I was looking for geo data (longitude & latitude) for Chinese cities to create a map in PowerBI. I found a dataset on Geonames: GeoNames
I’m interested in the field “alternatenames” which contains the city names in Chinese. The data there looks like this:
Kanbaduo,Oiser,Oisêr,Wosai,Wosai Xiang,kan ba duo,wo sai,wo sai xiang,坎巴多,窝塞乡,窝赛
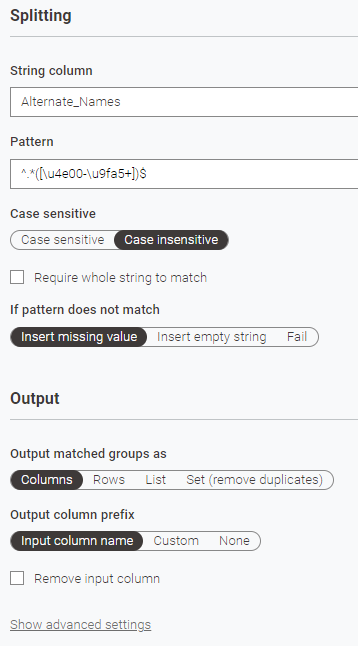
I’ve been trying to utilize the node String Splitter (Regex) to separate the Chinese names from the rest, but no Regex code I tried worked so far. The desired output would be 2 columns, one for the Chinese names and one of the remaining alternate names:
Rest
Chinese
Kanbaduo,Oiser,Oisêr,Wosai,Wosai Xiang,kan ba duo,wo sai,wo sai xiang
Hi @Er3n , you are close with the regex but you have two potential problems:
The initial .* (to match any characters) will be “greedy” which means it will try to consume as many characters as possible whilst still allowing the whole expression to succeed.
You have commas within the set of chinese characters
Let’s simplify things (you may already know much of what I write below, but a simple example may be of use to others)
If you had the string AAABB,BB,BBB and you wanted to collect the part containing the Bs, an equivalent to your current regex would be
^.*([B]+)
But if you used this it would collect only the final B because everything up to the final B is consumed by the “.*”
You can stop the .* from being “greedy” by following it with a question mark “?”
You now have ^.*?([B]+)
and this would collect the final three Bs (but not the others) because the expression can only match a continuous sequence of Bs, but the data contains commas.
So we can tell it to also match commas which are within the Bs
^.*?([,B]+)
and now it will collect: BB,BB,BBB
So, replacing the B in my regex expression with your Unicode range, the equivalent for your regex would be: