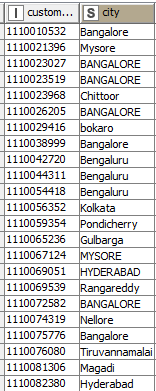
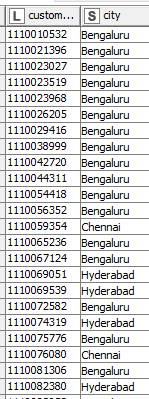
Hi, I have to compare the addresses of customers from two different tables. Each customer has a unique ID assigned to them and is the primary key for both the tables.I tried using the similarity search but it would search for the similar string in the entire second table and return closest match, while i need to check the strings against specific customer ids
Can you explain how can I use similarity score to return score against each customer id
I have come along some questions of address deduplication and string similarity. I created a collection of maybe useful links and KNIME discussions along with some sample workflows. Maybe they can serve as an inspiration.
Also you could upload sample data (if they are not confidential) that represent you challenge - and the desired outcome. It might then be easier to get an idea how this could work.
My challenge is with understanding how does the string distance and string similarity nodes work ?
How does it know which two columns should be compared
How can I specify that the address1 of a customer should be matched with address2 of the customer? currently the similarity looks up the address in the entire table (all the customers) and returns the nearest match irrespective of customer_id.