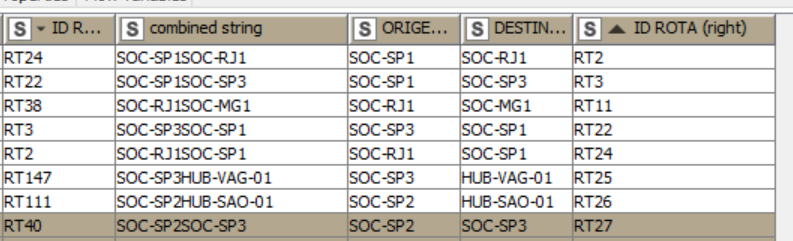
I have this flow, in the example below I have the route ID column (RIGHT) in it I have the RT27 and I have the RT40 in front of it, I need the ORIGIN and DESTINATION written in the RT27 line to be placed in the RT40 line. Very urgently it is a very important job
I was a little confused about the title as this doesn’t look like it is String Manipulation related, and looking at the screenshot the “RT27” and “RT40” line appeared to be the same line, so that confused me too.
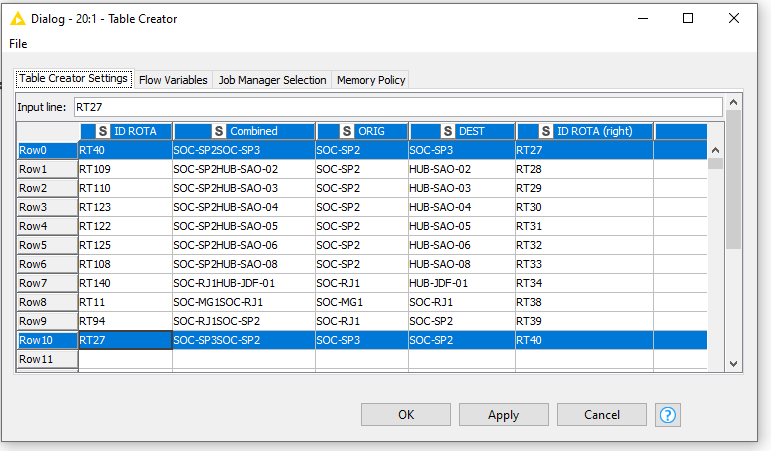
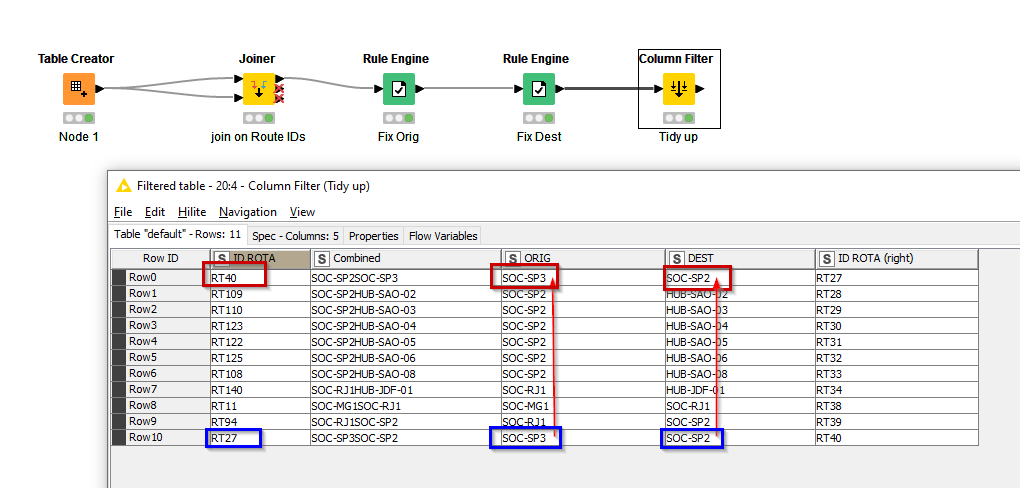
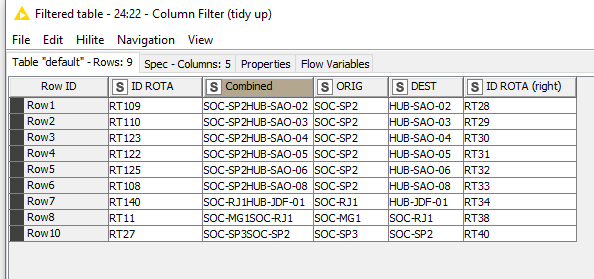
However, thank you for supplying the data in the workflow file, which made it a little clearer that there is other/different data to that shown in the screenshot. For clarity, for others reading, your supplied sample data is as below (I’ve updated your sample table to give it column names that are similar to those in your screenshot)
Row0 and Row10 are line rows you are referring to.
