I am getting a (for me) very strange error while parsing string to datetime.
Setup
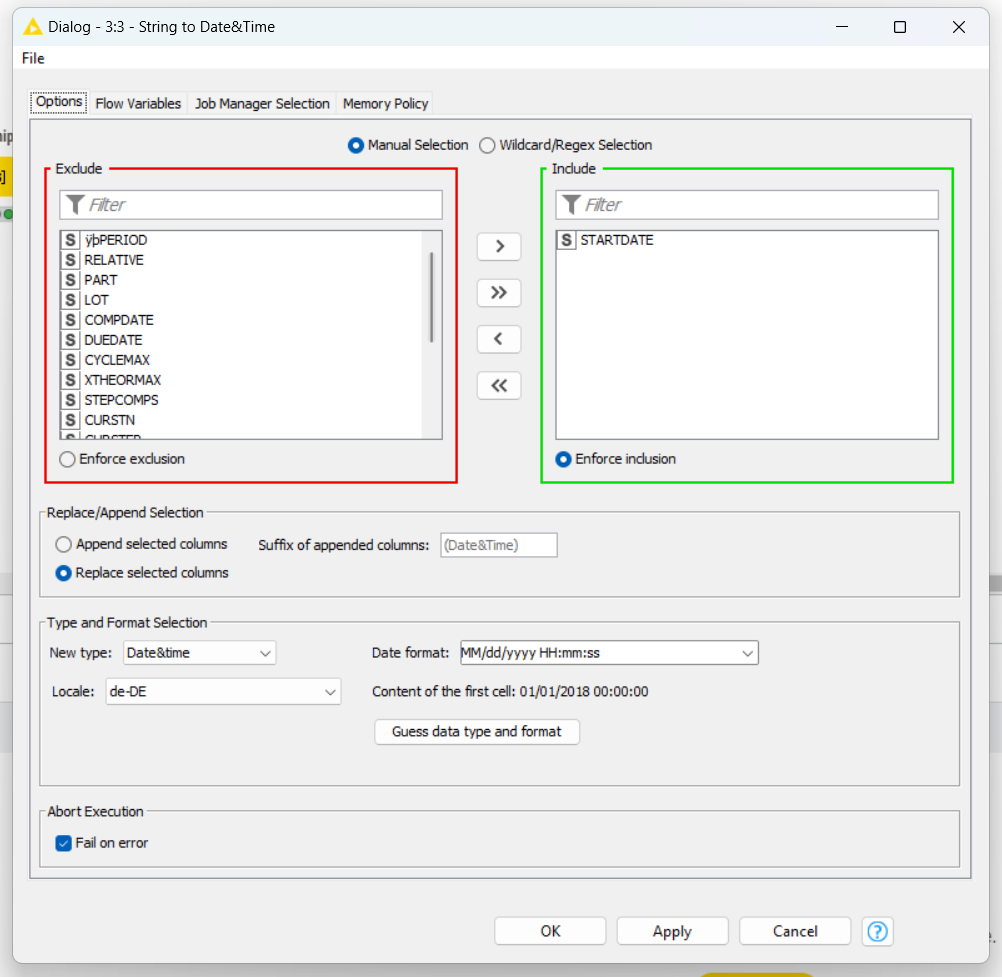
My data comes from a .txt-Document, I use the File Reader Node to autodetect the format. Now I would like to parse the columns STARTDATE, COMPDATE and DUEDATE to Datetime-Type. The columns are formatted “MM/dd/yyyy HH:mm:ss”, which is also the way I configured the String to Date&Time-Node.
For better readability I only show one column in the example screenshots
The Problem
When executing the Sting to Date&Time-Node I get a parsing-error.
