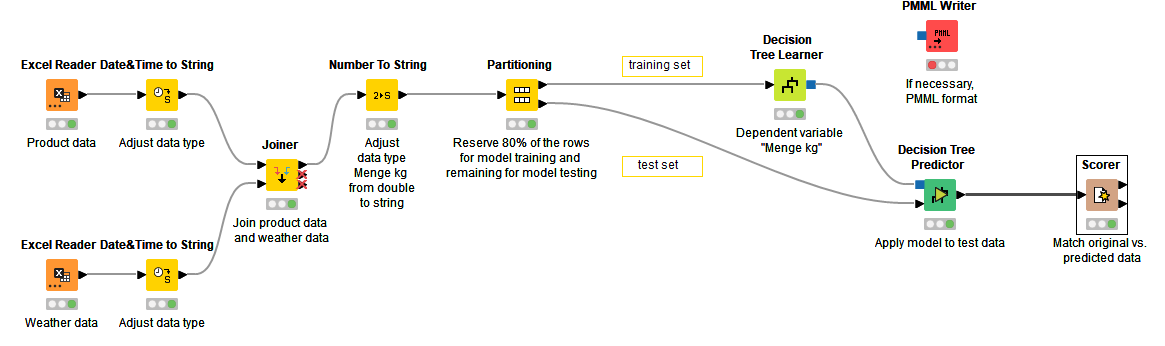
At the moment I’m trying my hand at an adaptive model for predicting sales of certain products.
For my current approach I followed the churn prediciton example.
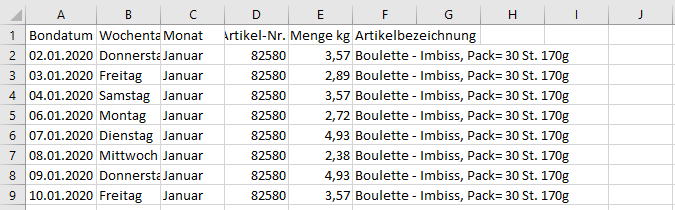
Based on product sales (food) and weather data, predictions are to be made. For example, one can assume that more barbecue is bought if the weather is good, etc. .
I have tried to implement this in the workflow.
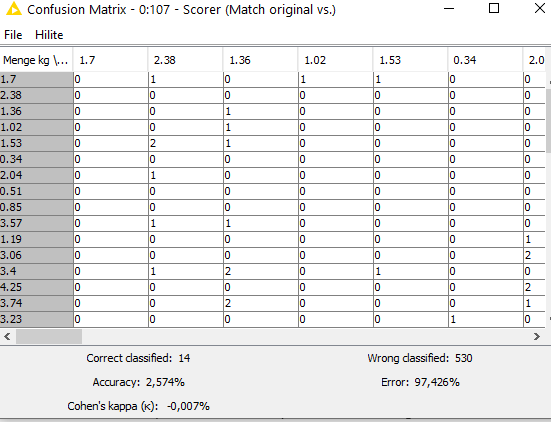
The workflow works so far, but with a very low accuracy.
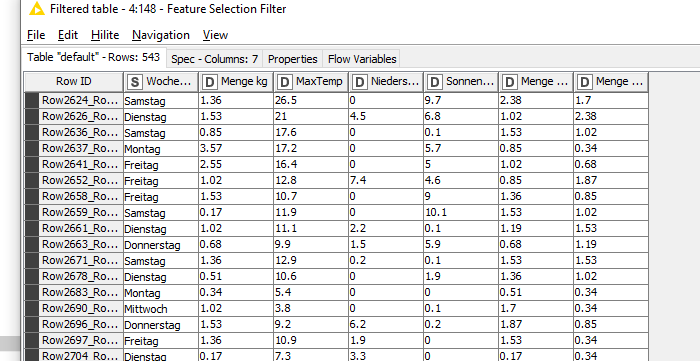
I have a maximum of 2,700 entries for the individual products.
Is this number sufficient to train the Decision Tree Learner sufficiently?
In the Knime courses I always worked with ~30,000 rows of entries.
Or could it be due to my configurations? I have already tried a few things, but never get above 3% accuracy.
Does anyone have any ideas what I could be tweaking?
Or is the task simply not possible due to the small number of entries in the data sets?
could you share your workflow and data?
And is this really a classification problem or more a regression problem (what do you try to predict? How much or if a product is bought?)
ok than i see your problem. You want to forecast the amount => a regression problem. But you use a classification learner.
Replace the Decision Tree Learner an Predictor with something like “Simple Regression Tree Learner” and convert the numeric columns to double.
To elaborate with a classification learner you try predict the exact amount (or example 2,89) and when the predict is 2,88 its a misclassification. But normally you would not care for the exact amount but a mount near the truth. So a regression would predict 2,88 an the absolute error would be 0,01 (what would be quite good).
