I am working on a workflow to do ligand based virtual screening and trying out different machine learning nodes.
I am currently trying to incorporate the SVM learner/predictor in a binary classification problem with active/inactive compounds as target labels. I have defined the target classes so that molecules with IC50 values >100 nM are inactive (negative class) and <100 nM are active (positive class).
I am using 9 molecular descriptors calculated from the “RDKit desriptor calculation”-node:
(NumRotableBonds, NumHeavyAtoms, Chi0v, Kappa3, Smr_VSA9, Peoe_VSA10, MQN5, MQN10, MQN21)
The prediction output classifies only true and false positives for the inactive molecules and only true and false negatives for active molecule. This does not make sense to me, why can’t it identify any TP’s and FP’s for the active class?
Off hand I don’t know why this is happening - I rarely use SVMs myself in favor of tree-based classification methods. I was able to recreate this problem using a completely different dataset though, trying out multiple kernels.
I asked one of our other data scientists and he mentioned he had run into this issue with the SVM Learner on occasion as well.
Is it possible for you to upload your workflow and dataset - assuming it’s not proprietary - that reproduces the problem? If so, I can create a ticket for our devs to investigate further.
@Soren_Therkel you might want try and convert your input variables to numeric columns and maybe normalize them. Also you might want to try and balance the target. If the target is highly unbalanced you might run into additional problems.
Thank you for the reply. I have attached my workflow and part of my data. I use an sdf-file as well to calculate my descriptors, but unfortunately i cannot attach it here due to the format…
Interestingly, the model does not show the same behaviour when i change the weights of the target class. When i change the cutoff to 500 nM, the exact opposite happens and all compounds are labeled as actives. When the cutoff is 300 nM I get a mixture, but the accuracy for the positive class is worse than random classification.
Can you also upload the SDF file here? You can just change the extension to csv to avoid the forum upload restriction. And if that still doesn’t work, can you email it to me at [redacted for spam bots]?
Thanks for sending the file. It’s still not clear to me why the SVM performs so poorly. I’m able to replicate the results on your dataset so it’s definitely not just you. That said, is there a reason why you need to use SVM for this task?
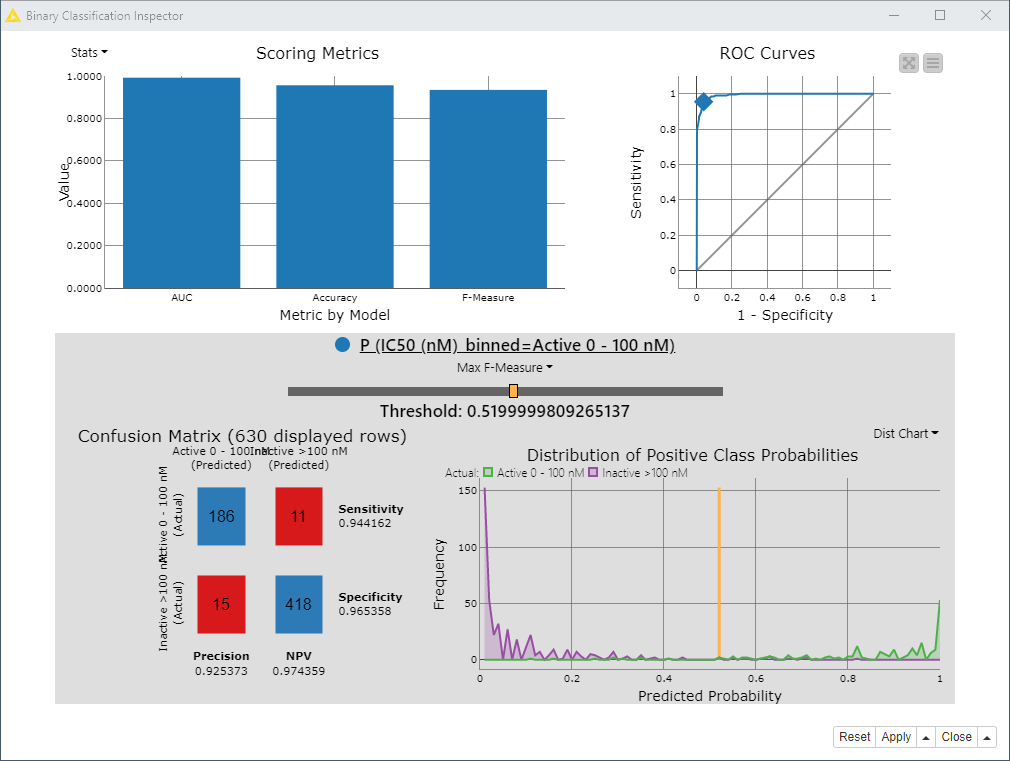
If I use a Random Forest Learner instead with default inputs, no feature selection or cross validation included, I get very high values for AUC, accuracy and F-measure in the Binary Classification Inspector using the nine descriptors you specify above:
In fact I would say this is suspiciously high; there might be some data leakage going on. But at any rate this gives you a way to actively adjust the threshold and see how things change.
