From a quick inspection one thing you would have to change is the variable you would want to max- or minimize. In your case it was either the flow variable knime.workflow (which makes no sense at all) or the sigma, so it would be sort of self referential.
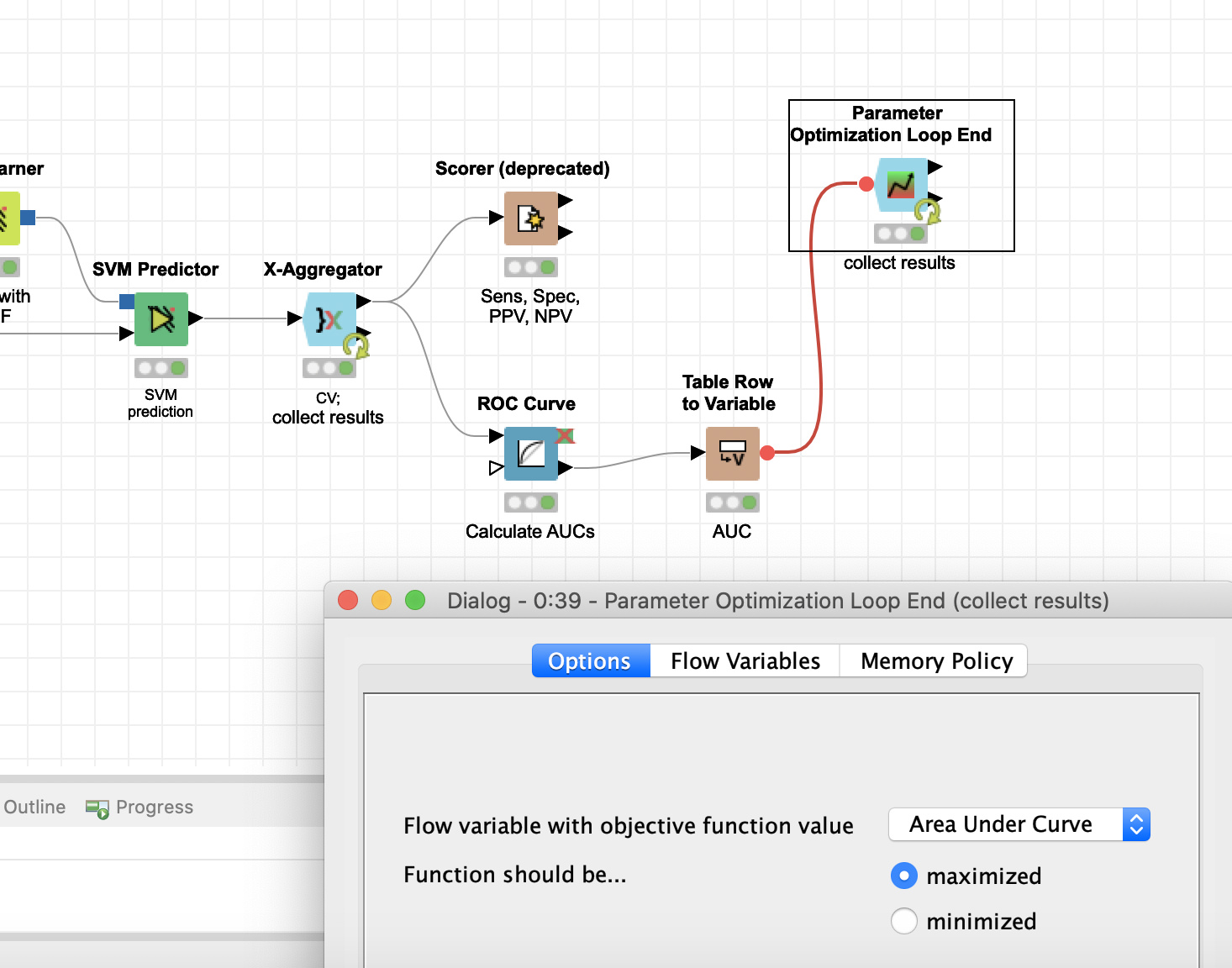
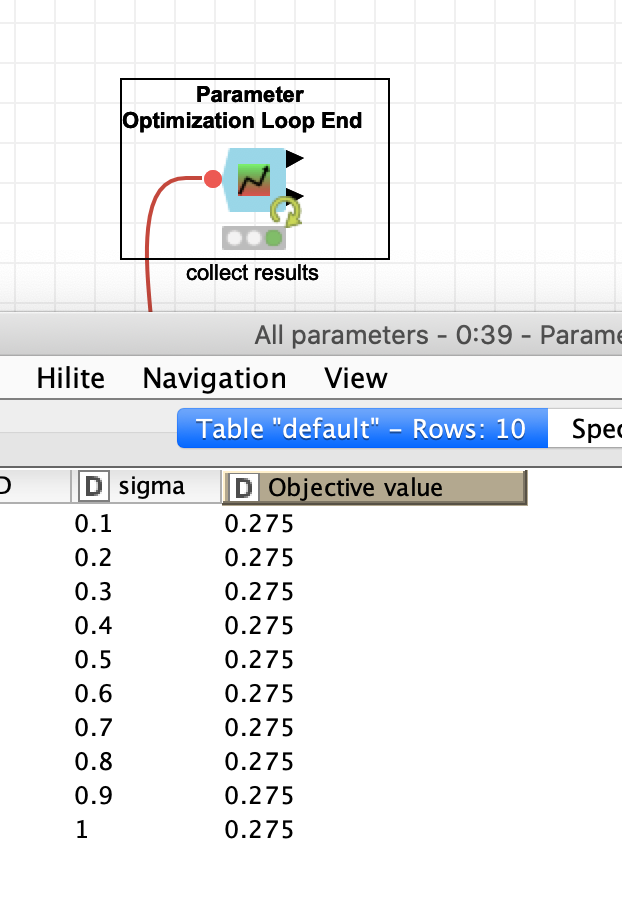
You would have to use the AUC value. Although in your small sample the sigma does not seem to make any difference (the AUC is always 0.275). Also I changed the sampling from stratified to random.
In general you might want to think about your approach of seemingly randomly throwing methods and optimisations at your data. You could try and see what and advanced auto-machine-learning framework could come up with regarding your problem.
I have prepared an article and a sample workflow for that:
If you want some ‘help’ with data preparation you could employ R vtreat package and see if this makes any difference. I also have a workflow for that:
Also you might want to think about what your data does mean.
Z_SVM example_2.knwf (938.5 KB)