Hello,
I want to perform string manipulation to transform a single column into 7 columns by separating the text and dates each time.
Original :
The result i would like :
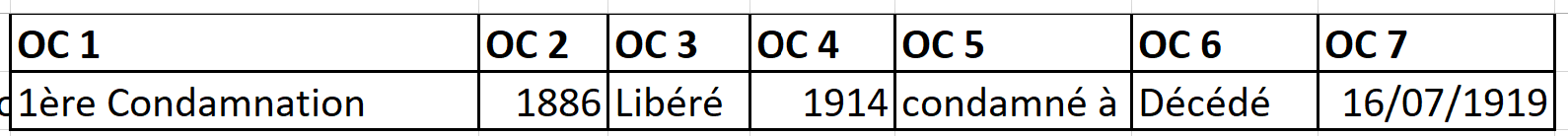
Thanks for your help
Hello,
I want to perform string manipulation to transform a single column into 7 columns by separating the text and dates each time.
Original :
Thanks for your help
Hi,
Depending on what could be in the text it can be rather easy or pretty complicated. For example: your text starts with 1ère, but it can probably also be 2de, 3e, etc, right? Can it also be “Première” instead of 1ère? That makes it again more complicated.
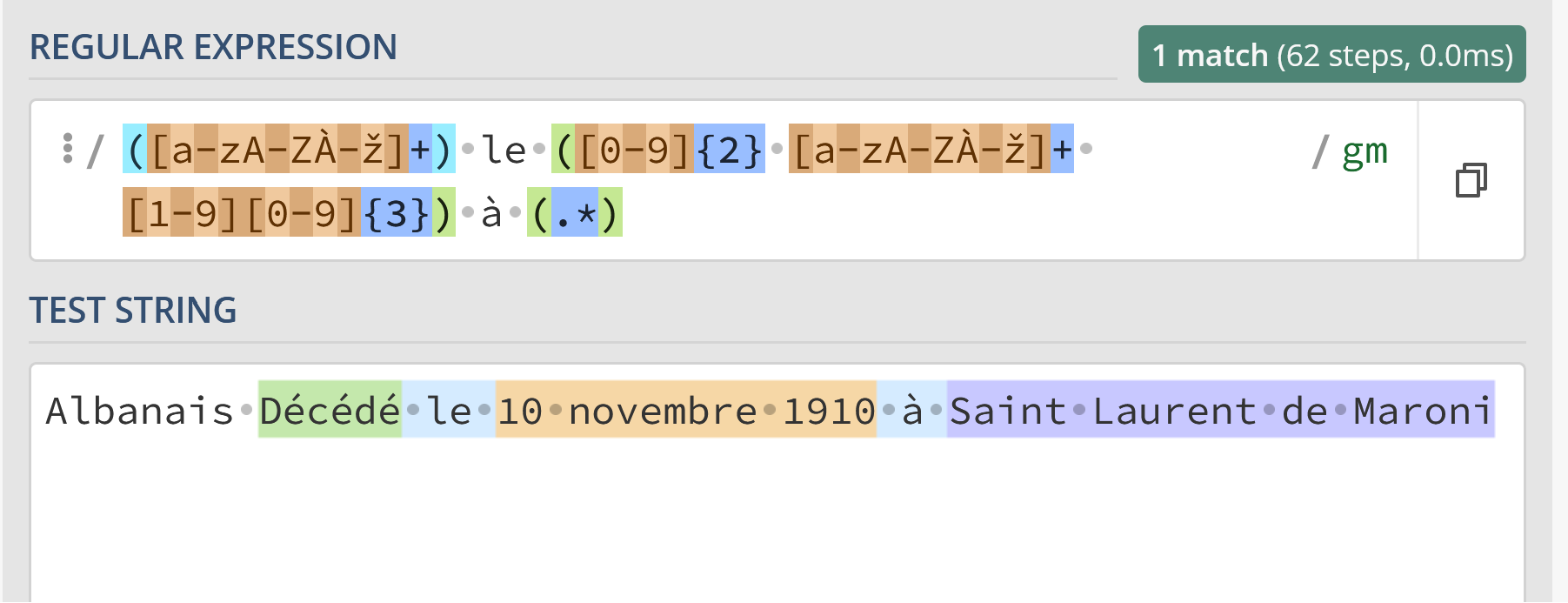
For simpler cases, you can try the Regex Split node with a regular expression that covers all possible cases and captures each section in a group. Example for your text can be separated into the parts you want with this regex:
([1-9][a-zA-ZÀ-ž]+ Condamnation) en ([1-9][0-9]{3}), ([a-zA-ZÀ-ž]+) en ([1-9][0-9]{3}), ([a-zA-ZÀ-ž ]+) nouveau la même année. ([a-zA-ZÀ-ž]+) le ([0-9]{1,2} [a-zA-ZÀ-ž]+ [1-9][0-9]{3})
You can try it out on regex101.com. Paste the regex above into the Regular Expression box and your text into the textbox below it (Test String). You will see that each section that you want to extract is colored and you find the groups on the right side under “Match Information”. However, when you add more texts, you will probably find that it is not matched correctly, as the regex is not generic enough for it. You will need to adapt it so it matches other possibilities.