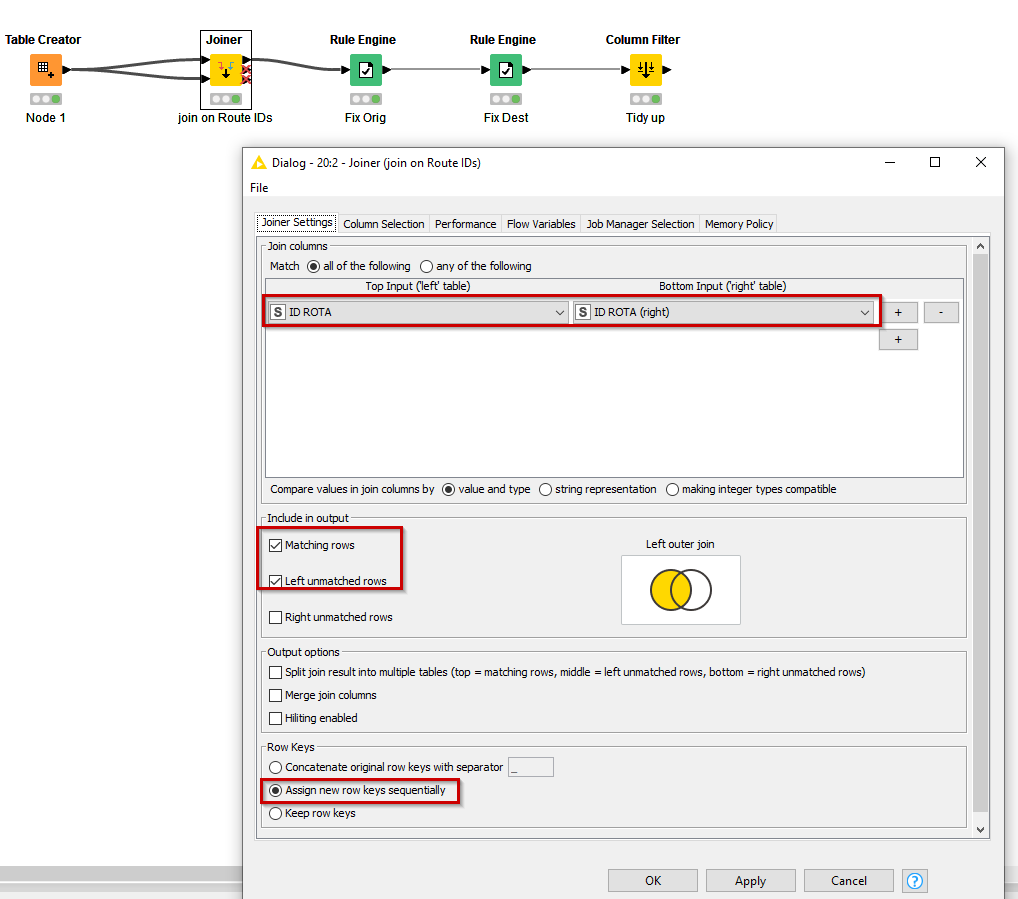
For the stated requirement, you can use a Joiner to join ID ROTA to ID ROTA (right) and also return the Left Outer join so that rows which don’t match are also returned. We only need a single set of “unmatched” rows to get the whole table back so leave the Right Unmatched unticked so that it doesn’t “double up”
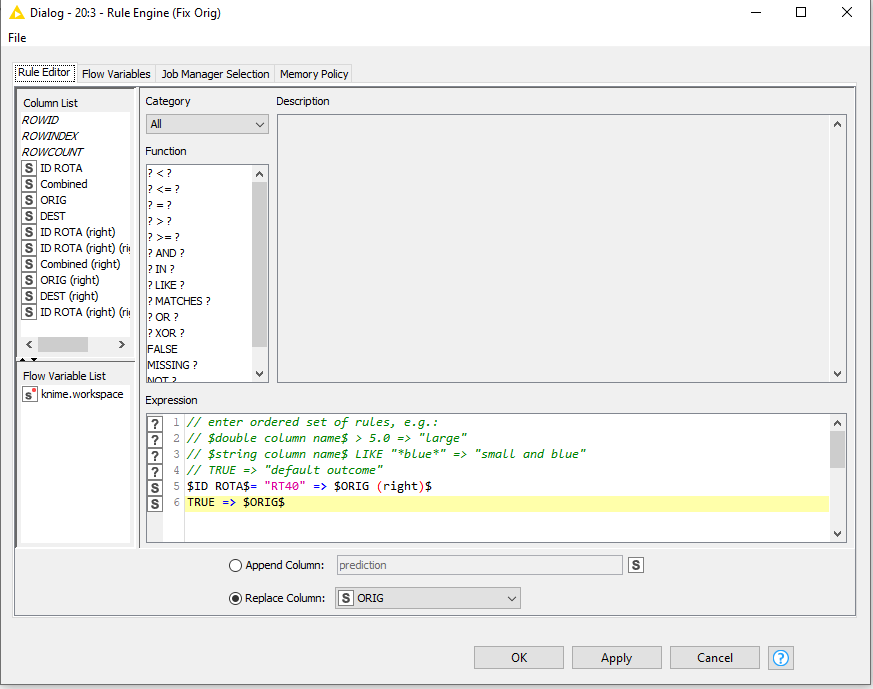
After that you can use Rule Engines to update the Origin and Destination columns for the cases that you require.
If the update is only required for the RT40 line, you could explicitly state this update with a Rule Engine for the Destination and then another for the Origin column
I don’t know if I managed to explain the objective very well, but basically I want to invert the routes that are inverted