I think i might have encountered a bug in KNIME analytics platform 3.6.2.
When I have a string containing a datetime value in the format “YYYY-MM-DD hh:mm:ss”,
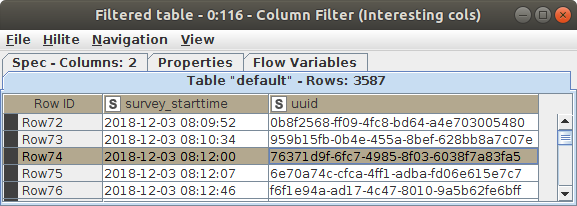
and the seconds are zero (2018-12-03 08:12:00), the resulting datetime value is “2018-12-03T08:12”, instead of “2018-12-03T08:12:00” like I would have expected. Screenshots are attached.
Am I doing something wrong or is this really a problem?
What you can see in in the KNIME table is just a representation/rendering of the actual date&time value. In this representation zero seconds are truncated. For further processing of that column, this does not have any impact as @mlauber71 already said. The zero seconds are still stored within the value of that cell.
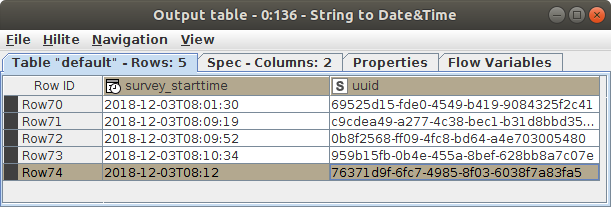
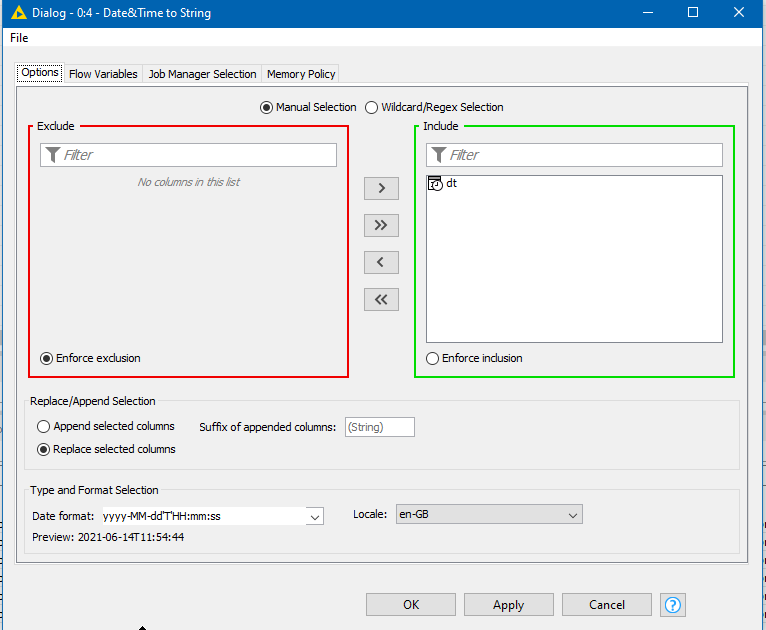
If you want to have a nice representation of theses values for visualization or a report, you can convert the column back to a String using the Date&Time to String node and specify to use the “yyyy-MM-dd HH:mm:ss" format.
In String to DateTime node seconds and milliseconds by default are in square brackets. That means they are optional and format cuts what is optional. At the same time if brackets are not specified it could be possible to keep zeros.
The square brackets mean that seconds and milliseconds are optional in the String value that should be converted to Date&Time. What you can see in the posted screenshot is just a way to represent the date&time value. The only way to see zero seconds in the representation of the Date&Time column would be to use a different renderer, but currently KNIME supports only the default Java renderer which is truncating the zeros.
However, it is just representation, the value is still correctly stored and using a Date&Time to String node allows you to convert it back to any String representation you want to after you have processed the column.
@SimonS@tmeschke I agree that this is only a formatting thingy and the underlying timestamp is still the right one.