None of this addresses your initial issue with SVM, but I thought it worth pointing out. I’ll ask internally to see if I can find out what else might be going on.
You could leave the initial nodes in executed state and save the WF without resetting it. So we would have the input data (and can store them ourself).
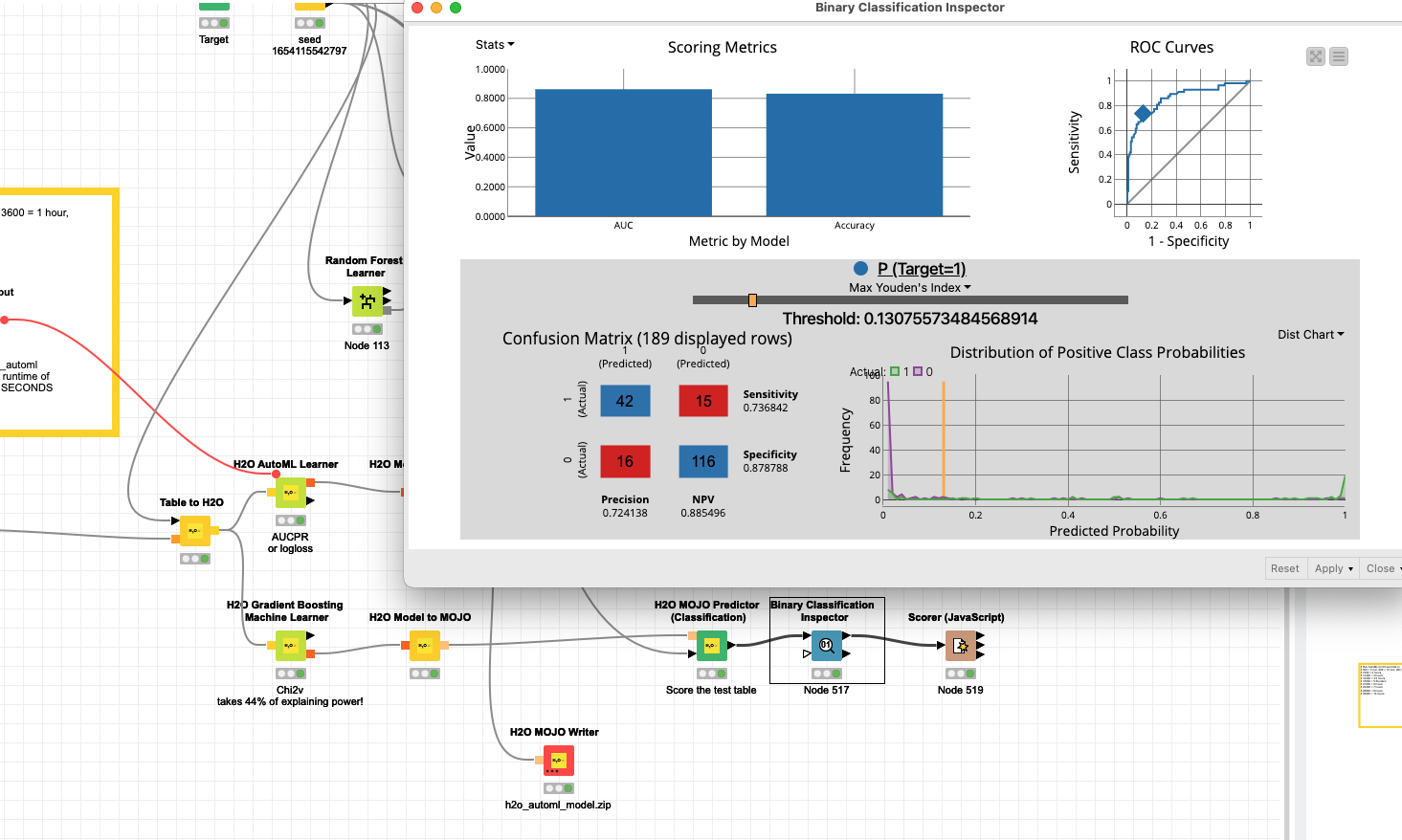
@ScottF it is indeed a mystery. SVM and also XGBoost seem to get ‘thrown off’ and would give nearly all test data roughly the same score which makes the model useless. Random Forstest and H2O.ai AutoML (5 minutes training resulting in GBM) are just doing fine and giving a good estimation. Currently I have no idea what is going on.
Thanks a lot for trying it out. No, there is no need for me to use the SVM, but I am trying to compare different models in my project, so I was curious to why it behaved in the way it does. I will probably use the random forrest in my final model.
@Soren_Therkel I have uploaded the complete job with the provided data so one could take a look.
Note. When using H2O.ai GBM the variable Chi2v takes 44% of explaining power! You might want to investigate that.