so that they are in the correct way. Example RT 27 is correct and RT40 is wrong, my goal is to do this for all the other strings I have, I sent only a part
I had guessed that your requirement was going to be more than just updating the row for RT40, but you hadn’t given any other information about what the more general problem is.
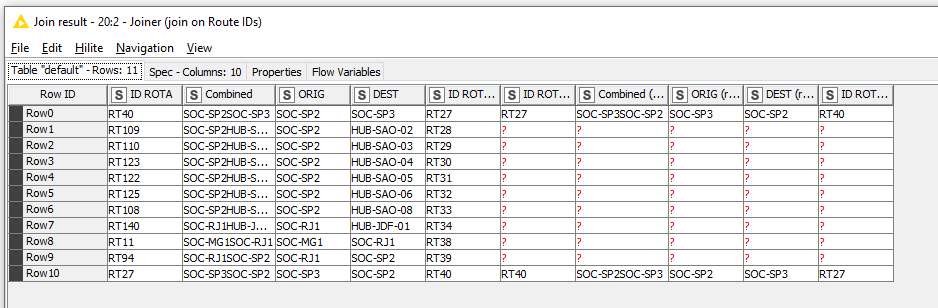
How do we identify that RT40 is “wrong”? If it is simply a case of taking the values from every route identified in ID ROTA (right) and placing Orig and Dest on the route in ID ROTA in all cases, then in this case you are asking to SWAP the Orig and Dest for RT40 and RT27. Is that correct?
If that’s not what you need, then please provide additional sample data, and further description of how to identify the affected rows.
