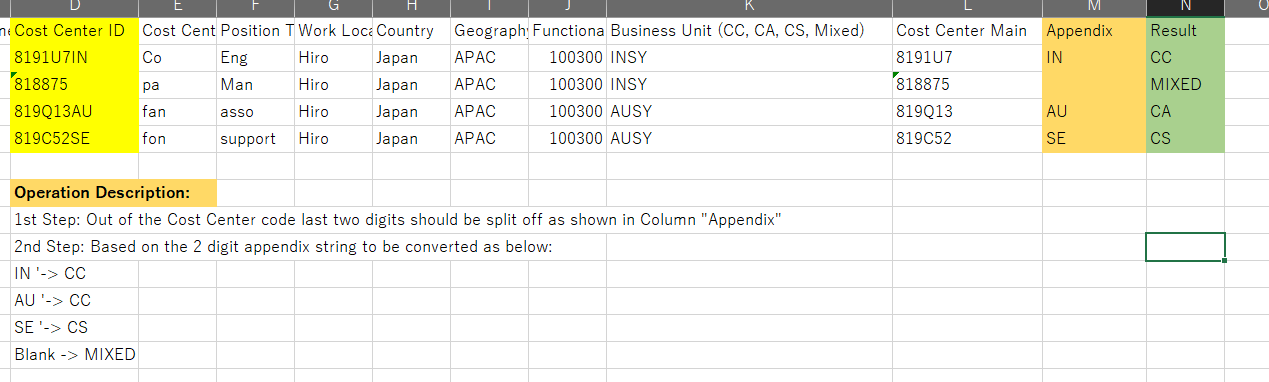
Ok, no problem. My padding to 8 characters will satisfy that requirement then.
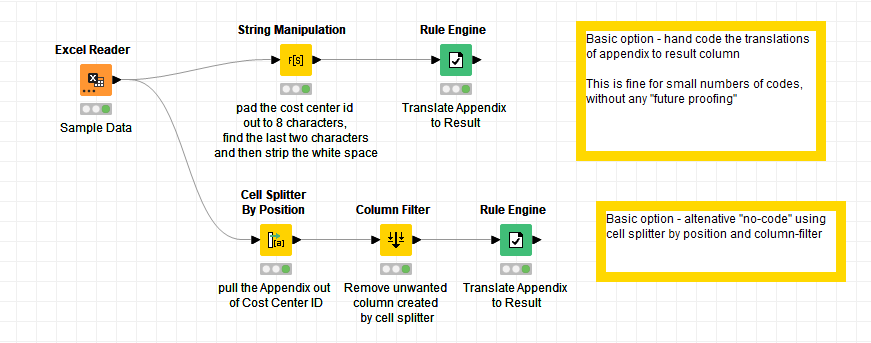
Here is a workflow containing a couple of ways of achieving this.
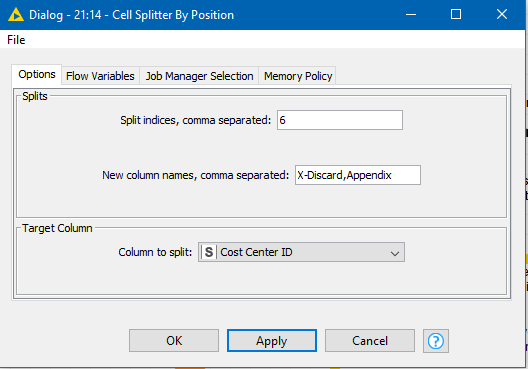
In both cases a String Manipulation node is used to handle your first Step. It right-pads to 8 characters and then takes the final 2 characters from the cost center id. So it will contain the two characters, or in the case of cost centre id being only 6 characters long, it will contain an empty string, as it then strips any white space.
strip(substr(padRight($Cost Center ID$,8),6,2))
This piece of code says pad the cost center id with spaces on the right to ensure it is 8 characters in length, then take the substring of that starting at position 6 with length 2 characters, and from the result strip any whitespace.
After that, in the first flow (the basic option) step 2 is handled by a hand-coded set of rules in a rule engine. I’ve included a catch all at the end as I don’t know your data, and it is possible that your rules won’t cover all eventualities, in which case it writes “unknown” to the Result column
$Appendix$="IN" =>"CC"
$Appendix$="AU" => "CA"
$Appendix$="SE" =>"CS"
MISSING $Appendix$ OR $Appendix$="" =>"MIXED"
TRUE => "unknown"
You would need to adapt this to your data as required.
The second suggestion is a little more advanced, but provides a lookup table to satisfy your second step. This translates the two character codes, but doesn’t match the empty string, so that is handled by a subsequent rule engine. There are a couple of extra nodes to ensure your rows are put back in the correct order as the Join can affect the ordering.
It’s not bullet-proof and there are other ways of achieving this too, but hopefully gives you something to work with
KNIME_StringSplitReplace.knwf (38.7 KB)