If you share the excels as well it would be easier to help.
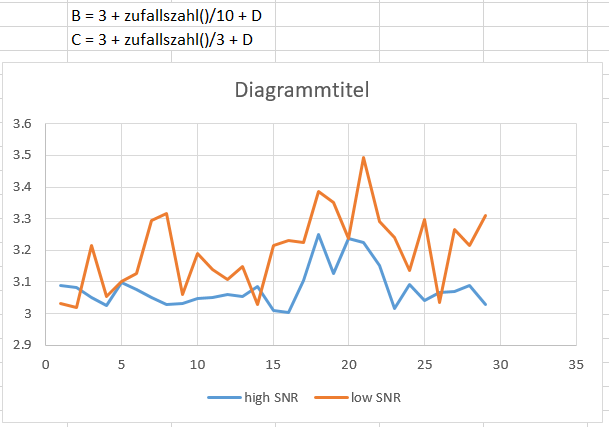
Noise is when there’s a lot of random fluctuations relative to your useful signal or “Wenn das Signal stark rauscht”. Maybe this screenshot makes it clearer: Both lines are at value 3 with some noise and a small bump around x-value 20. The bump is distinct in the blue line, but it’s difficult to tell whether there is something in the orange line. Could be the random noise. Blue noise is 0.1, orange ist 0.33.
i did some tweaking and build a (very) simple working model.
I did 3 Versions.
Frist version just a simple regression learner: Mean Absolut Error: 1,863 kg
Second version, gradient boosted decision tree, with same data: 1,318 kg
Third version, lag the kg amount for the 3 last entries because these features seam impotantant: 0,943
So you can extend that and can bring the number a lot lower.
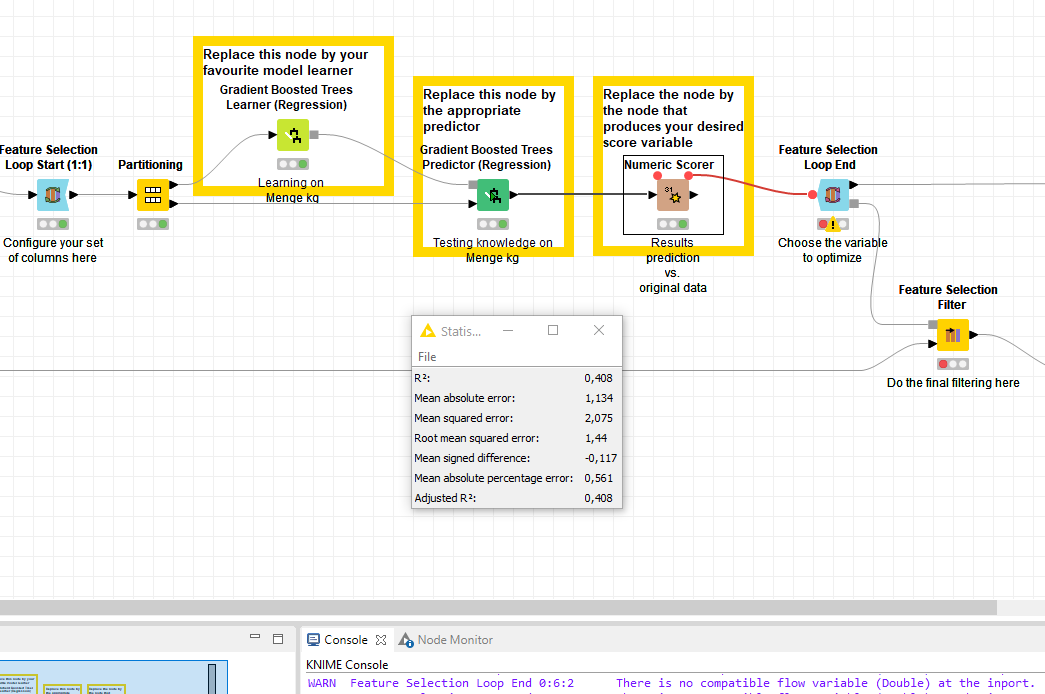
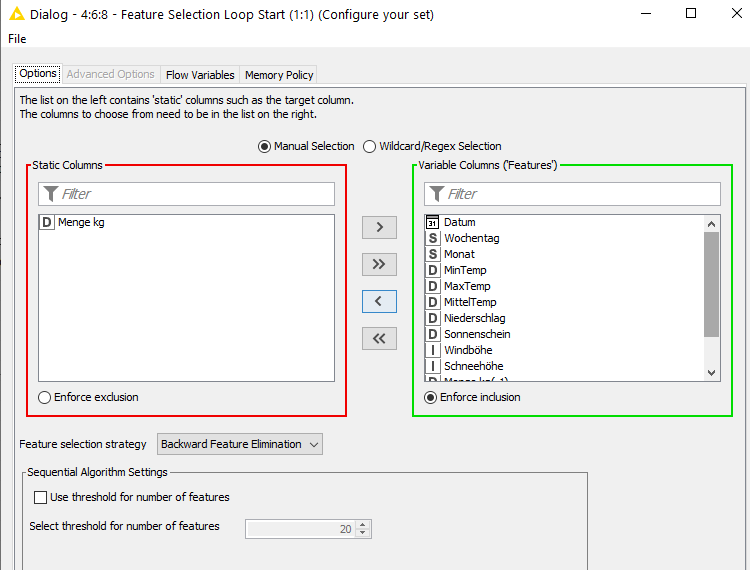
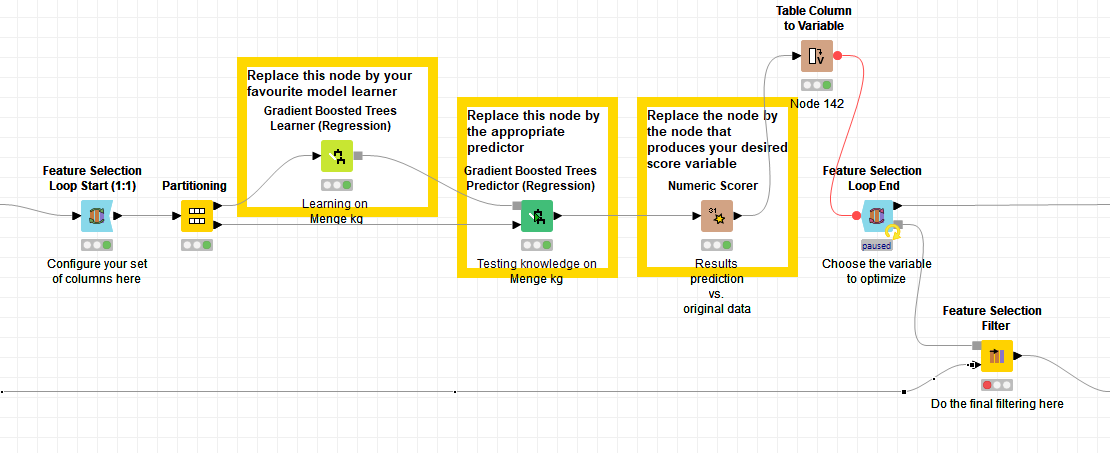
I am currently trying to learn how to use the Feature Selection Node, but I am getting stuck on the Feature Selection Loop End with the Error message: “There is no compatible flow variable (Double) at the inport.”
The Scorer results are in the data output, and not in the flow output. You need to insert a Table Column to Variable Node between the Scorer and the Feature Selection Loop End to get the results as Flow Variables.
The workflow seems to work, even though the error message is still a bit sketchy.
Not sure how well I can implement the Lag Node into the sales prediction though.
Aren’t the predictions unusable, if I derive them from artificially created data columns?
Isn’t lag creating new data rows with shifts to the previous row equal to the interval n?
No the predictions are usable. You often create additional features from your data.