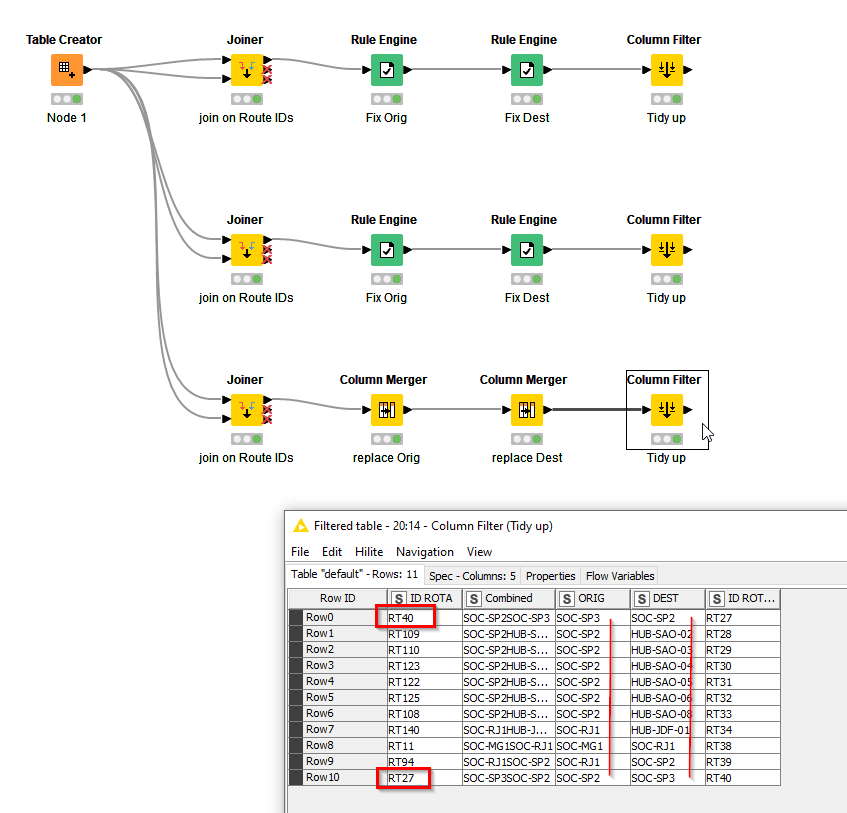
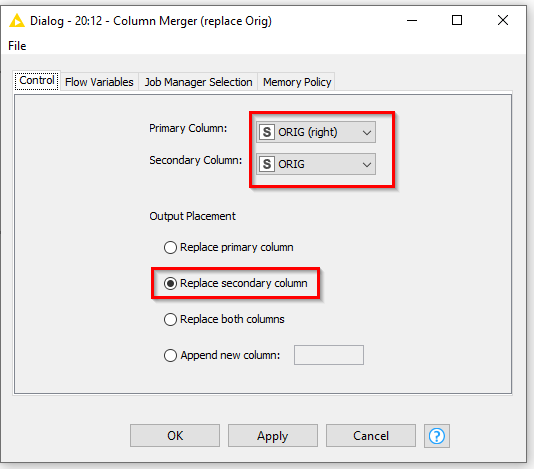
If it is what you want, then this can be achieved either by modifying the Rule Engines to perform the replacement if the row data is not missing, or alternatively you can replace the Rule Engine nodes with Column Merger nodes which will do precisely the same job:
First of all I would like to thank you for all your attention, I hope you can help me.
I need to do a mesh study for my company. I have routes that are dedicated and routes that are reverse, example RT27 (dedicated) RT40 (reverse). In the current model, they are counted as 2 routes, but they are the same origin and destination, only the Route ID and the order of origin and destination change. So I needed to somehow identify that the two are a single route and exclude the repeated one.
I’ve been trying to modify the order so that it’s the same as the first one and so I can use the duplicate row filter.
