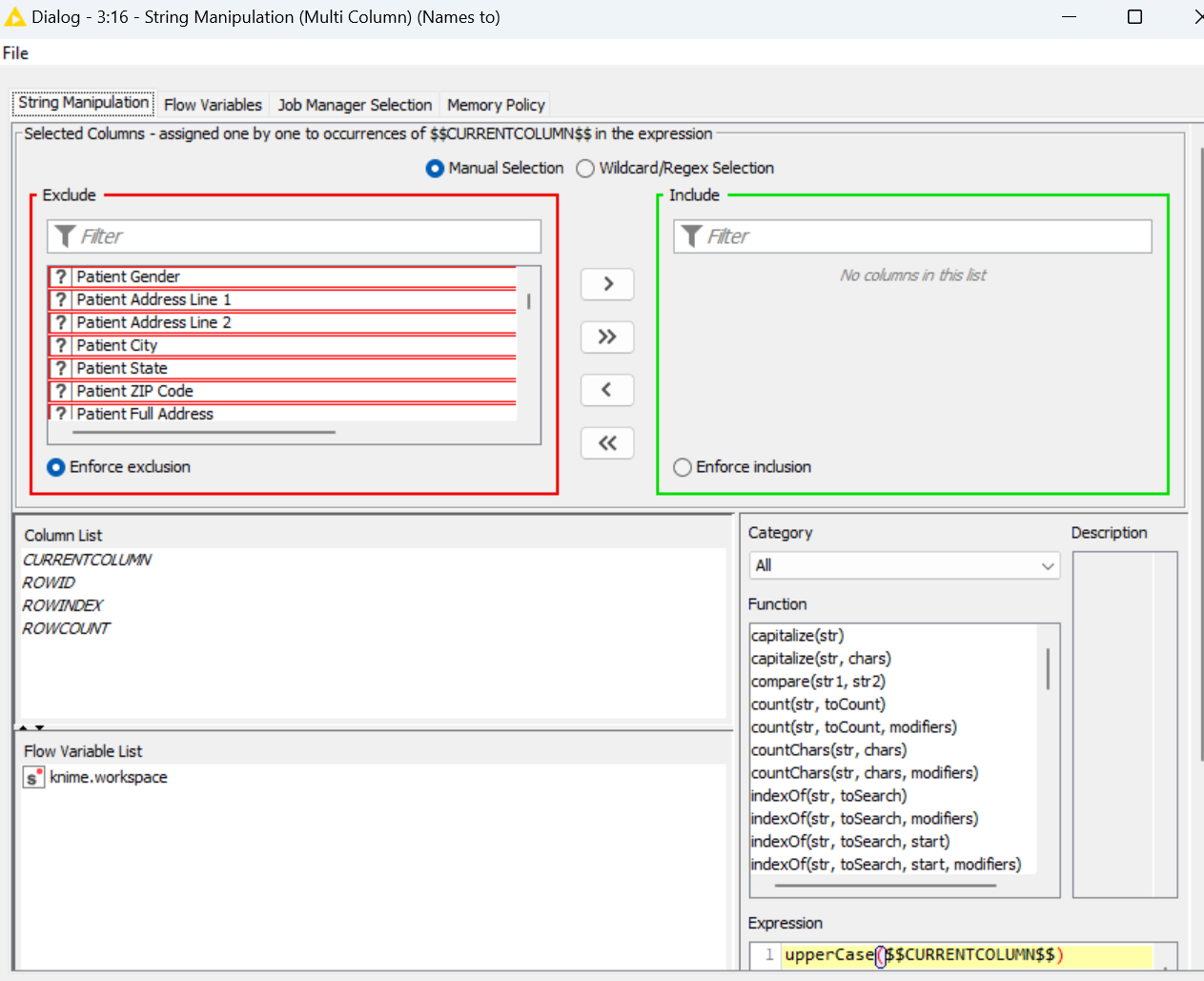
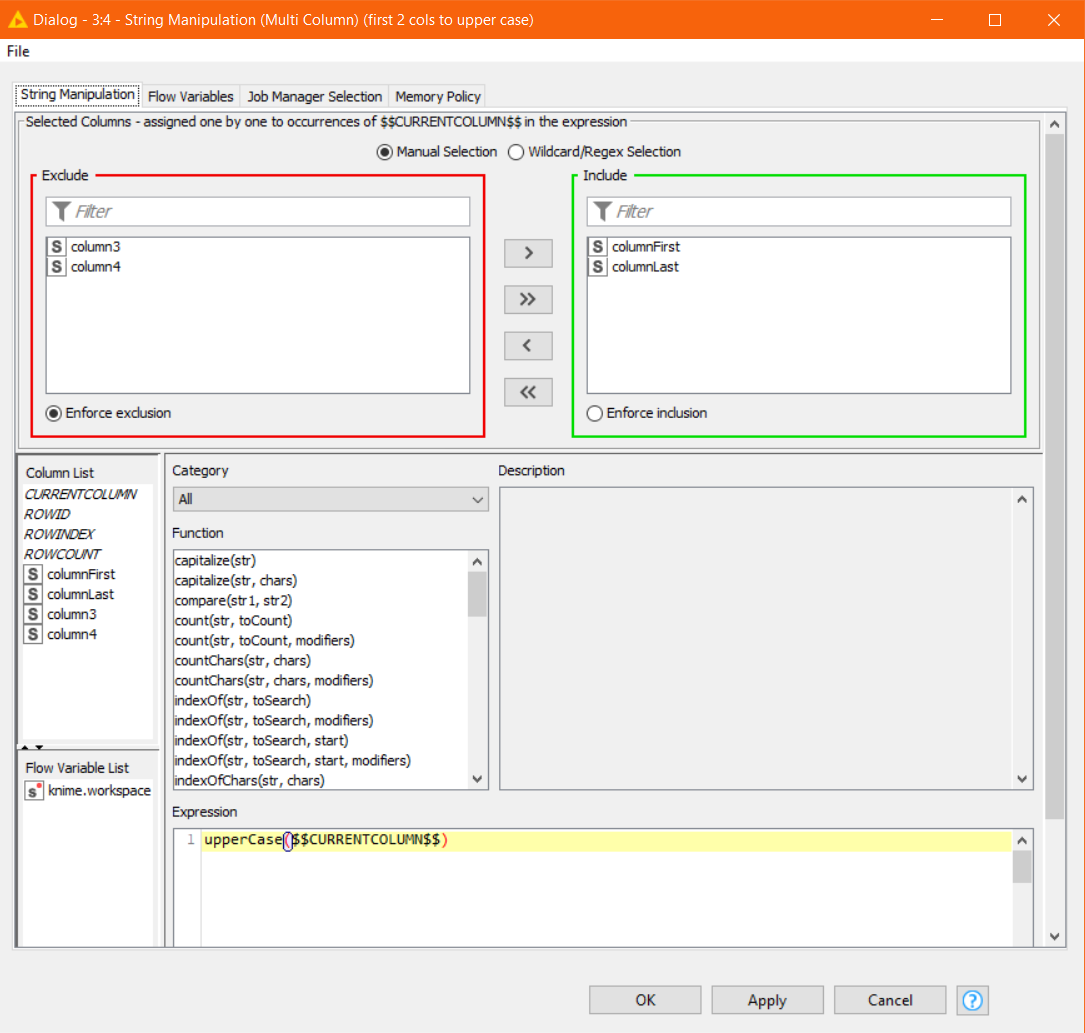
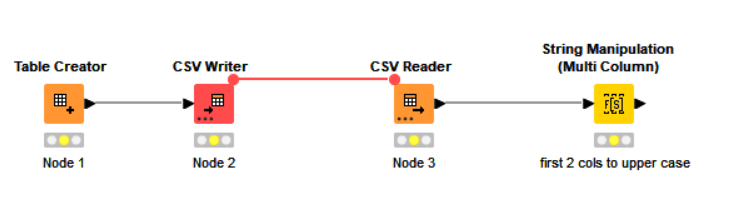
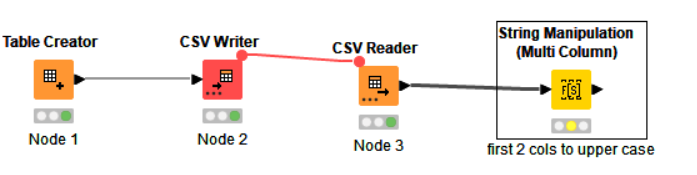
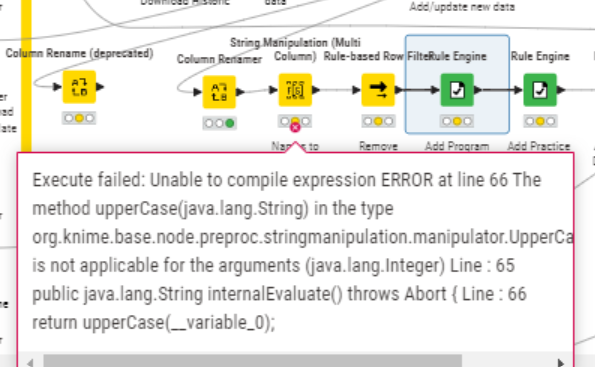
In my workflow, I use String Manipulation (Multi Column) to change two fields to upper case. I am using Knime 5.2.3. Before I upgraded from 4.x, this node worked normally.
