Maybe I am at the wrong place and maybe it is a none-issue because there is this option I am going to propose. Please bear with me.
I recently used the Table Difference Finder. While I feel the spec works fine, I terribly miss the option to give the value comparison the possibility (mandatory?) to take into account key fields preferably by variable.
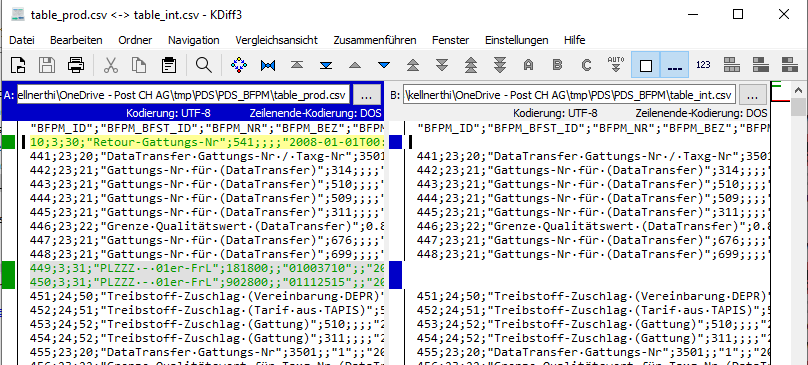
For instance, if I compare the content of following two tables (csv representations), KDiff3 gives
This huge and to my eyes useless difference representation is because the difference finding algorithm does not take into account any key columns such that after the first additinal/missing line one gets but differences everywhere.
Hi @Thiemo.Kellner
If the hurdle of using Table Difference Finder, it is the unpaired rows of your tables. You can rearrange the right table (your IDs are matching) , with a left outer join of the ID column, just before sending the table to the node.
Afterwards you can blank easily the differences from missing rows with rule engine.
Hey @gonhaddock , your suggestion will not exactly do what the difference finder or any diff applications (such as KDiff3 that @Thiemo.Kellner used) do.
Using left (or right) join will only compare the matching keys (in your case you are mentioning IDs), and you can of course identify which records with these IDs are missing from the left table (or the right table if you do a right join).
A diff will actually compare the whole record.
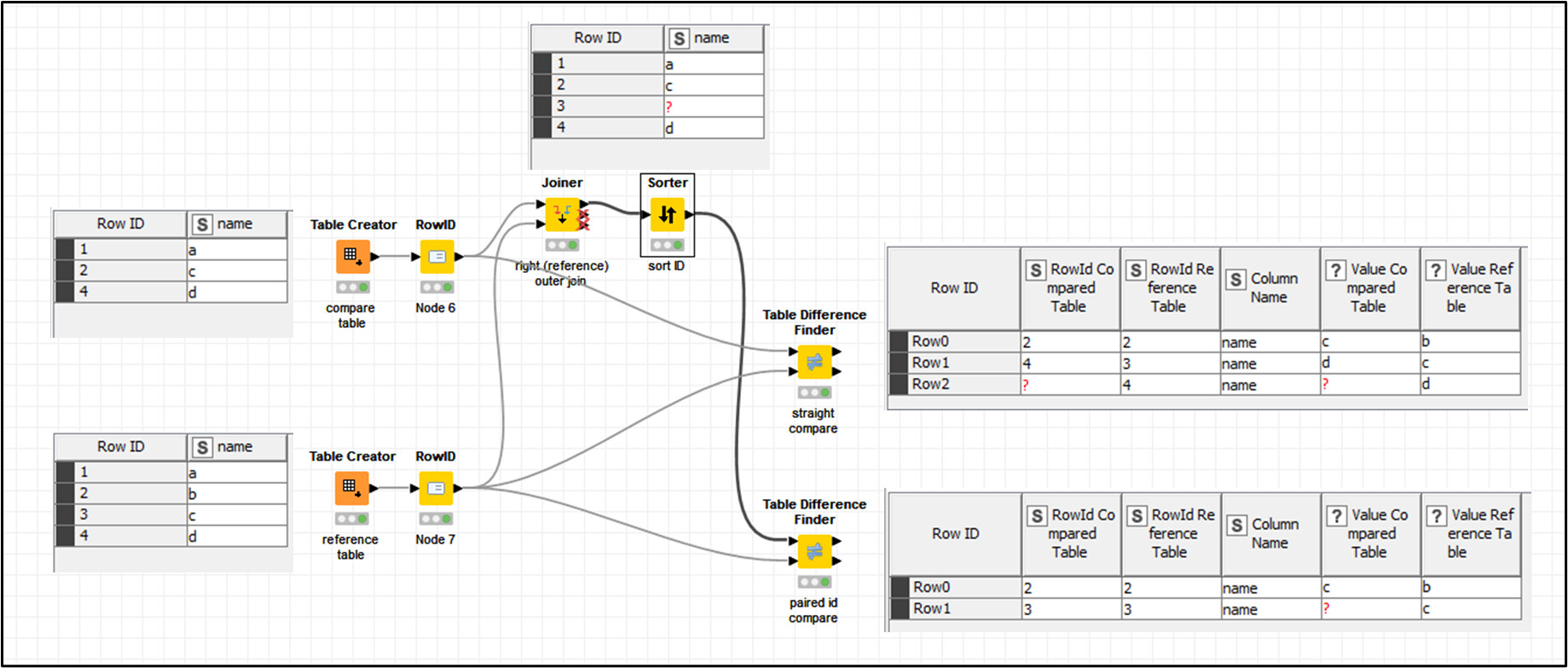
For example, if we have this dataset:
Table A:
+----+------+
| ID | name |
+----+------+
| 1 | a |
| 2 | b |
+----+------+
Table B:
+----+------+
| ID | name |
+----+------+
| 1 | a |
| 2 | c |
+----+------+
With your approach, you will not get any “missing rows” as both IDs 1 and 2 exist in both tables. But a diff will tell you that the row with ID 2 is different in both tables.