Below is the foundation I’m using, I really hope you help me
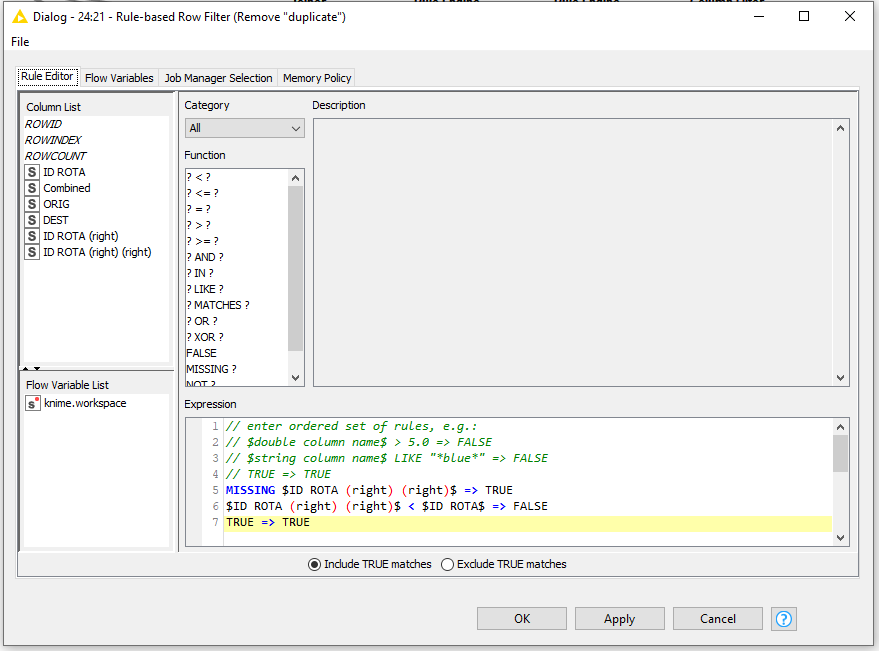
I just took a brief look so I just drop ideas but maybe you could combine the two columns as a sorted list, do some kind of string manipulation (if required) and then split it back and do you duplicate row filter
br
Hi @Gabriel2020
(I’m using the data table I uploaded in previous response as the column names are clearer for the demo)
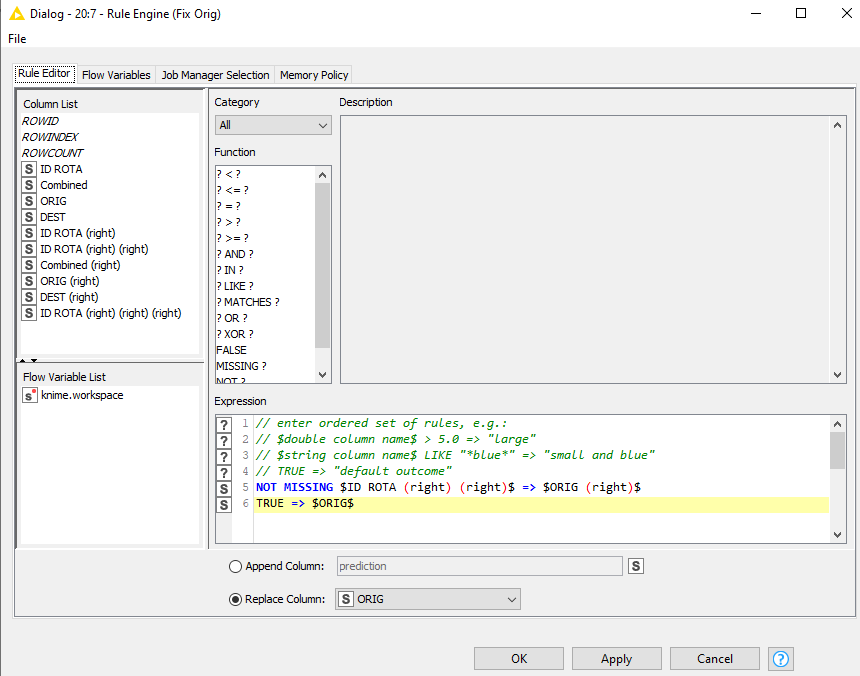
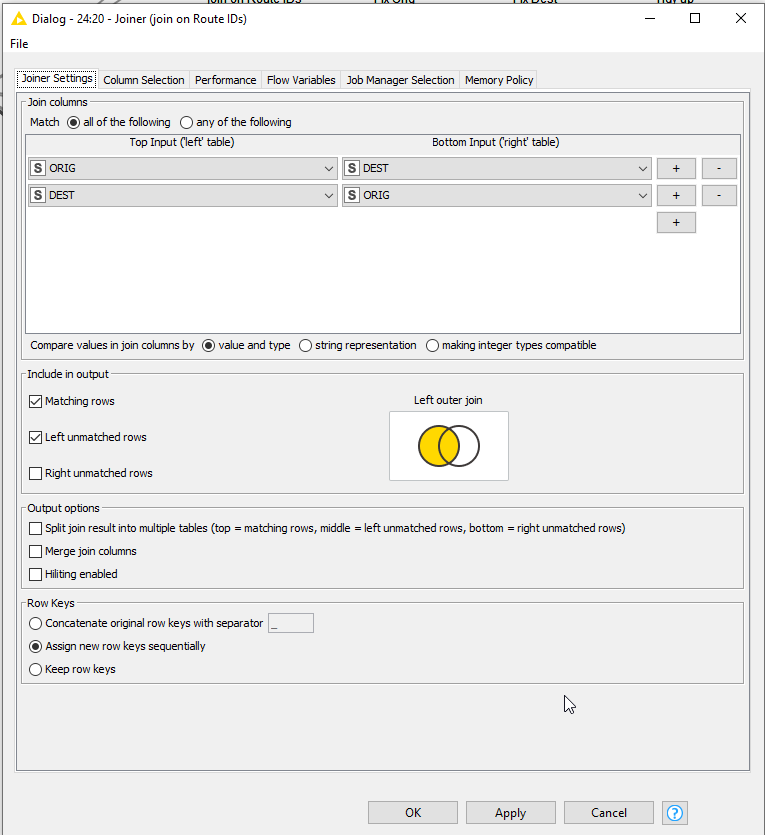
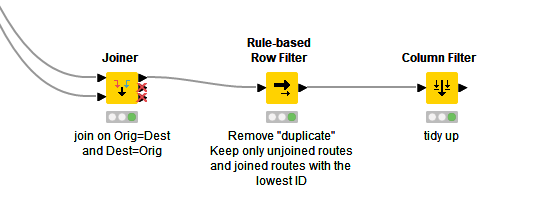