You can lag the columns if there is a relation between the current row an the previous ones. In this case it is, because when the customers buy’s a lot of a product on previous day the don’t need as much on the present day. When there is no relation then the ml algorithm will ignore these columns.
One thing to note: you can only use lag, when there is an order (for example time) in your data and the intervals are the same (if not you have to do some more work). Also in real life applications, it is important if the information of previous rows is available (a problem in some streaming scenarios).
@Skiplegday I just took a look at the workflow. The message is only a warning, it’s safe to ignore it. It pops after every iteration because no flow variable of the right type exists when the Loop End is reset. Everything is fine once the Table Column to Variable Node creates the variables.
Longer version:
Some information about table structure and Flow Variables is available to the downstream nodes. This info is passed through not-executed nodes. The reason for this is probably performance, but it also let’s us configure most nodes even though the preceeding nodes aren’t executed.
However, there’re limits to this. In some scenarios, KNIME can’t guess a priori which columns and variables to expect, like in your Feature Selection Loop.
Upon loop reset, no variable “mean absolute error” exists, and the Loop End is unable to infer that the Column to Flow Variable will take care of that, so it throws the Warning. By the thyme it’s the Loop Ends turn, the variable exists and it executes.
To prove this and make the message disappear, you can create a double variable “mean absolute error” upstream of the Loop Start. The Loop End then knows that the variable it requires will definitely exist and shuts up. Variable scope takes care that the loop procedure is not affected.