I know some other users might reply to this saying “we can also compare the name field”, well that is find if there’s only 1 additional field other than the ID field. But if you have 5, 6, 10, 20 fields?
In the end, this could still work for @Thiemo.Kellner if he’s looking to identify which records are missing from the tables (he might have been using the KDiff3 for that purpose as the sample he showed were cases of missing records, rather than records being different)
As far as I have understood @gonhaddock correctly, the joining is only to put ghost/dummy records of the missing keys into the original data set such that the diff node afterwards can compare the data sets without the shift mess.
It is quite an effort to make. One has to mark those ghost records to distiguish them from records genuinly empty but the key. Maybe not a case often found, but one one rather should not ignore.
Hi @Thiemo.Kellner , indeed, I thought about that right after I shut down my computer on that night, but I figured I’ll let @gonhaddock reply and confirm
But you are absolutely correct that this would be a workaround to “fix” the issue of the missing records when doing the difference finder that you raised.
Ideally, it should be fixed in the node itself. +1 for me for this feature request.
Hello @bruno29a and thanks for bringing me back to the topic.
Maybe I didn’t realized on #feature-reques tag at that time, so I just double fall into the fact that some previous work ‘can be done’ (i said), ‘is required’ @Thiemo.Kellner said…
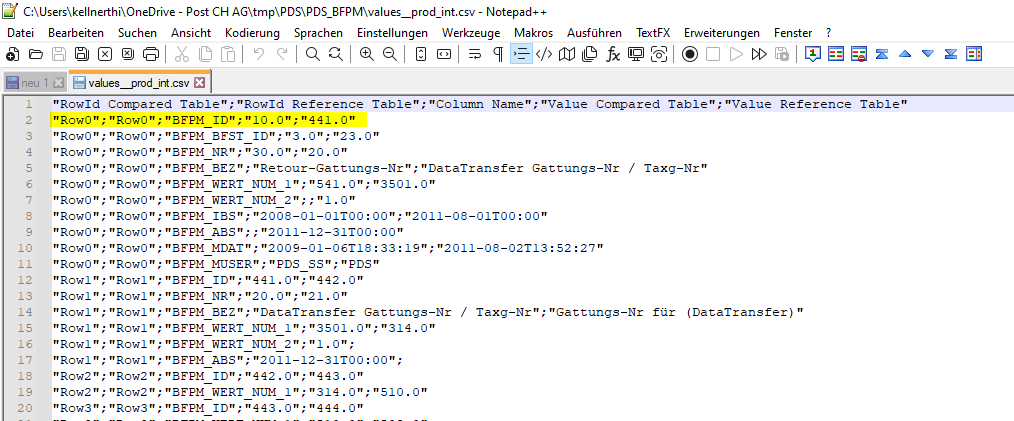
Just prepared an example for this post showing that: without some data preparation work, the result is just hard to use. In the example, the compare table has just two differences: 1 content + 1 missed row.