Use a Joiner to join your data table to itself, but this time time on DEST = ORIG and ORIG = DEST.
Return matching an LEFT unmatched, and return just the ID ROTA from the Right table.
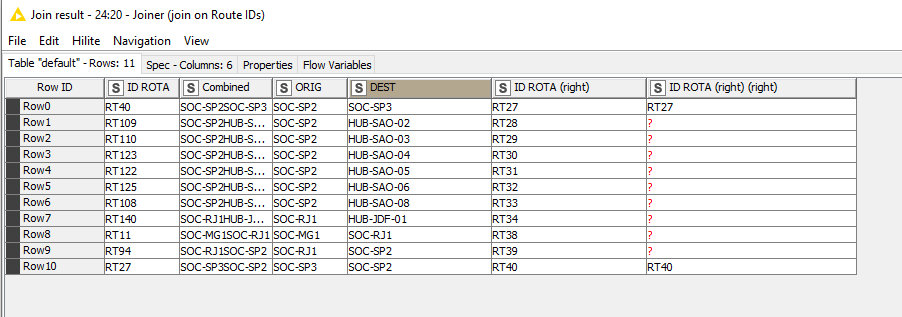
All these "(right)"s are a bit confusing, but unfortunately you already had an ID ROTA (right) in your original sample screenshot which I emulated. I’m not actually quite sure what its purpose is now, as it appears to contain the information you are wanting to find, so I’m pretending it doesn’t exist and am just ignoring it!