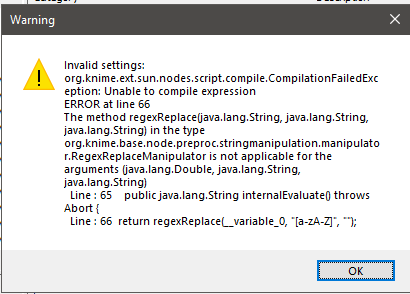
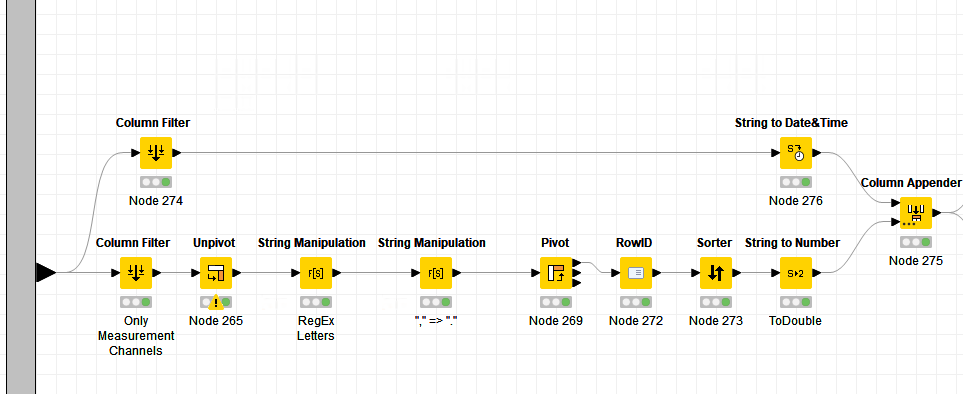
I’m a little bit confused. Is it a bug or a feature?
I have to replace letters in a huge table wit round about 6000+ columns.
I want to use the String Manipulation (Multi Column) Node to do this job with regexReplacer-function
regexReplace($$CURRENTCOLUMN$$, “[a-zA-Z]”, “”)
But this expression throws an error
If I relace $$CURRENTCOLUMN$$ with only one column name it works.
Has anybody an idea what the problem is?
Hi,
as a workaround you could transform this very wide table to a very long table with “unpivot”. Then you can replace all letters with the string manipulation node or string cleaner node.
that’s maybe the problem. I use the CSV Reader Node to import time series data which ar normally double values. I noticed in some channels is text like “nan” so the CSV Reader Node crashed because it requests double values and “nan” is not a double value. So I tried to read all data as string. When I import my data as string KNIME shows me in the table specs that all columns are string values…
The workaround is working, very slow, but it’s working. So my workstation has something to do over the Easter weekend
different solutions are possible which will all have a better performance compared to pivoting:
use a proper file format (e.g. parquet) that carries data type information or a database, instead of text files
read it in as string, run a string Replacer to get rid of “NaN” or the String cleaner and remove everything which isnt a number/dot/comma (assuming you aren’t using scientific notation like 2E10. then just String to Number convert
given 1) is usually not possible, i would recommend to use the String Cleaner Node
Thanks for the String Cleaner Node. I didn’t know it. I will try it because it’s much more faster than my workaround.
To use a proper file format is very difficult. I have to convert MF4-Files. KNIME’s MF4-Reader Node doesn’t work properly so the only way I know ist to convert the MF4 files to CSV