Have you tried the Cell Splitter node? Split at comma; output as list and then ungroup the list. Or simply save as “new columns” and remove the one you don’t need.
I think you can solve with a single ‘String Manipulation’ node using regexReplace(). There are two different approaches for your convenience (relying in your real data); depending about your capturing group:
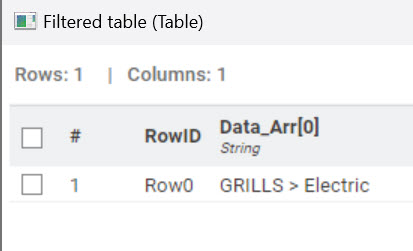
Removing trailing text after the comma, similar to cell splitter by @rfeigel; and keeping the comma’s leading text: [GRILLS > Electric], Gourmet Sale > GRILLS > Electric
regexReplace($text$, "(.*),.*", "$1")
Keeping the latest two items in the hierarchy: GRILLS > Electric, Gourmet Sale > [GRILLS > Electric]