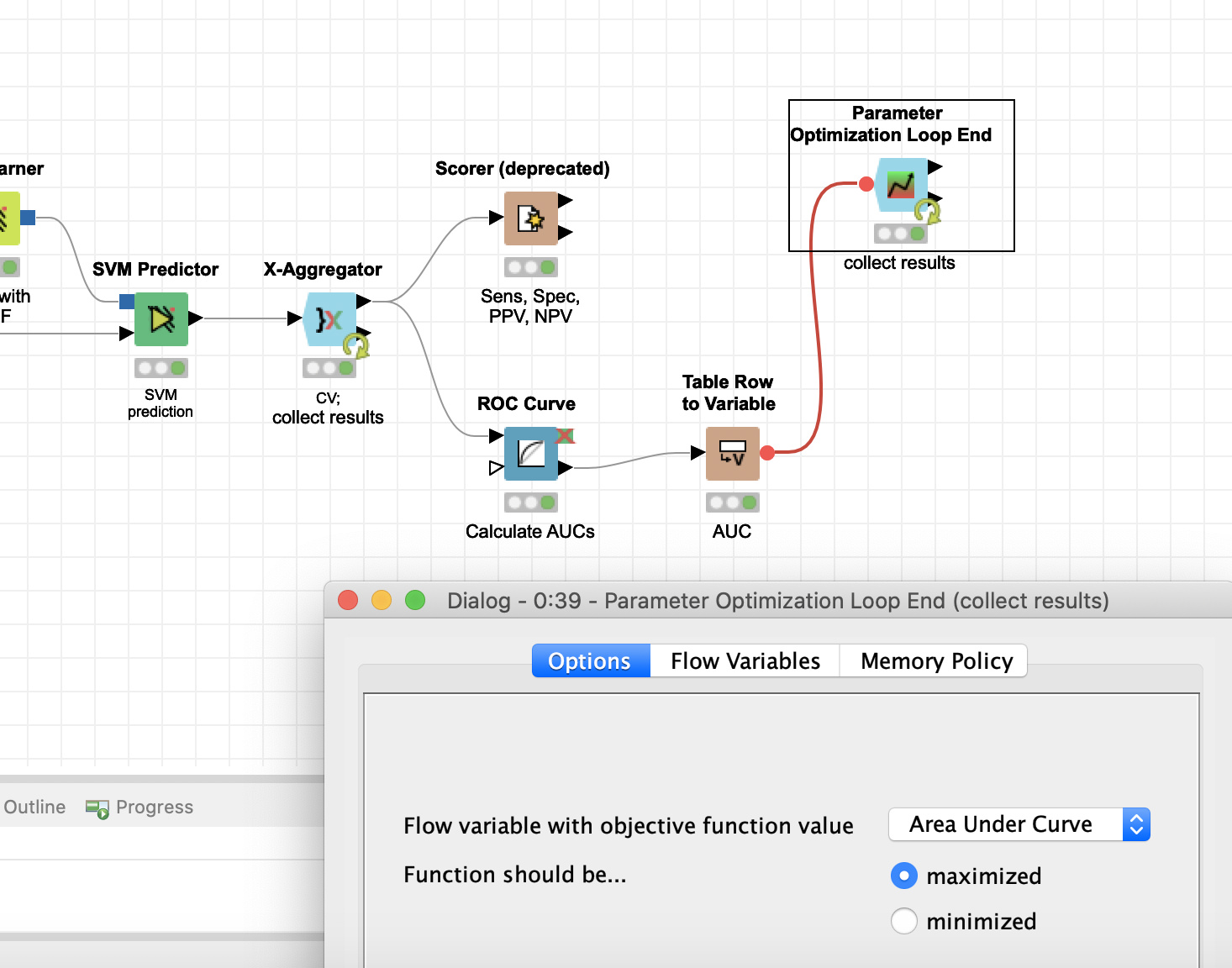
I am using a SVM for classification. There are 2 classes, C and M. C is the reference and I want to predict M. I have 205 samples and 367 predictors (all continuous), so the dataset is not very large but it is high-dimensional. I normalized the predictors, filtered variables with a correlation > |0.80|, I used 10-fold cross-validation with stratified sampling and a loop to optimize the sigma parameter. The workflow is attached; I cannot append data because the file is too large.
