I have a question regarding the matching of strings in one column.
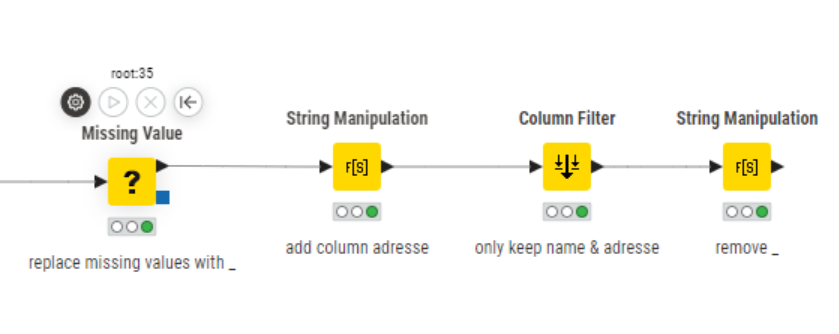
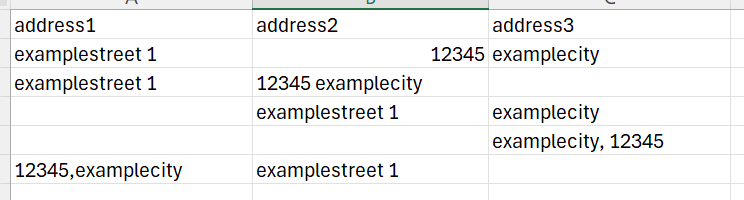
There are three adress columns, which are partially filled but also contain empty entries. Initially, I replaced all empty entries with _ and combined the three address columns into a single one. To simplify, I only kept this adress column and the corresponding name column in the table. Then I removed all _.
My problem is that I don’t have two columns but one to compare. When testing with string similarity node every entry in the similarity column has the value 1 because I could only compare one address with itself.
How can I check if these addresses match or show similarities?
Now I need to check how similar entries of this column are. The main cause is to get rid of duplicates, so duplicates musst be identified, even if they differ in order or if there are parts missing. This should work for bigger tables with about 100k rows and multiple addresses.
I always recommend to provide an example WF that holds the example data - then people like me can quickly try out some things and get to a potential solution…
In the absence of that: Now that you have your list, one option is to first group by your new column and get the count of those entries, that appear multiple times.
Where the count is >1 you have your first duplicate flag.
Then you can filter the group by table for anything bigger than 1 and remove those entries from your main table via reference row filter.
The remaining ones you can then send into a chunk loop of size 1 and inside this loop you run each row and the remaining main table into string similarity - you’ll also need to build additional logic to flag your duplicates somehow - but that’s impossible to describe w/o data.
Hi,
I would try following. Remove all non-alphanumeric signs in the strings and then sort each string.
After that you can apply the “remove duplicates” node.
So I’m not aware if sorting of strings can be done with a KNIME node but it is possible in python:
import knime.scripting.io as knio
import pandas as pd
# This example script simply outputs the node's input table.
df = knio.input_tables[0].to_pandas()
# Function to sort letters in a string
def sort_letters(s):
return ''.join(sorted(s))
# Apply the function to the column
df['sorted_strings'] = df['adress'].apply(lambda x: sort_letters(x))
# Output
knio.output_tables[0] = knio.Table.from_pandas(df)
thanks very much for your suggestion. The algorithm would work if the entries are correctly filled. The problem I have relates to inconsistently entered entries. I made up an example-table for better understanding. stringmatchingtest.knwf (70.7 KB)
Maybe this helps to clarify or to test.
I tried implementing a workflow like you suggested but after joining the table (which I thought was necessary to compare every row with each other) and checking with string similarity node in a chunk loop, the rows where squared and due to the large number of rows it would not terminate. Probably I chose the wrong path of solving the problem so I made up an example-workflow for you to test. stringmatchingtest.knwf (70.7 KB)
Keep in mind that data sets I need to work with are bigger in size, so the solution should work for those also.
This may help you. Initially there were three address columns (e.g. for street, postal code, city). But due to inconsistent entries there are missing values, wrong orders or wrong spellings. Thats why I merged those columns into one for a better comparison.