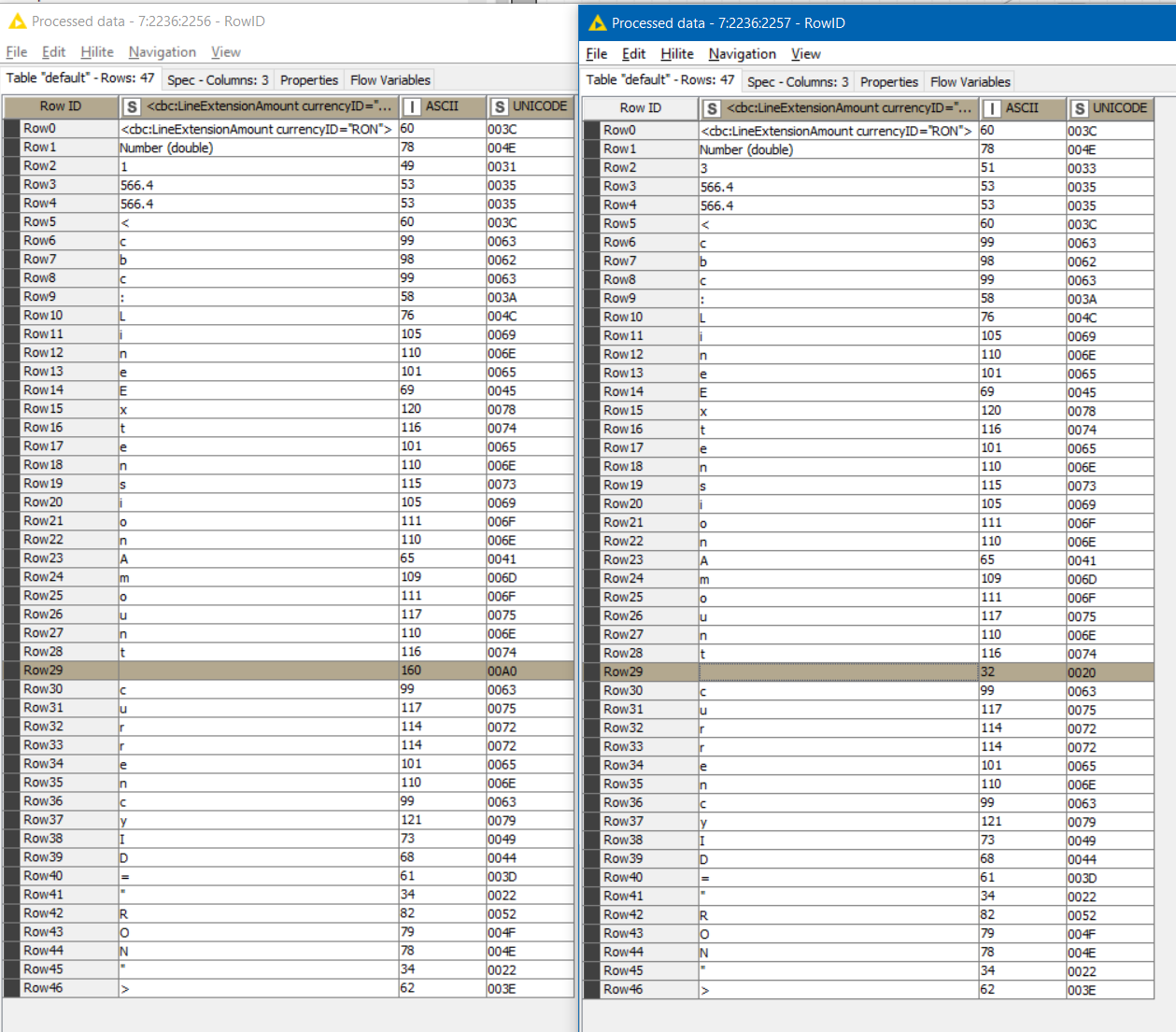
OK, @taylorpeter55 , you have a Unicode non-breaking space character \u00A0 in one of the outputs at the point where you have a regular space (Unicode \u0020) in the other. I suspect this is there courtesy of Excel.
This is between the words “Amount” and “Currency”. You can read the text downwards in the first column in each table.
From the workflow, it looks like you are still on KNIME 4.7. There is a String Cleaner node in KNIME 5.2 but I don’t think that would help here, because you actually want to convert these into regular spaces rather than strip them out completely otherwise the column names still wouldn’t match.
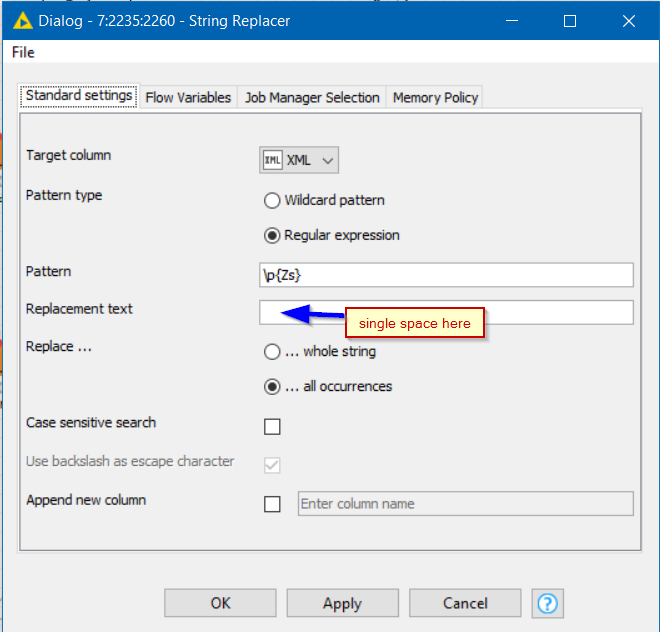
You can resolve this using String Replacer with the following config with the following regular expression to find all “space” characters
\p{Zs}
(put a single space in “Replacement Text”)
and I would suggest doing this both for your XML column and the empty_a column, just to be on the safe side.