Alternatively, you can do more complex text processing using the Redfield Spacy nodes. Have a look at this example workflow for portuguese texts: Redfield NLP Nodes: Spacy example – KNIME Community Hub. Here the interesting node for you is the Spacy POS Tagger. It tags parts of speech based on their type, e.g noun, verb, etc. You could use this information to separate parts of your text as well, and maybe more generic than it is possible with regular expressions.
Kind regards,
Alexander
Thanks for your answer.
I try to use REGEX Split but i get no result.
KNIME_project.knwf (8.2 KB)
TRANSF - Copie.xlsx (9.1 KB)
If you can check …
Thanks
Hi,
It is because in my regex I accidentally had Condamnation with a capital C. You can either change it, or you set the “case insensitive” option of the Regex Splitter. That is probably the better option, as it makes the whole thing more robust.
Kind regards,
Alexander
Hello,
In the Regex Split family :
I’m sorry to call on you again but this is important work on big data (135 000 rows) concerning the french penal colony … May be a ML project that will finish in Just Knime It
Décédé le 10 novembre 1910 à Saint Laurent de Maroni =
Split 1 > Décédé
Split 2 > 10 novembre 1910
Split 3 > Saint Laurent de Maroni
Hi,
You can use ([a-zA-ZÀ-ž]+) le ([0-9]{2} [a-zA-ZÀ-ž]+ [1-9][0-9]{3}) à (.*), but I am not sure if you are on the right track here. Do you need this for every specific way something can be written? Is the first word always Décédé, or is it sometimes even 2 words in that place that you need to extract? Because then the regex split will fail, as the rule says any character 1 or more times, terminated by a space.
I tried to make the rule a bit generic, but a rule like this would also work for your example input:
(Décédé) le (10 novembre 1910) à (Saint Laurent de Maroni)
I just don’t think it is what you want, because the input may be slightly different, right?
Kind regards,
Alexander
Thanks Alexander,
One last question, i try to understand how to use the pattern in Regex Split. My data is full of differents cases. I try to make a “generic” as you said.
This is an example.
Albanais. Décédé le 10 novembre 1889 à Saint Laurent de Maroni
I want :
Split0 Décédé
Split1 10 novembre 1889
Split2 Saint Laurent de Maroni
I don’t want to conserve : “Albanais”. Sometimes that will be Chinois or Allemand ect …
Thanks for your help
Hi,
For this to work, you need to be able to formulate your data extraction rules in plain language first. For example:
Ignore the first word, then comes always “Décédé”, then a “le”, then a date in the format , then “à”, and the rest is a location.
If you formulate this precisely, a regex can be built to accommodate all your cases. If you have trouble with the formulation of the rules in plain language, then there also cannot be a regex that works.