My problem is that the model makes exactly the same predictions for all obervations and the AUC is below 0.50. Obviously I am doing something wrong, but it is not obvious to me. Any suggestions?
Without and idea about the data it is very difficult to say what is going on. Could you provide us with a sample. And have you tried other methods besides SVM?
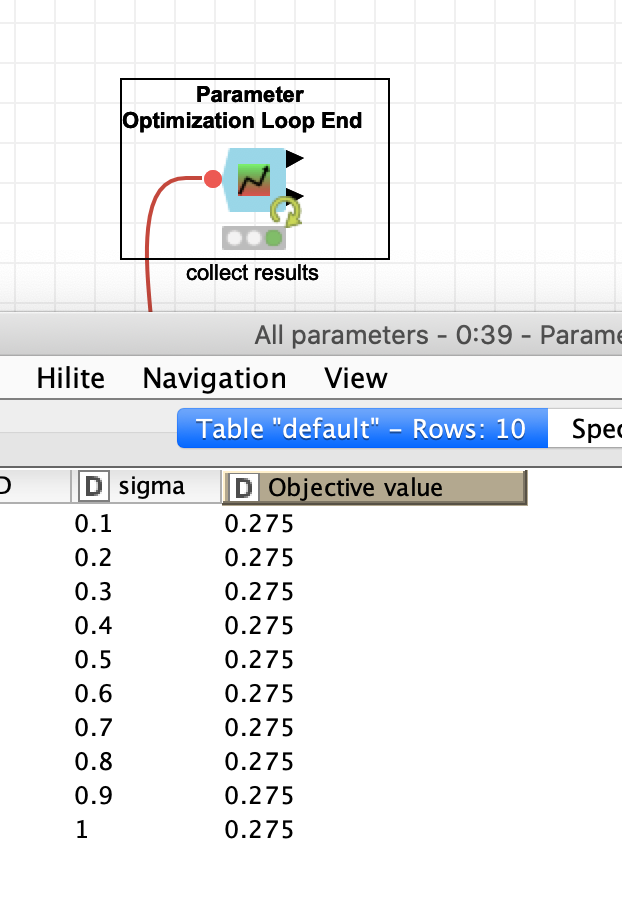
From a quick inspection one thing you would have to change is the variable you would want to max- or minimize. In your case it was either the flow variable knime.workflow (which makes no sense at all) or the sigma, so it would be sort of self referential.
You would have to use the AUC value. Although in your small sample the sigma does not seem to make any difference (the AUC is always 0.275). Also I changed the sampling from stratified to random.
In general you might want to think about your approach of seemingly randomly throwing methods and optimisations at your data. You could try and see what and advanced auto-machine-learning framework could come up with regarding your problem.
I have prepared an article and a sample workflow for that:
If you want some ‘help’ with data preparation you could employ R vtreat package and see if this makes any difference. I also have a workflow for that:
Also you might want to think about what your data does mean.
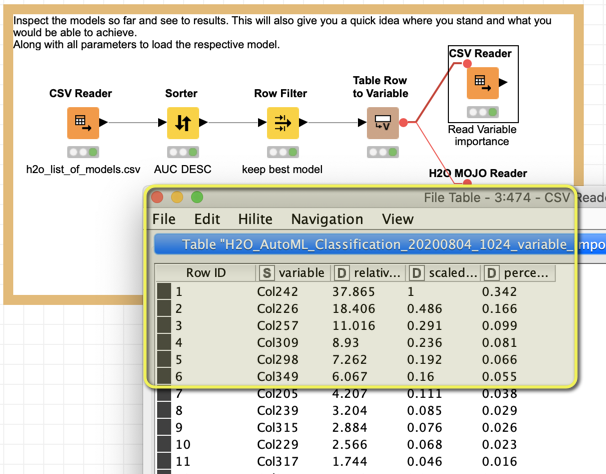
Just one additional remark. I threw your 150 lines into the Automl workflow and let it run for 5 minutes. Either with using vtreat or just ‘pure’ H2O.ai automl it came back with a perfect model (no idea how you selected the 150 lines).
