Hi all,
Hoping for some help please.
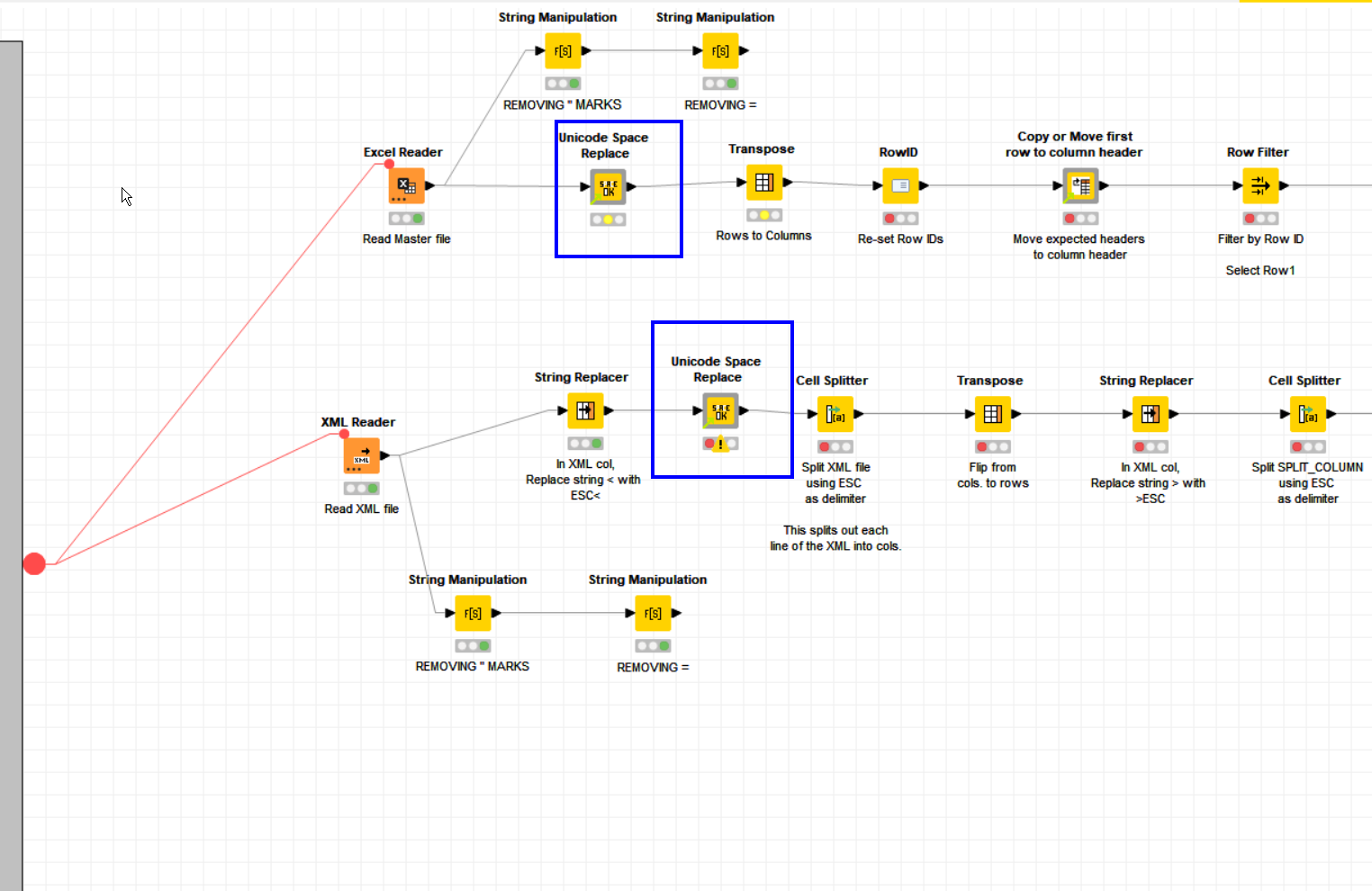
I’ve got two files that i’ve read in to KNIME - one is an XLSX file and the other is an XML file - I want to check the differences between the two files.
I am using the Table Difference Finder node and in the output, KNIME is telling me that select column names in my two data sets do not match - please can someone check what I have done below and advise if there is something i have missed?