Kind regards,
Alexander
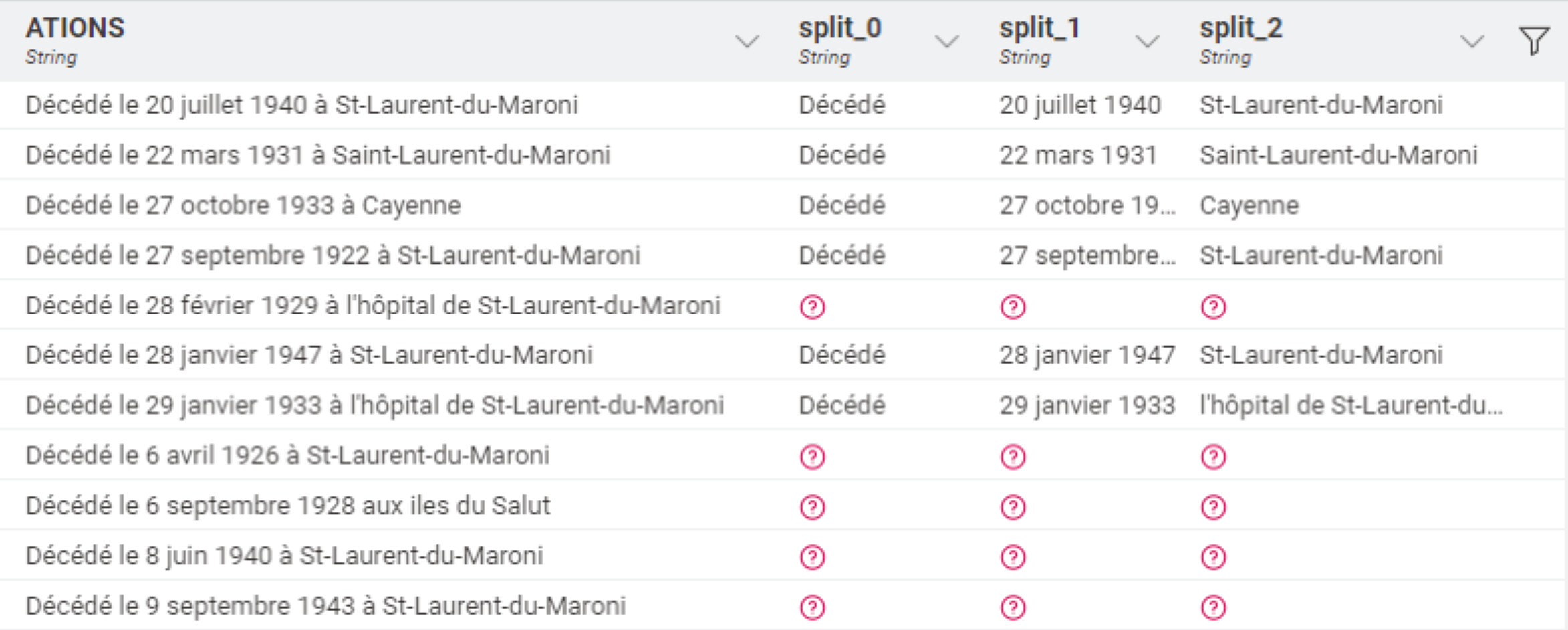
Very strange …
Why some rows are split as expect and the same Regex doesnt work for the others that are the same
Hi,
Sometimes it is as simple as a superfluous space. If you can paste the ATIONS from your table here as text, I can have a look.
Kind regards,
Alexander
Finaly i think Regex is to complicate.
I do not understand why it s not possible with AI today to have a Regex generator.
…
You might have opened up another avenue with your comment. You could use our OpenAI nodes to let it parse the text. You just have to engineer the right prompt to make it do it. Example:
“the following are sentences in French, with a date and a location. Please give me a JSON where all the sentences are parsed and date and location extracted. The format should be {“date”: , “location”: }. The response should only be the JSON and nothing else.”
Then you can use the String to JSON node and JsonPath to extract the data into a table. This might be the most robust way you can do it today.
Kind regards
Alexander
Hi @Brain, I couldn’t help but notice some parallels with what you are trying to achieve and @FrankColumbo 's recent post, which also resulted in using regex for extracting text, but involved discussions of using AI too.
Although regex was provided as a solution in that thread, I agree that for this type of work AI is undoubtedly set to become the primary way to achieve it, as sometimes it is simply not practical to write a prescriptive set of rules for all possibilities.
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.