Error Message
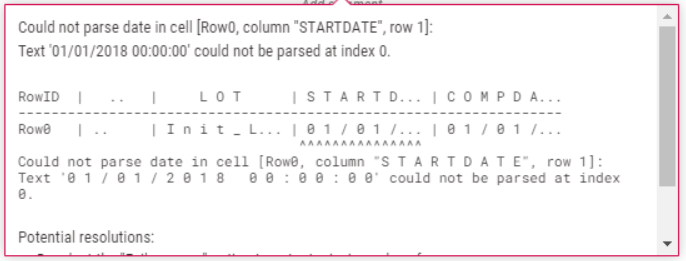
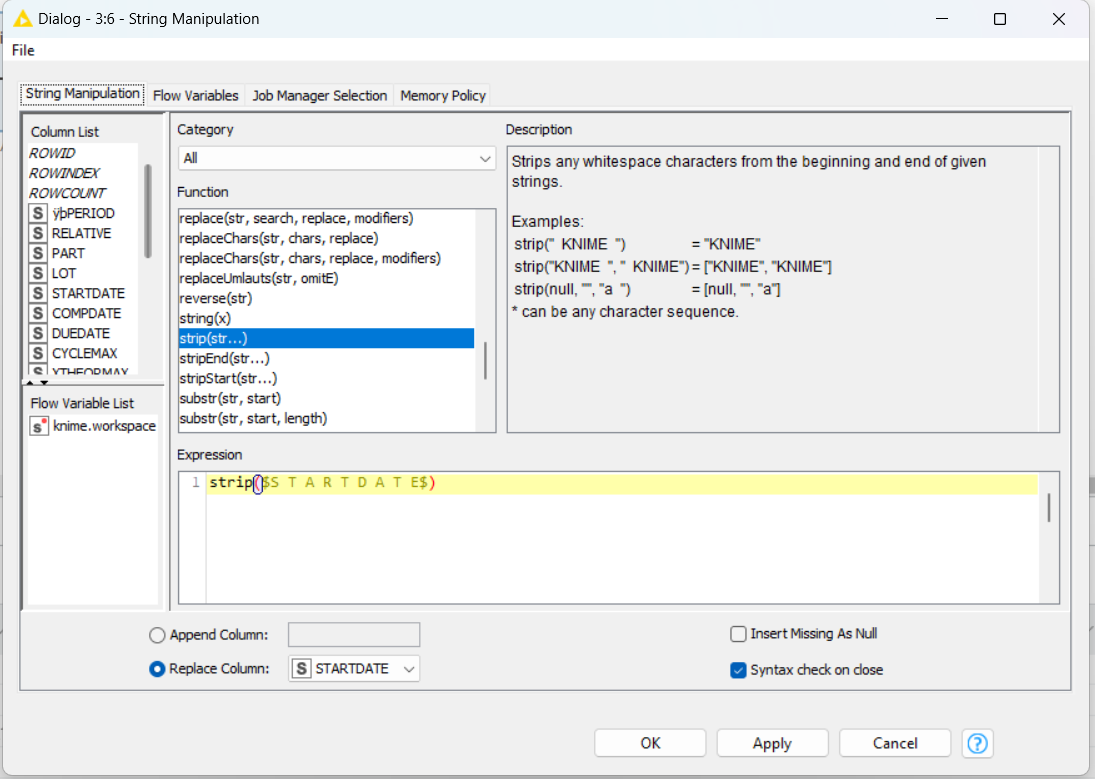
Taking a close look at the message it appears, that there is a leading-whitespace in the STARTDATE-Column. So I included a String Manipulation-Node to remove it as following:
As per description the strip(x) command removes leading and trailing whitespaces. But the error-massage stays as is, still implying a leading whitespac.
At this point I don’t know what else to do? Looking at the File Reader I cant see any whitespaces in the first place. Any suggestions on how to resolve this?
Hi @inirem , it looks to me like your data has been read in using the wrong character encoding, hence the “double spacing” of your columns and also the message.
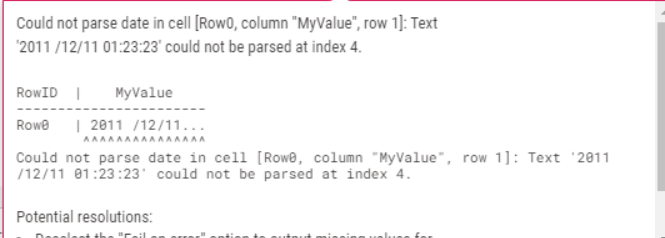
Ordinarily you’d expect the message to show in this form, without the additional spacing between characters:
The only time I’ve seen this occurring is if the data had been read from file using the wrong encoding. Given that you are reading it from a txt file, this sounds like the likely problem.
On the File Reader node, go to the encoding tab, and try a different encoding to see if you can resolve the problem. Do you know what is being used to write the original txt file, and what encoding it is using?
If you are able to, can you upload a sample of your text file. If it isn’t encoding, and somehow some double-spacing has been introduced, it may possible to pre-process and transform the file data so that it is corrected for processing.
Actually: I just noticed, that my previous explanation was wrong. While some of the files I will have to work with are .txt-format, this particular one is a .rep (Simulation Report File) - which anyway, opened with for example Visual Studio Code, looks just the other .txt files. Basically a table-structure made with whitespaces. When opened with Excel, it automatically recognizes the columns.
Sadly the documentation of the data does not contain any information about the used encoding. The File Reader Node automatically detected “Other” and filled it with the alue “windows-1252” which sounds strange to me, since this is the same as the “OS default”-option.
As I just noticed, I am not allowed to upload .rep files. SO: I tried converting it into an .txt file for uploading. Therefore I opened the file with an simple notepad and saved it as .txt and kept the (choosen by default) encoding UTF-16LE. Of course I had to try reading the Data with knime, which now worked just fine.