The annoying issue – I wouldn’t call it a problem – is, a succeeding node (e.g. Table Row to Variable) transforms this timestamp to a string representation and uses this weird date format. So we end up with timestamps with and without seconds depending on the input. I am aware, we can easily work around this by first formatting the date to a string and then feeding it into the variable transformer, but this means one additional node in the workflow
The issue with date&time formats is that there are so many out there and everyone prefers a different one. It is hard to choose which to set as default. For your use case it would definitely be desired to have the zeros not truncated, others might like to have it truncated for some reason or want to have a totally different format.
However, using just one additional node (Date&Time to String) allows to resolve this issue, as you said, and there will always be someone who has to use the node because the default format does not fit his needs. It’s a really hard discussion which format to use as default, we chose to use the Java default.
Hi @SimonS , I have an issue with this format. When I try to upload to BigQuery using this format (to datetime datatype in BigQuery) it gives error because the csv file do not provide second when uploading. Is there any solution now to work with this format?
You can specify optional pieces of a format with brackets, so yyyy-MM-dd HH:mm[:ss] should be able to parse times with and without seconds. If you never have seconds, you can also just remove the last part of the format.
Sorry, I mean in knime datetime data type. I’m using this type to directly upload to bigquery using db loader node. But I think this node change it to csv first before uploading. The csv file don’t have the seconds it needed to upload to bigquery
If I understand correctly, I think that what @AlfonLinata is saying is that whilst internally in KNIME and Java, it is only a representational thing with the “missing” seconds, when KNIME writes it out to a CSV file for use with third party software or other processes, the missing seconds cause problems as they aren’t written to CSV either if it is fed directly from a datetime column.
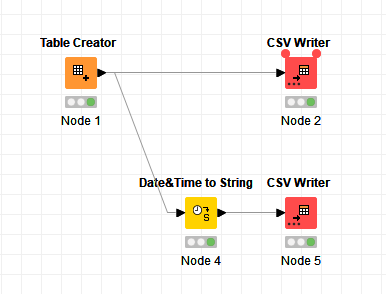
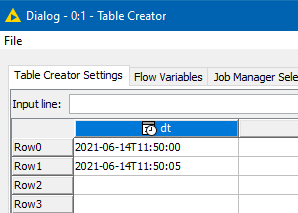
The attached workflow demonstrates:
Table Creator contains two datetimes…
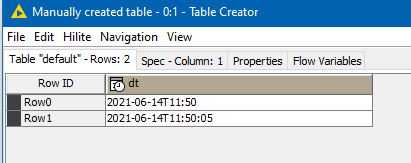
These are rendered as:
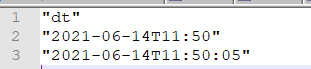
On writing directly to CSV via Node2, the CSV appears as this:
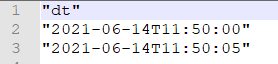
The required CSV, (for further processing) - produced by Node5 - is this:
so an intermediate conversion to String is required to ensure the correct output format to the CSV file (which hopefully is the answer to the question!)
[edit - I should add that in any case, generally when writing to CSV, dates should be converted to String to ensure that they are being output in the required format for the CSV, rather than the arbitrary “internal” format for a date/time]
Hi @AlfonLinata , when you say you “can’t use string type”, in a CSV file everything is either a string or a number. There are no other datatypes, so surely you just need to make it a string in the expected format, unless I’m misunderstanding?
Hi @takbb thankyou for reply.
The problem is I’m not using csv writer node, I’m using DB Loader Node, that I believe automatically detect datatype in knime and bigquery. If it doesn’t match, it won’t let me execute it. This node works by converting to the csv first, that I don’t have (little) control over it.
Hi @AlfonLinata , my apologies… I misunderstood earlier when you mentioned CSV files but I now understand what you mean… hoping this gives somebody else some ideas while I sit and ponder…
This is the point where if I hit an apparent wall like this and I’m running short of time, I would end up using the Loader to upload data in varchar/string format (where you do have control over the format) to an intermediate table and then doing a final conversion on the database from that column into the datetime field.
Frustrating if it has to come to that over something so trivial as this but is that option available to you?