Greetings, fellow KNIME-Community!
For severel days now I’ve been trying to solve a certain issue regarding Data Extraction from an existing xlsx-File, but I cannot manage to accomplish any good results.
What I am trying to do:
I downloaded a huge amount of CVs/Resumes as PDF-Files, converted them into TXT-Files and saved the output in an XLSX-File, where the whole Information is stored in one cell of the Excelsheet.
The resumes are either written in German or English language. My goal is to extract certain Information that matter to me from those Cells, e.g. Applicants’ nationality,Universal Degree,Language Skills in German etc. and to put those information into a new column in the respective sheet.
What my problem is:
If I simply filter the data after setting up a Rule Engine via certain keywords like “german, indian, english, etc…” like this:
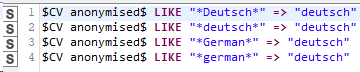
the given rule will also apply to data strings in the respective cell that do not contain any information about the applicants nationality but instead about other things like learning german language or hanging out with german people. The result is obviously, that people might get wrong attributions.
What I tried to solve the problem:
After experimenting a day or two with Rule Engines, I was thinking about using Regular Expressions instead. To do so, I tried to set up a “String Manipulation-Node” that uses a RegEx which searches for two specific terms in a range of 10 or less words to each other. This is the RegEx-Command i found working on regex101.com in terms of the given example in the first image:
indisch\W+(?:\w+\W+){0,10}?Nationalität|Nationalität\W+(?:\w+\W+){0,10}?indisch
it worked flawlessly…
however, if I try to use the same Regular Expression in the String Manipulation Node like this:
regexReplace($CV anonymised$,“indisch\W+(?:\w+\W+){0,10}?Nationalität|Nationalität\W+(?:\w+\W+){0,10}?indisch”,“indisch”)
the output in the newly appended column stays the same.
Does anyone know why? Or can somebody help me out with another way to solve the problem?
I would gladly appreciate your help, and thank you all in advance!
Kind Regards,
Reykas