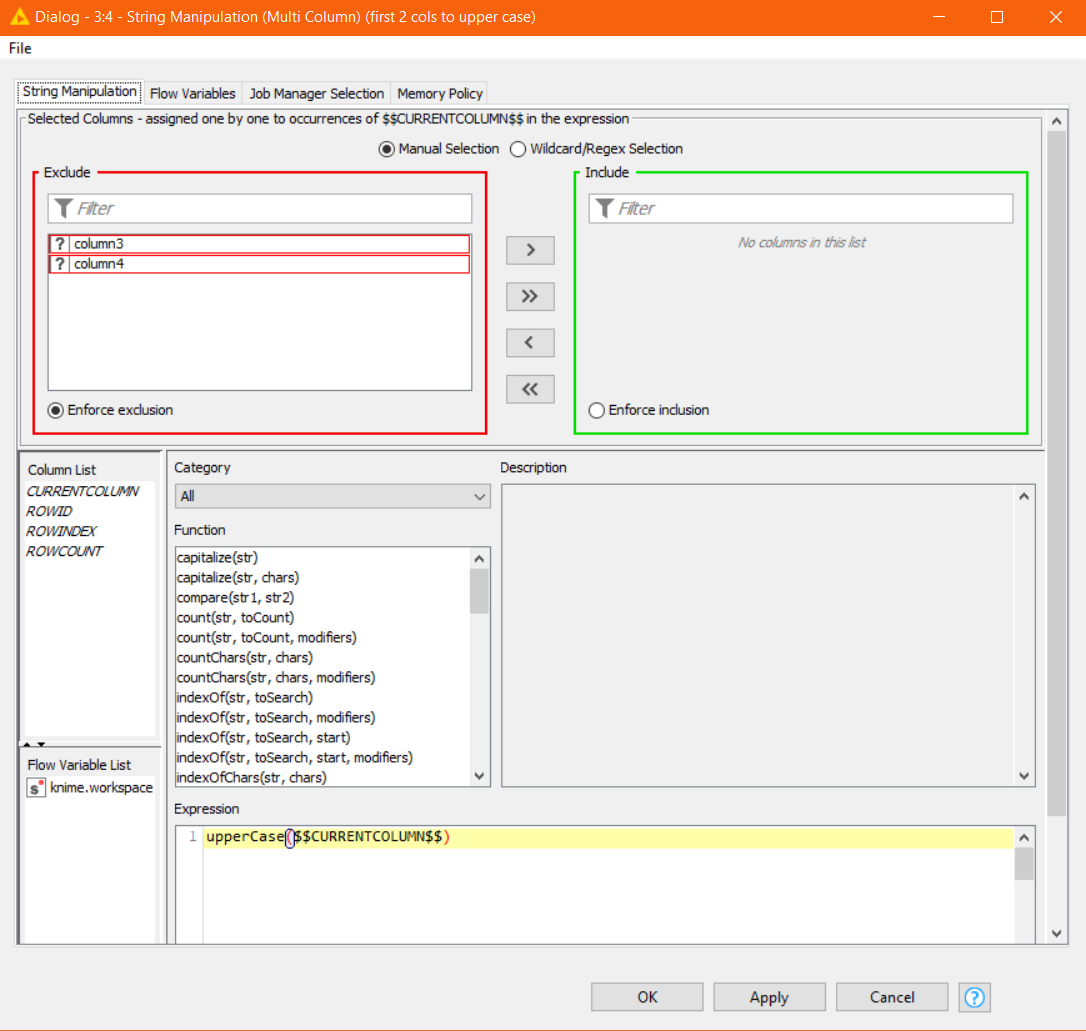
I set it up with two fields ([first name] and [last name]) in the “Include” area and saved the workflow.
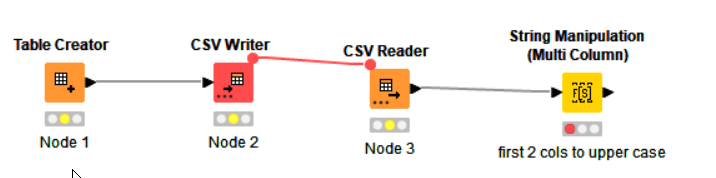
When I open the workflow, I have to reset the initial node that reads in data from my data source. This triggers a reset of all downstream nodes. Then, when I check the config of the String Manipulation, it has every field in the flow selected in the “Include” area. I fix it, save it, and again, when I reopen, I have to edit the node.
Again, this did not happen with the same workflow using Knime 4.x.
It doesn’t seem like correct behavior for a node config to reset like this.
Is this a bug in the node? In version 5.2? Something I’m doing/not doing?
Thanks.