-
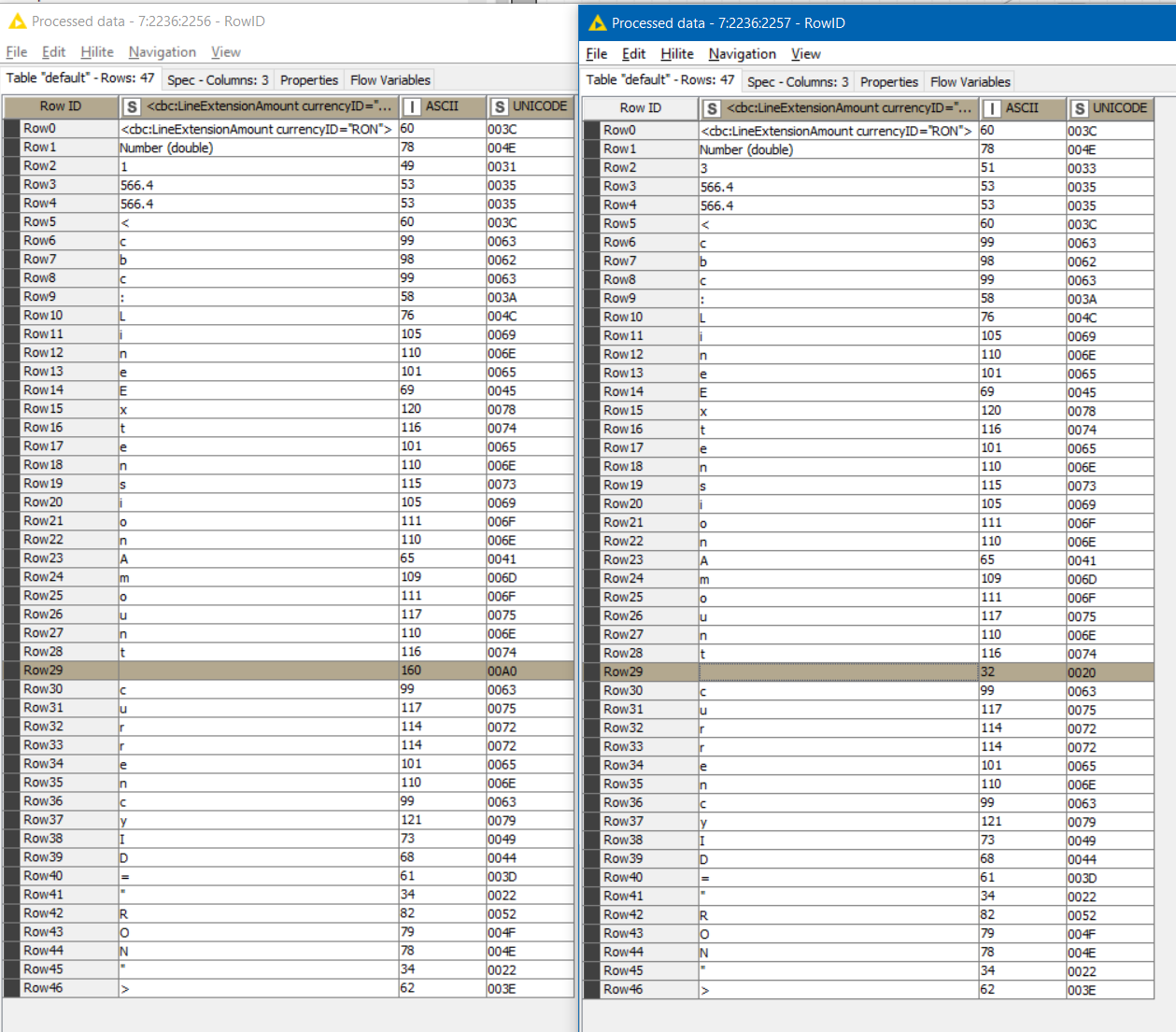
Below you can see the output for my two datasets.
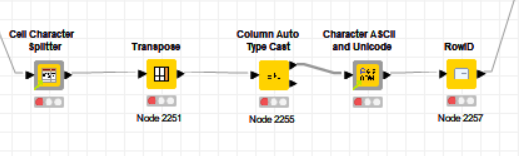
I’ve formatted the XML data into columns to enable the use of Table Difference Finder.
To me, the columns headers look the same so I am not sure why its finding differences. -
Interestingly, all columns that didn’t have " marks in them to begin with are matched correctly in the comparison.

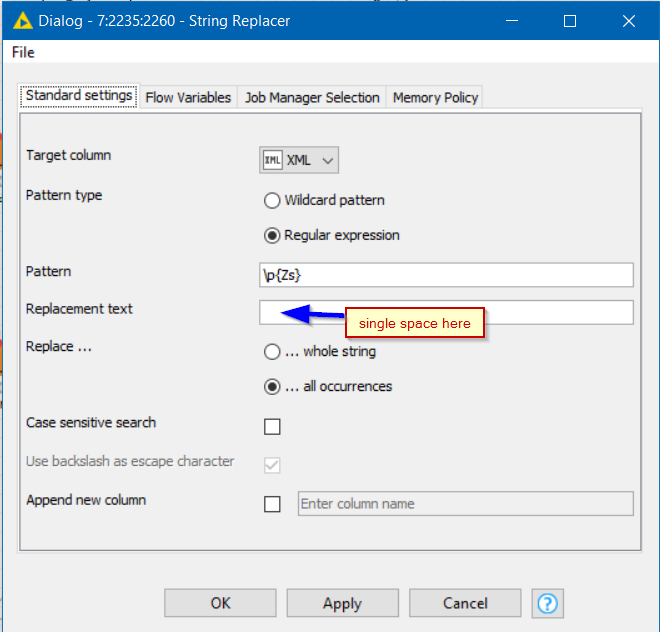
As you can see below, i’ve tried removing the " marks from the Column Name but a difference is still found.

When I say a difference, I mean that the columns from the separate sources are not being matched correctly for comparison.
3)I’ve tried removing white spaces from both column headers (none found) and i’ve also checked the length of both column headers (see below screenshot) - the length in both cases is 34 characters.
I think this screenshot shows best that the two column names appear to be 100% the same.
Please can anyone advise what I am missing here? Why is KNIME recognising these columns as having separate names?
Thanks in advance.
tp