This either means you have a brilliant model or (more likely) you have some sort of leak in your data that would spell the beans on the result (C or M).
You would want to carefully study the list of important variables where a few Col… take most of the explaining power. These would be the ones to carefully look at.
Here is the modified workflow. It would rely heavily on GBM although that might be due to the possible leak.
I agree with mlauber71. The data certainly has a leak or is not real data. With Random Forest 100% accuracy is trivially achieved with using 2 features only for each CV split. So if this is the actual data, you need to verify what it is and where it came from. For sure not usable to create any realistic model.
About the worklflow posted. What is immediately apparent is the fact you are doing the feature selection before the CV split. This is wrong. You need to do the feature selection for each CV split and each split can have different features! In fact this is part of your model and doing it outside of CV will leak information. That is why the Normalizer (Apply) Node is used for. You normalize on training data and apply that normalization model on the test data.
As for SVM, personally opinion but I really don’t like them. Mostly need tuning and still perform worse than RF. It’s the bad parts of xgboost (tuning) without the good parts (best performance).
Thank you very much for your suggestions. The idea to use SVM with a RBF kernel was to check an algorithm that explores “curved” borders for separation between categories. Additionally, I am using logistic regression with LASSO for interpretability and RF to check for interactions. Also, I am new to KNIME and I am using a Windows system, so I will need a little time to pause and read carefully the H2O.aiAutoML workflow. On the other hand, the perfect prediction obtained with H2O as compared with the poor performance of SVM are difficult to grasp, so these results need to be checked carefully.
Thank you very much for your comments. The approach you propose (including feature selection in the CV) is also stated in “Feature engineering and selection” by Max Kuhn (CRC Press, 2019), but I am brand new to KNIME and I have never seen an example of this approach. Do you know of any worlflow where this is actually implemented?
Can’t speak for example workflows hence why you should take those with a grain of salt.
I suggest to create some components that handle this. I do have such but would probably need permission to share and they would need some work to “generalize” which isn’t fun work at all.
In fact a big issue with sharing components openly on say KNIME Hub is “default values”. For example if I initially generated a component that has an option to select the class column and the class column has an obvious name that reveals for what a model was built, this initial value is stored in the component and visible to anyone using that component. So before sharing all these possible leaks need to be checked and eliminated. At least that’s how it works on the server. haven’t tried with KNIME Hub but suppose it’s the same. In fact it would be great (if it isn’t the case) that Components uploaded to KNIME Hub automatically forget these initial settings.
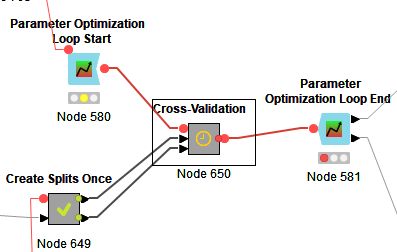
As a hint to increase performance, especially for parameter optimization, I create the CV splits and feature selection once and “store it”, where “store it” means a loop-end with 2 ports, 1 with selected features per split and one with all the data + an additional “split id” column. that way the split + feature selection does not have to be repeated for every single parameter optimization loop which is increases performance a lot.
The Cross-validation then simply is a Group Loop start on the “split id” column + some reference row and reference column “magic”.
The H2O.ai example would also work on a Windows platform (it might just be that H2O.ai’s XGBoost implementation is not available there - yet). You would have to install R and H2O in R and then point KNIME towards it.
Maybe you try to use a Random Forest or boosted Tree to see if something similar comes up.
Thank you @mlauber71. I think I also need to spend more time on EDA to understand the data and eventually looking for possible errors from the data source.