Just one additional remark. I threw your 150 lines into the Automl workflow and let it run for 5 minutes. Either with using vtreat or just ‘pure’ H2O.ai automl it came back with a perfect model (no idea how you selected the 150 lines).
This either means you have a brilliant model or (more likely) you have some sort of leak in your data that would spell the beans on the result (C or M).
You would want to carefully study the list of important variables where a few Col… take most of the explaining power. These would be the ones to carefully look at.
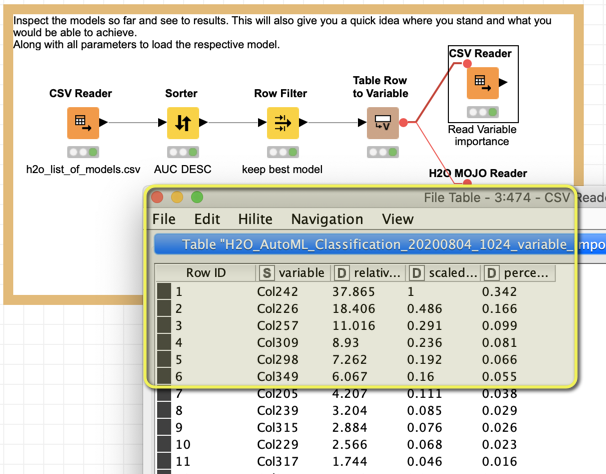
Here is the modified workflow. It would rely heavily on GBM although that might be due to the possible leak.