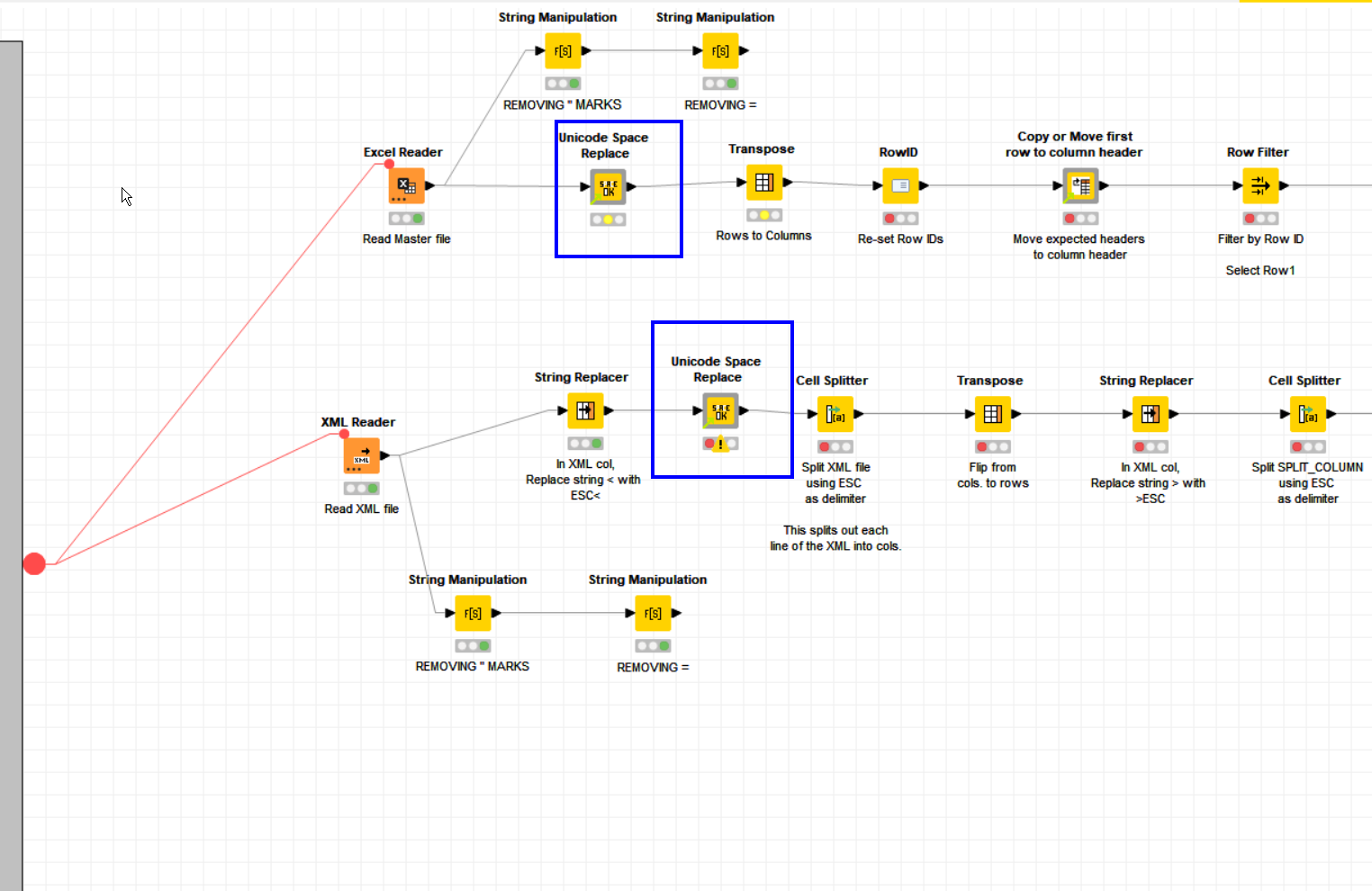
That’s all a bit of a faff, so I have wrapped the String Replacer into a component called Unicode Space Replace so you can make use of that instead if you wish:
Place this (or String Replacer) in the workflow as shown here:
If you are interested in how I found the set of character codes for each item, this was done with a another couple of components:
Filter out a SINGLE row of data to be inspected (it gets horrible if you try to apply this to more than a single row!) and string the two components as follows:
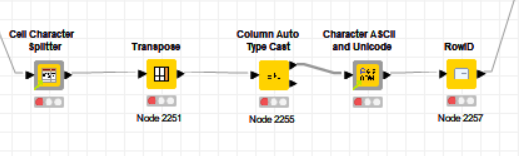
Configure the Cell Character Splitter to split the column of interest into individual characters (one column per character), then transpose gives one character per row. Column Auto Type Cast makes it a String in case it has become “undetermined type”, and then the Character ASCII and Unicode component is configured to inspect the required column.
This will give you the ASCII and UNICODE for each character in the String.